




![]()
This blog post will give a quick review of all the questions related to core data concepts that were discussed in our Microsoft Azure Data Fundamentals [DP900]. The Azure DP900 Certification is for all those who are looking forward to starting working with or shifting their focus to Azure Cloud Data Services for various data-related tasks.
Microsoft Azure has a variety of data solutions and services and the Azure DP900 Certification gives a holistic overview of the most common services that can be used in various data scenarios – data ingestion, transformation, processing, modeling, storage, automated pipelines, and data security.
We covered the following Topics in the Data on Azure Cloud Day 1 Session:
- Core data concepts
- Data roles and services
- Explore relational data concepts
- Explore Azure services for relational data
- Fundamentals of Azure Storage
- Fundamentals of Azure Cosmos DB
- Large-scale data warehousing
- Streaming and real-time analytics
- Data visualization
Here are the questions that we discussed in Day 1 Session:
> Day 1: Explore Core Data Concepts
1) Relational Data Type
Q1: A row in a table represents a single entity, similarly what does a column represent?
A: Columns would represent attributes or categories of that row (entity). For example, if a row represents an employee, then the columns would represent attributes like name, age, department, and tenure.
Q2: What is a primary key and table index?
A: A primary key is a column in the table whose values are unique and non-null. Hence, they can uniquely identify all the records in the table. But the queries sometimes need to go through all the records in the table to fetch the results – making performance slower. An index is a data structure based on any column of the table that stores the ordered values of that column. The query then can look up the required values from the index easily and accordingly fetch the matching records from the table. This increases the query performance. Indexes can hold duplicate and null values and are stored as physical objects on a disk.
Q3: Do indexes impact performance when we join tables?
A: Indexes do trade-off between faster data fetching speed with slower data update and joining speed. However, if the right columns are indexed and the number of the indexes on a table is optimal, then indexes greatly increase the performance of insertion, update, and join queries
Q4: Is Database View an example of Encapsulation?
A: A view in a database is an output of a query or a (virtual view of a database) on the original data showing selected columns and rows to the user. Views are created to abstract or hide some data from the user which may not be needed for the user to see. For example, a customer should not be allowed to view the data related to the manager or supervisor level. Hence a separate view showing customer-level data can be created. Views can be queried and manipulated just like the original database, they encapsulate the underlying code which accesses the original database and fetches the result.
Q5: What does ‘Isolation’ mean in ACID property?
A: Isolation refers to the scenario where the database transactions are carried out serially (one after the other), without other transactions impacting them. For example, when one transaction is writing to the row of the database, other transactions won’t read or write to that database row until that transaction is complete.
Q6: What is AVRO?
A: Avro is a language-neutral data storage format for Hadoop. It is used as a serialization platform for applications to send and receive their data over a network. Avro uses a data definition (schema) that is language independent, hence it can be used by multiple languages to serialize their data. The data is serialized in a compact and binary format while the schema is in the JSON format. Avro serializes the data without having to know its original schema. Both old and new applications can exchange their data.
Q7: Why do we use relational databases when we have AVRO?
A: Avro helps to only serialize and deserialize data when two applications want to exchange their data. We need databases (relational or non-relational) though to permanently store the data of the two applications.
Q8: Can we say for the OLAP system the data will be from OLTP?
A: Yes, OLAP data comes from the various OLTP Databases.
Q9: What is JSON?
A: JSON stands for JavaScript Object Notation is a text format for storing and transporting data, it is “self-describing” and easy to understand.
Q9. Are Private Cloud and On-Premises Same?
A: No, Private Cloud is different from On-Premises!
A Private Cloud is a cloud service provided by a Cloud provider that is not shared with any other organization, customers, etc. Servers are managed by a Cloud provider.
Whereas On-Premises is hosted by their own organization. They have to buy their own servers and they are responsible for their servers.
Q10: Can you please re-go what are indexes
A: Indexes are special lookup tables that can be used by the database search engine to speed up data retrieval.
