



![]()
As organizations increasingly adopt cloud analytics and big data solutions, the demand for Azure Data Engineers continues to rise across industries. Microsoft Azure remains one of the fastest-growing cloud platforms, and companies are actively hiring professionals skilled in Azure Data Factory, Synapse Analytics, Databricks, SQL, and cloud-based data engineering solutions.
If you’re preparing for an Azure data engineer interview, understanding the most commonly asked azure data engineer interview questions can help you stand out in a competitive job market. In this guide, you’ll find carefully selected interview questions and answers covering Azure Data Engineering concepts, analytics, storage, Azure Data Factory (ADF), and real-world implementation scenarios frequently discussed during technical interviews.
Whether you are a beginner, an experienced professional, or preparing for the DP-203 certification exam, these interview questions and answers will help strengthen your technical knowledge and improve your interview preparation. Let’s explore the top Azure Data Engineer interview questions that can help you prepare with confidence.
To download the complete DP-203 Azure Data Engineer Associate Exam Questions guide click here.
General Azure Data Engineer Interview Questions
Preparing for Azure data engineer interviews requires more than memorizing definitions. Interviewers often evaluate both conceptual understanding and practical problem-solving skills. The following azure data engineer interview questions are organized by difficulty level to help beginners, intermediate professionals, and experienced candidates prepare more effectively.
These general azure interview questions cover important concepts related to Azure services, ETL processes, data storage, security, and real-world data engineering scenarios.
Beginner Level Azure Data Engineer Questions
1) What is Microsoft Azure?
Difficulty Level: Beginner
Experience Level: Fresher
Answer:
Microsoft Azure is a cloud computing platform provided by Microsoft that offers services such as computing, storage, networking, analytics, databases, and AI. It allows organizations to build, deploy, and manage applications through Microsoft-managed data centers.
Tip:
Interviewers often expect candidates to explain Azure from both infrastructure and business perspectives, including scalability and pay-as-you-go pricing benefits.
2) What is the primary ETL service in Azure?
Difficulty Level: Beginner
Experience Level: Fresher
Answer:
Azure Data Factory (ADF) is the primary ETL and data integration service in Microsoft Azure. It enables users to create, schedule, and orchestrate data pipelines for extracting, transforming, and loading data across multiple data sources.
Practical Scenario:
A company may use Azure Data Factory to move daily sales data from on-premises SQL Servers into Azure Data Lake for analytics processing.
Azure Synapse Analytics Interview Questions
This section covers some of the most commonly asked azure synapse interview questions for Azure Data Engineer roles. These azure synapse analytics interview questions include both theoretical and practical scenarios frequently discussed during technical interviews.
Beginner Level Synapse Interview Questions
6) Which Azure service is commonly used for enterprise Data Warehousing?
Difficulty Level: Beginner
Experience Level: Fresher
Answer:
Azure Synapse Analytics is commonly used for enterprise data warehousing in Azure. It combines big data analytics, data integration, and data warehousing capabilities into a single platform.
Tip:
Interviewers may expect you to mention both serverless and dedicated SQL pool capabilities in Azure Synapse Analytics.
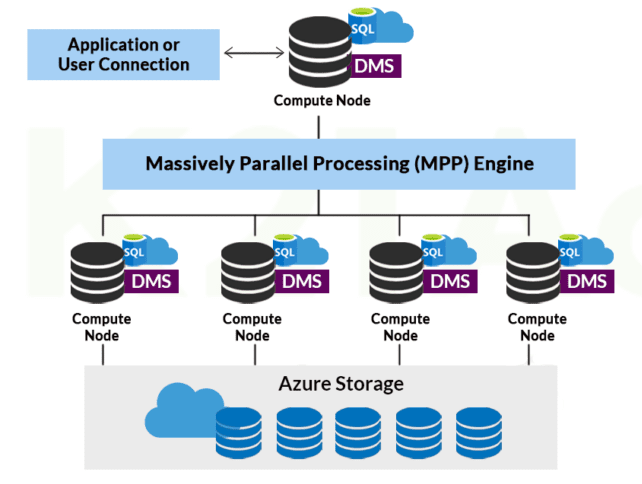
7) What is Azure Synapse Analytics architecture?