Q11: How can we differentiate BTW pry and foreign key?
A: A primary key in a table is a column or combination of columns whose values uniquely identify a table row. A foreign key is a column or set of columns in a table whose values correspond to those of another table’s primary key.
Q12: How would you monitor the resources in the elastic pool?
A: In the Azure portal, you can monitor the utilization of an elastic pool and the databases within that pool. You can also make a set of changes to your elastic pool and submit all changes at the same time. These changes include adding or removing databases, changing your elastic pool settings, or changing your database settings.
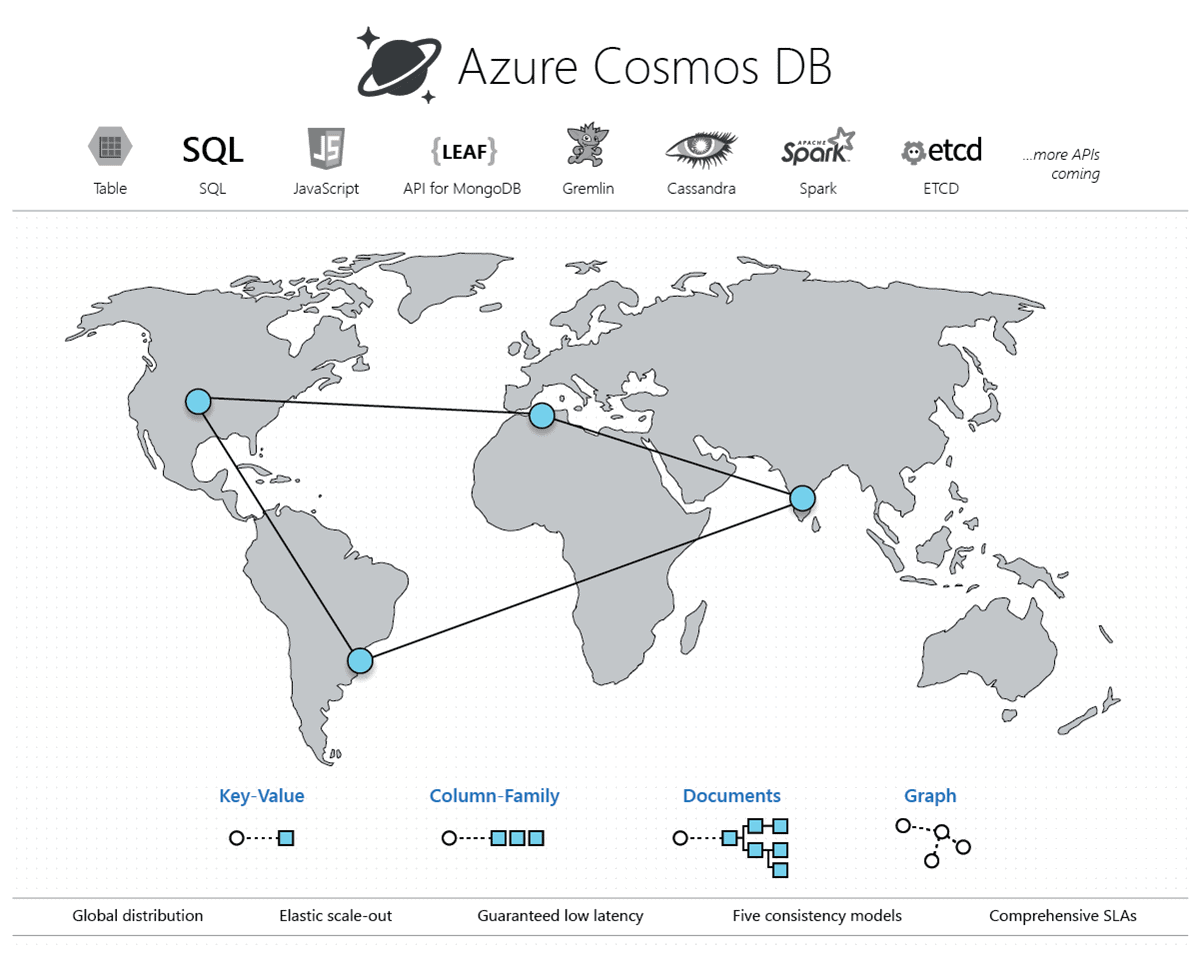
2) Non-Relational Data Type
Q1: Why is data retrieval easy with non-relational databases?
A: Non-relational databases have flexibility in their data schemas and data structures. Unlike relational databases, they do not have definite structures like tables, rows, primary keys, or foreign keys nor other data constraints. They are optimized to store, handle and manipulate unstructured data in their data schemas and also support sparse data formats. This makes data retrieval easy with non-relational databases.
Source: Microsoft
Q2: What is the difference between non-relational and unstructured data?
A: Non-relational databases are the ones that support and store unstructured data.
Q3: Can we create a solution with relational and non-relational data persistence?
A: Yes, many modern data applications in use today require various kinds of data – both relational and non-relational data storage and manipulations.
Q4: Which database (relational or non-relational) will be better for the performance?
A: Both databases are optimized for their respective purposes – relational databases for relational data and non-relational databases for non-relational data. Application performance also depends on the type of application itself, incoming data speed, and access frequency of data.
Q5: Can a NoSQL database be used for Relational data?
A: Some NoSQL might store relational data after a complex use of their data structures. But will not be able to handle, express, and manipulate relational data as relational databases do. Better use Relational databases for relational data and NoSQL for non-relational since both are optimized for their own purpose.
Q6: Is MongoDB an example of non-Relational data?
A: Yes, MongoDB is a NoSQL-based document-oriented database.
Q7: Do APIs use JSON file formats?
A: Most of the APIs use JSON formats to work with data
Q8: What are examples of Column Family and Graph Databases?
A: Recommendations, Sensor data, Personalization, Telemetry, Social media analytics, Messaging, Web analytics, Weather, and other time-series data are examples of Column Family databases while Organization charts, social graphs, Fraud detection, and Recommendation engines are examples of Graph databases.
Q9: Does the ACID Principle apply only to relational data or to non-relational data as well?
A: ACID properties are a must for relational data while they are relaxed for non-relational data since they do not have a table-like structure. NoSQL data eventually come to consistency over a period of time.
Q10: Can Non-relational data be in all 3 forms – structured, non-structured, or semi-structured?
A: Non-relational data refers to NoSQL databases that can store structured, semi-structured, and unstructured data.
Q11: Document is also key-value or JSON? Right?
A: Document is in the form of JSON files not key-value pairs.
Q12: in key/value format, does the value contains more than 1 value or multiple values?
A: Yes it may contain more than one or more values.
Q13: Is the graph database similar to ER diagram??
A: Yes graph databases are similar to ER diagrams.
Q14: Can you please explain the key-value store?
A: A key-value store is the simplest (and often quickest) type of NoSQL database for inserting and querying data. Each data item in a key-value store has two elements, a key, and a value. The key uniquely identifies the item, and the value holds the data for the item. The value is opaque to the database management system. Items are stored in key order.
Q15: Can u please explain one more time column family database.
A: Multiple rows make up a column family. The number of columns in each row can differ from the number of columns in the other rows. Furthermore, the columns do not have to match those in the other rows (i.e. they can have different column names, data types, etc). Each row is divided into columns. In contrast to a relational database, it does not span all rows. There is a name/value pair in each column, as well as a timestamp.
3) Data Stores (Transactional and Analytical)
Q1: What is the basic difference between OLTP and OLAP?
A: Online Analytical Process (OLAP) is used for analytical workloads whereas Online Transactional Processing (OLTP) is for transactional workloads.
Q2: What is mean by data stored in the cube?
A: Data cube is an imaginary or logical structure of numeric data (e.g. price) stored across various dimensions (e.g. region, department, state) for quicker analysis. It mostly stores pre-calculated data aggregations of metrics across its dimensions for faster query response.