Difficulty Level: Beginner to Intermediate
Experience Level: 1–2 Years
Answer:
Azure Synapse Analytics uses a Massively Parallel Processing (MPP) architecture to process large-scale data efficiently. Queries are received by a control node, divided into smaller tasks, and distributed across multiple compute nodes for parallel execution.
Practical Scenario:
This architecture helps organizations process billions of records quickly for enterprise reporting and analytics workloads.
Tip:
Mentioning MPP architecture is important because it directly impacts query performance and scalability.
Intermediate Level Azure Synapse Analytics Interview Questions
8) What is the difference between ADLS Gen2 and Azure Synapse Analytics?
Difficulty Level: Intermediate
Experience Level: 2+ Years
| ADLS Gen2 | Azure Synapse Analytics |
|
|
|
|
|
|
|
|
|
|
|
|
Practical Scenario:
Organizations often store raw data in ADLS Gen2 and use Azure Synapse Analytics for transformations, reporting, and querying.
9) What are Dedicated SQL Pools in Azure Synapse Analytics?
Difficulty Level: Intermediate
Experience Level: 2+ Years
Answer:
Dedicated SQL Pools are provisioned data warehousing resources within Azure Synapse Analytics designed for high-performance analytics workloads. They use columnar storage and distributed query processing to improve performance for large-scale enterprise reporting.
Read More: Dedicated SQL Pool
Tip:
Interviewers may ask when to choose Dedicated SQL Pools over Serverless SQL Pools. Mention predictable workloads and performance optimization.
Advanced Azure Synapse Interview Questions
10) How do you process streaming data in Azure?
Difficulty Level: Advanced
Experience Level: 3+ Years
Answer:
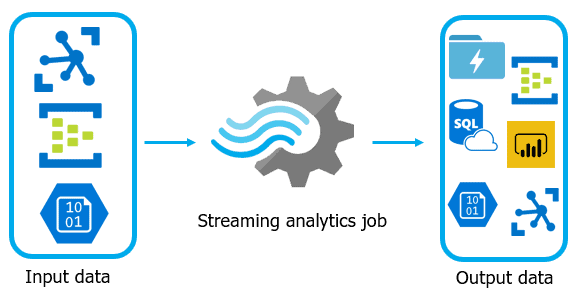
Azure Stream Analytics is commonly used to process real-time streaming data in Azure. It uses a SQL-like query language to analyze streaming events from sources such as IoT devices, Event Hubs, and Kafka.
Practical Scenario:
A logistics company may process real-time GPS tracking data from delivery vehicles using Azure Stream Analytics dashboards.
Tip:
Mention low-latency processing and real-time analytics capabilities during interviews.
11) What are windowing functions in Azure Stream Analytics?
Difficulty Level: Advanced
Experience Level: 3+ Years
Answer:
Windowing functions in Azure Stream Analytics are used to group streaming events over specific time intervals for aggregation and analysis.
Types of Windowing Functions:
- Tumbling Window: Fixed non-overlapping intervals
- Hopping Window: Overlapping intervals
- Sliding Window: Updates when new events arrive
- Session Window: Groups events based on activity sessions
Practical Scenario:
Sliding windows are commonly used in fraud detection systems where continuous event monitoring is required.
Tip:
Interviewers often ask real-world use cases for windowing functions, so explain where each type is practically useful.
Azure Data Engineering Interview Questions – Storage
This section covers some of the most important azure storage interview questions, azure data lake interview questions, and cosmos db interview questions frequently asked in Azure Data Engineer interviews. These questions include both conceptual and practical scenarios to help candidates prepare for real-world discussions.