Q3: What is the batch streaming process?
A: In the batch streaming process, data are grouped into batches over time. These batches are then sequentially fed into an analytics system for processing.
Q4: What is a normalized database schema?
A: Normalization involves splitting a large database table into smaller ones and define relationships between them to increases the clarity in organizing data. It helps reduce data redundancy and increases the query execution speed.
Q5: Olap is not in normalized form? Right?
A: Yes Tables in the OLAP database are not normalized.
Q5: For OLTP, we need a normalized database, not for OLAP.
A: Yes OLTP is fully normalized whereas OLAP is denormalized or partially denormalized schemas.
4) Azure Data Tools
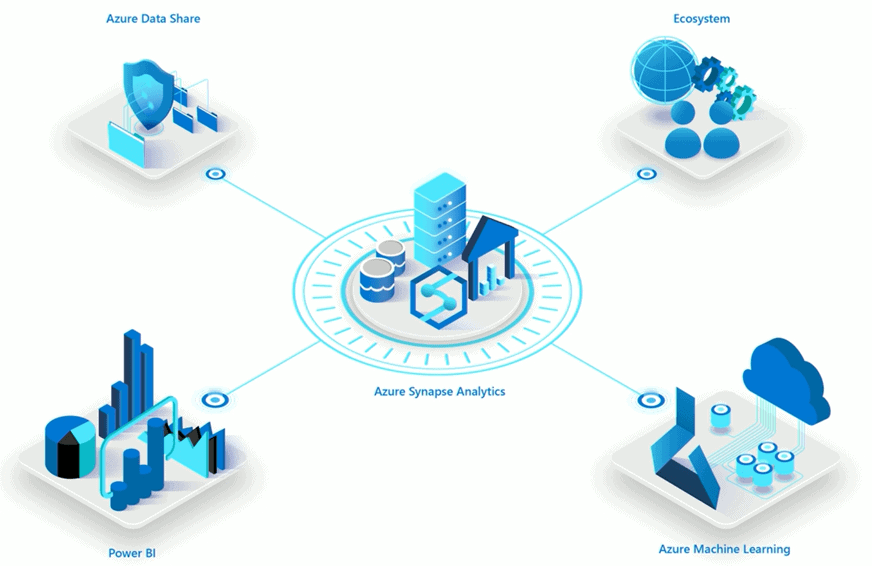
Q1: Is there a built-in feature in Azure that will do data analysis and provide BI?
A: Azure Synapse Analytics is a Platform-as-a-Software (PaaS) Solution that is built on top of Azure SQL Data Warehouse. It can be used for data querying, transformation, and BI purposes. It is specially designed to handle and manage Big Data workloads and provides Machine Learning services too. We can either use on-demand or server-less resources for our data workloads.
Source: Microsoft
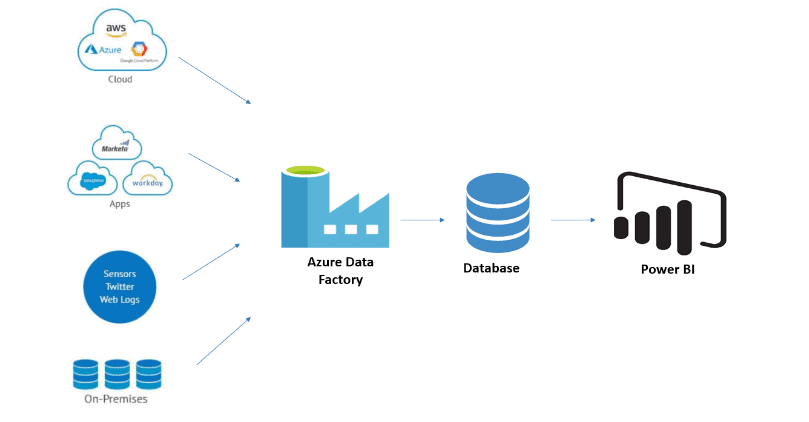
Q2: How can I create pipelines with the services provisioned on the Azure portal?