Beginner Level Azure Storage Interview Questions
12) What are the different types of storage services available in Azure?
Difficulty Level: Beginner
Experience Level: Fresher
Answer:

Azure provides multiple storage services designed for different workloads:
- Azure Blob Storage – Stores unstructured data such as images, videos, and documents
- Azure Queue Storage – Supports message-based communication between applications
- Azure File Storage – Managed file shares using SMB protocol
- Azure Disk Storage – Persistent storage for Azure Virtual Machines
- Azure Table Storage – NoSQL key-value storage for structured data
Tip:
Interviewers may ask which storage service should be used for specific workloads, so focus on real-world use cases.
13) What is Azure Storage Explorer and why is it used?
Difficulty Level: Beginner
Experience Level: Fresher
Answer:
Azure Storage Explorer is a cross-platform tool used to manage Azure storage resources such as Blob Storage, ADLS Gen2, Tables, Queues, and Cosmos DB through a graphical interface.
Practical Scenario:
Data engineers commonly use Azure Storage Explorer to upload files, monitor containers, and manage cloud storage during development and testing.
Intermediate Level Azure Data Lake Interview Questions
14) What is Azure Table Storage?
Difficulty Level: Intermediate
Experience Level: 2+ Years
Answer:
Azure Table Storage is a NoSQL key-value data store designed for storing large amounts of structured, non-relational data.
Important Properties:
- PartitionKey – Defines data partition
- RowKey – Uniquely identifies records within a partition
- Timestamp – Tracks modification time
Tip:
Interviewers often compare Azure Table Storage with Cosmos DB, so understand scalability and querying differences.
15) What is data redundancy in Azure Storage?
Difficulty Level: Intermediate
Experience Level: 2+ Years
Answer:
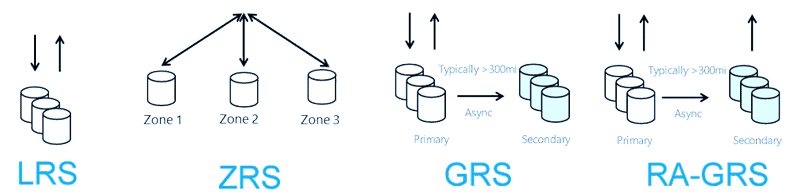
Azure Storage uses redundancy mechanisms to ensure high availability and disaster recovery.
Common Redundancy Options:
| Redundancy Type | Description |
|---|---|
| LRS | Replicates data within a single data center |
| ZRS | Replicates data across availability zones |
| GRS | Replicates data to a secondary region |
| RA-GRS | Provides read access to secondary region |
Practical Scenario:
Organizations using mission-critical applications often choose GRS or RA-GRS for disaster recovery planning.
16) What are the best ways to ingest on-premises data into Azure?
Difficulty Level: Intermediate
Experience Level: 2+ Years
Answer:
Azure supports multiple methods for transferring on-premises data depending on data size, frequency, and network bandwidth.
Common Options:
- Azure Data Factory
- AzCopy
- Azure Data Box
- Azure Storage Explorer
- Azure CLI and PowerShell
Practical Scenario:
For large one-time migrations, organizations often use Azure Data Box instead of network-based transfer methods.

Azure Data Factory Interview Questions
This section covers some of the most important azure data factory interview questions frequently asked in Azure Data Engineer interviews. These ADF interview questions include both theoretical concepts and practical implementation scenarios commonly discussed during technical interviews.
Beginner Level ADF Interview Questions
25) What are pipelines and activities in Azure Data Factory?
Difficulty Level: Beginner
Experience Level: Fresher
Answer:
In Azure Data Factory (ADF), a pipeline is a logical grouping of activities that work together to perform a specific task. Activities are the individual processing steps inside the pipeline.
Types of Activities in ADF:
- Data Movement Activities – Move data between source and destination systems
- Data Transformation Activities – Transform and process data
- Control Activities – Control pipeline execution flow and conditions
Practical Scenario:
A pipeline may extract sales data from SQL Server, transform it using Databricks, and load it into Azure Data Lake.
Tip:
Interviewers often ask real-world pipeline design questions, so explain orchestration and workflow automation clearly.
26) How do you manually execute an Azure Data Factory pipeline?
Difficulty Level: Beginner
Experience Level: Fresher to Intermediate
Answer:
ADF pipelines can be triggered manually, programmatically, or automatically. Manual execution can be done through the Azure portal, PowerShell, or REST APIs.
PowerShell Example:
Invoke-AzDataFactoryV2Pipeline -DataFactory $df -PipelineName "DemoPipeline"
Practical Scenario:
Manual execution is commonly used during testing, debugging, or validation of new pipelines before production deployment.
Intermediate Level Azure Data Factory Interview Questions
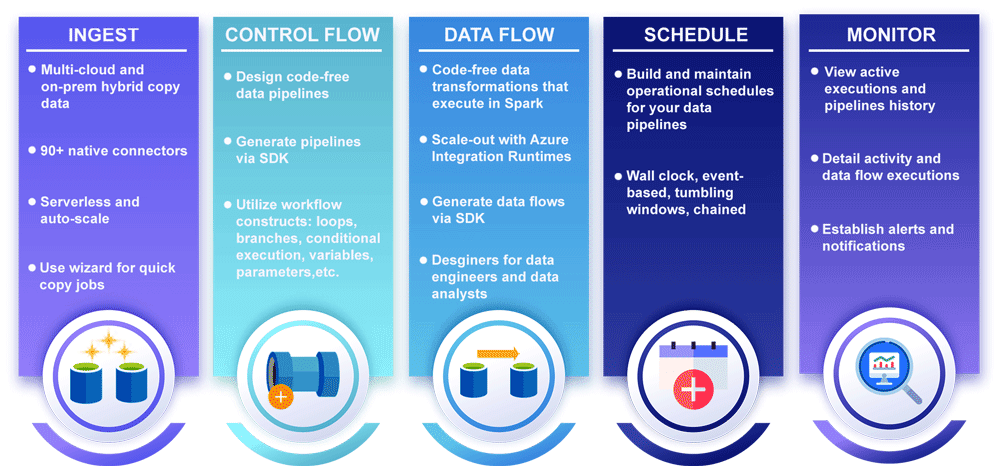
27) What is the difference between Control Flow and Data Flow in ADF?
Difficulty Level: Intermediate
Experience Level: 2+ Years
| Control Flow | Data Flow |
|---|---|
| Controls pipeline execution logic | Performs data transformation |
| Works at pipeline level | Works at activity level |
| Used for loops and conditions | Used for joins, filters, and transformations |
| No source/sink required | Requires source and sink datasets |
Answer:
Control Flow manages workflow execution logic, while Data Flow is responsible for transforming and processing data inside Azure Data Factory.
Practical Scenario:
A Control Flow activity may trigger a loop, while a Data Flow activity performs customer data cleansing and transformations.
Tip:
Interviewers frequently test whether candidates understand orchestration vs transformation responsibilities.
28) What are partitioning schemes in Azure Data Factory Data Flows?
Difficulty Level: Intermediate
Experience Level: 2+ Years
Answer:
Partitioning schemes in ADF optimize performance by distributing data processing across multiple partitions.
Common Partitioning Schemes:
- Round Robin – Evenly distributes data
- Hash Partitioning – Uses hash values for grouping similar data
- Dynamic Range – Automatically partitions data ranges
- Fixed Range – Uses predefined ranges
- Key Partitioning – Creates partitions based on unique values
Practical Scenario:
Hash partitioning is commonly used for large-scale joins to improve Spark transformation performance.
Tip:
Performance optimization questions are common in adf interview questions, especially for enterprise-scale pipelines.
Advanced Azure Data Factory Interview Questions
29) What are triggers in Azure Data Factory?
Difficulty Level: Advanced
Experience Level: 3+ Years
Answer:
Triggers in Azure Data Factory automate pipeline execution based on schedules, time windows, or events.
Types of Triggers:
- Schedule Trigger – Runs pipelines at fixed intervals
- Tumbling Window Trigger – Executes periodic non-overlapping runs
- Event-Based Trigger – Executes pipelines when events occur
Practical Scenario:
An event-based trigger may automatically process files whenever a new CSV file is uploaded into Azure Blob Storage.
Tip:
Interviewers often ask when Tumbling Window triggers are preferred over Schedule triggers for incremental processing.
30) What are Mapping Data Flows in Azure Data Factory?
Difficulty Level: Advanced
Experience Level: 3+ Years
Answer:
Mapping Data Flows are visually designed data transformation workflows in Azure Data Factory that allow users to transform data without writing code.
Key Benefits:
- No-code transformation design
- Spark-based execution engine
- Supports joins, filters, aggregations, and derived columns
- Integrates directly into ADF pipelines
Practical Scenario:
A company may use Mapping Data Flows to clean customer transaction data before loading it into Azure Synapse Analytics.
Tip:
Interviewers value understanding of when Mapping Data Flows should be used instead of external tools like Databricks or Spark notebooks.
Read More: Top 25 Azure Data Factory Questions
Azure Databricks Interview Questions
This section covers some of the most commonly asked azure databricks interview questions for Azure Data Engineer and Big Data roles. These databricks interview questions include Spark concepts, data processing scenarios, performance optimization, and real-world implementation discussions frequently asked during technical interviews.
Beginner Level Azure Databricks Interview Questions
31) What is Azure Databricks?
Difficulty Level: Beginner
Experience Level: Fresher
Answer:
Azure Databricks is a cloud-based analytics platform built on Apache Spark. It is designed for big data processing, machine learning, and scalable data engineering workloads within the Microsoft Azure ecosystem.
Practical Scenario:
Organizations use Azure Databricks to process large volumes of data stored in Azure Data Lake before loading analytics results into Azure Synapse Analytics or Power BI.
Tip:
Interviewers often expect candidates to explain the relationship between Apache Spark and Azure Databricks.
32) What are the main components of Azure Databricks?
Difficulty Level: Beginner
Experience Level: Fresher to Intermediate
Answer:
The main components of Azure Databricks include:
- Workspaces
- Clusters
- Notebooks
- Jobs
- Delta Lake
- Databricks Runtime
These components help developers build, execute, and manage scalable Spark workloads efficiently.
Tip:
Be prepared to explain how notebooks and clusters work together during data processing.
Intermediate Level Databricks Interview Questions
33) What is Apache Spark, and why is it used in Azure Databricks?
Difficulty Level: Intermediate
Experience Level: 2+ Years
Answer:
Apache Spark is a distributed data processing engine designed for high-performance analytics and large-scale data processing. Azure Databricks uses Spark to process massive datasets in parallel across multiple nodes.
Key Benefits of Spark:
- In-memory processing
- Fast distributed computation
- Scalability
- Support for batch and streaming workloads
Practical Scenario:
A retail company may use Spark in Azure Databricks to process millions of customer transactions daily for analytics and reporting.
Tip:
Interviewers often compare Spark with Hadoop, so understand Spark’s performance advantages.
34) What is Delta Lake in Azure Databricks?
Difficulty Level: Intermediate
Experience Level: 2+ Years
Answer:
Delta Lake is a storage layer in Azure Databricks that provides ACID transactions, schema enforcement, and reliable data processing on top of data lakes.
Key Features:
- ACID transaction support
- Time travel
- Schema evolution
- Improved data reliability
Practical Scenario:
Organizations use Delta Lake to maintain reliable and consistent analytics datasets even during concurrent data updates.
Tip:
Mentioning data consistency and pipeline reliability strengthens your answer in interviews.
Advanced Spark Interview Questions Azure
35) How do you optimize Spark jobs in Azure Databricks?
Difficulty Level: Advanced
Experience Level: 3+ Years
Answer:
Spark job optimization in Azure Databricks involves improving processing efficiency, reducing execution time, and managing cluster resources effectively.
Common Optimization Techniques:
- Partition tuning
- Caching frequently used data
- Using broadcast joins
- Avoiding data skew
- Optimizing cluster sizing
- Using Delta Lake optimizations
Practical Scenario:
A large ETL pipeline processing terabytes of IoT data may use partition optimization and caching to improve performance significantly.
Tip:
Performance optimization questions are very common in spark interview questions azure because enterprises handle massive-scale workloads.
36) What is the difference between cache() and persist() in Spark?
Difficulty Level: Advanced
Experience Level: 3+ Years
Answer:
Both cache() and persist() store intermediate Spark data for reuse, but persist() allows selecting different storage levels such as memory or disk, while cache() uses memory by default.
Practical Scenario:
Data engineers often use persist() when datasets are too large to fit completely into memory.
Tip:
Interviewers ask this question to test understanding of Spark memory management and optimization strategies.
37) How does Azure Databricks support real-time data processing?
Difficulty Level: Advanced
Experience Level: 4+ Years
Answer:
Azure Databricks supports real-time data processing using Spark Structured Streaming, which enables continuous processing of streaming data from sources such as Event Hubs, Kafka, and IoT devices.
Practical Scenario:
A financial organization may process live transaction streams in real time for fraud detection and monitoring.
Tip:
Mention low-latency processing and integration with Azure streaming services to strengthen your answer.
Scenario-Based Azure Data Engineer Interview Questions
Scenario-based interview questions are commonly asked in senior-level Azure Data Engineer interviews because they test practical problem-solving skills, architecture thinking, and real-world implementation experience. These azure data engineer scenario based interview questions help interviewers evaluate how candidates handle scalability, performance optimization, security, and enterprise data challenges.
1) How would you design a scalable ETL pipeline for processing terabytes of daily data?
In this scenario based interview question, interviewers expect candidates to explain scalable pipeline architecture using services such as Azure Data Factory, Azure Data Lake Storage Gen2, Azure Databricks, and Azure Synapse Analytics.
A strong answer should discuss:
- Incremental loading
- Parallel processing
- Partitioning strategies
- Monitoring and fault tolerance
Expected Outcome:
A properly optimized pipeline can reduce processing time by more than 50% for large-scale enterprise workloads.
2) How would you handle real-time streaming data from IoT devices?
This practical question evaluates knowledge of real-time analytics architectures in Azure.
A typical solution may include:
- Azure Event Hubs for ingestion
- Azure Stream Analytics or Databricks Structured Streaming for processing
- Power BI or Synapse Analytics for reporting
Enterprise Example:
A logistics company processing millions of GPS events daily may use this architecture for real-time fleet monitoring and route optimization.
3) What would you do if your Azure Data Factory pipeline starts failing intermittently?
This is one of the most common azure data engineer scenario based interview questions focused on troubleshooting.
Candidates should explain:
- Monitoring pipeline logs
- Using retry policies
- Validating source connectivity
- Implementing alerting with Azure Monitor
Expected Outcome:
Proper monitoring and retry mechanisms can significantly reduce production pipeline failures and downtime.
4) How would you optimize slow Spark jobs in Azure Databricks?
This scenario tests performance optimization skills.
A good answer should include:
- Partition optimization
- Broadcast joins
- Caching
- Cluster scaling
- Delta Lake optimization
Practical Impact:
Performance tuning can improve Spark execution speed dramatically while reducing cluster costs in enterprise analytics environments.
5) How would you secure sensitive enterprise data in Azure?
This practical question evaluates cloud security knowledge.
Candidates should mention:
- Azure Key Vault
- Managed Identities
- RBAC
- Encryption at rest and in transit
- Private Endpoints
Enterprise Example:
A healthcare organization handling patient records may implement multi-layered Azure security controls to meet compliance standards such as HIPAA.
6) How would you design a disaster recovery strategy for Azure data platforms?
Interviewers ask this scenario based interview question to evaluate business continuity planning skills.
A strong answer may include:
- Geo-redundant storage (GRS)
- Backup policies
- Cross-region replication
- Automated failover strategies
Expected Outcome:
Well-designed disaster recovery architectures help organizations maintain high availability and minimize data loss during outages.
Emerging Scenario-Use Cases in Azure Data Engineering
Modern interviews are increasingly covering:
- AI-powered analytics pipelines
- Real-time streaming architectures
- Lakehouse implementations
- Multi-cloud data integration
- Data governance and compliance automation
As Azure data platforms continue evolving, scenario-based and practical questions are becoming more important than theoretical interview preparation alone.
FAQs
Q1. What are Azure Data Engineer interview questions?
Azure data engineer interview questions are technical and scenario-based questions asked during interviews for Azure Data Engineering roles. These interview questions and answers typically cover Azure Data Factory, Databricks, Synapse Analytics, SQL, Spark, data storage, ETL pipelines, security, and cloud-based analytics solutions used in enterprise environments.
Q2. Why are Azure Data Engineer interview questions important?
Azure data engineer interview questions are important because they help employers evaluate a candidate’s technical knowledge, cloud architecture understanding, problem-solving ability, and practical implementation skills. These questions also help candidates prepare for real-world Azure data engineering tasks and improve confidence during technical interviews.
Q3. How do Azure Data Engineer interview questions work?
Azure data engineer interview questions usually combine theoretical concepts, scenario-based discussions, and practical problem-solving exercises. Interviewers may ask candidates to explain Azure services, design scalable pipelines, optimize Spark jobs, secure cloud data platforms, or troubleshoot enterprise analytics workflows using Azure technologies.
Q4. What are the benefits of Azure Data Engineer interview questions?
Practicing azure data engineer interview questions helps candidates improve technical understanding, identify knowledge gaps, strengthen cloud architecture skills, and prepare for real-world interview scenarios. These interview questions and answers also help professionals gain confidence in handling Azure Data Factory, Databricks, Synapse Analytics, and data engineering discussions.
Q5. Who should learn Azure Data Engineer interview questions?
Azure data engineer interview questions are useful for freshers, cloud professionals, database administrators, ETL developers, data analysts, and experienced engineers preparing for Azure Data Engineering roles. Candidates preparing for the DP-203 certification can also benefit significantly from practicing these interview questions and answers.
Q6. What are the prerequisites for Azure Data Engineer interview questions?
Before preparing for Azure data engineer interview questions, candidates should understand SQL, ETL concepts, cloud computing fundamentals, data storage, and Azure services such as Azure Data Factory, Azure Data Lake, Databricks, and Synapse Analytics. Hands-on project experience can greatly improve interview performance.
Q7. How to get started with Azure Data Engineer interview questions?
To get started with azure data engineer interview preparation, begin by learning Azure fundamentals, SQL, and data engineering concepts. Then practice interview questions and answers related to ADF, Spark, Databricks, Synapse Analytics, and real-world scenario-based problems commonly asked during technical interviews.
Q8. What is the future of Azure Data Engineer interview questions?
The future of azure data engineer interview questions is increasingly focused on real-time analytics, AI-powered data engineering, cloud automation, big data processing, and scenario-based architecture discussions. As enterprises continue adopting Azure cloud services, demand for skilled Azure Data Engineers is expected to grow significantly.
Next Task For You
In our Azure Data Engineer training program, we will cover 27 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking our FREE CLASS.




![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)