A: Azure Data Factory is the Azure cloud-based service to create ETL or ELT pipelines. It creates automated data workflows in the Cloud i.e Azure. The data workflows can be created which a graphical user interface or by writing pieces of code. Data Factory can be integrated with various other Azure Services and also provides monitoring of the created pipelines. It can orchestrate data movements and transform data at scale.
Q3: Is it possible to resize the resources while the Azure instances are up and running?
A: Yes, all Azure resources are elastic (resizable) in nature even when they are running in the background. While Azure manages that for you, they can be manually resized as well.
Q4: What is Maria DB? Does Azure offer MySQL databases?
A: Maria DB is an open-source relational database that provides an interface for MySQL. Azure does offer MySQL database services that can be deployed in three ways – Azure SQL Database for individual standalone database, Azure SQL Managed Instance for creating groups of SQL Databases, and SQL Database on Azure Virtual Machine for creating SQL Servers.
Q5: Can we access Azure blobs from Azure Databricks?
A: Yes, Azure Databricks makes it possible to access Azure blobs.
Q6: Can Azure be connected with Python or is there a separate language for using Azure?
A: Azure services support Python along with other languages too such as C, C#, Java for user flexibility in using them.
Q7: What is Azure Data Studio?
A: Azure Data Studio is a query editing tool for cross-platform databases. It provides features like query results charting, source control integration, and dashboards to give a good experience to users. It is freely available in Windows, Linux, and Mac OS.
5) Data Analytics
Q1: Which one is better between ETL and ELT? Any pros or cons?
A: Both methods have their own benefits and trade-offs, however, ELT is more beneficial for modern data processes than ETL. Let us have a look at the pros and cons of ETL and ELT below:
- ETL (Extract-Transform-Load) first transforms the extracted data before loading it to its destination (storage or analysis reports)
- Pros: It can be quickly implemented at an early stage
- Cons: Extra time to load and transform data due to the presence of staging area – as the size of data grows, speed decreases. No flexible transformations since it is to be in accordance with the loading destination constraints. Data has to be extracted again if transformations go wrong.
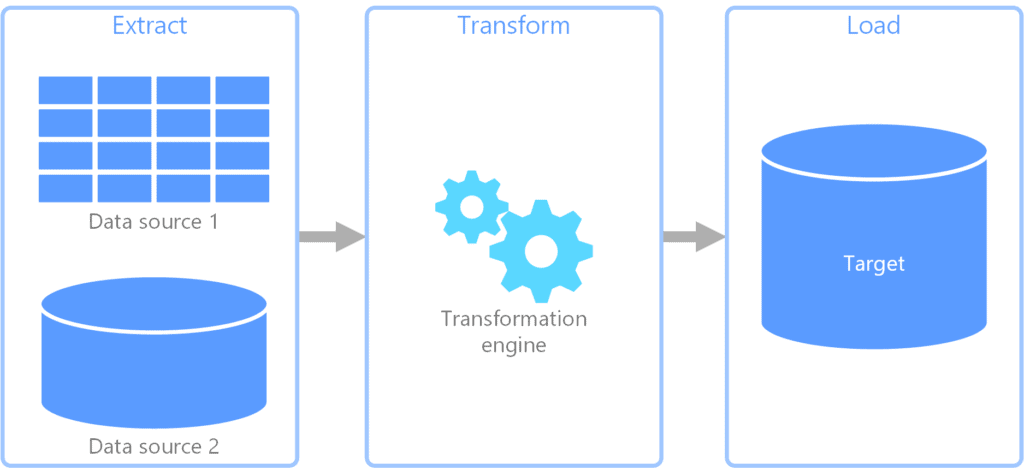
- ELT (Extract-Load-Transform) first loads the raw extracted data at a place that can then be used for future transforms before being consumed.
- Pros: No staging area present since loading is prior to transforming, hence it is faster and scalable for huge data volumes. Users can freely apply and experiment with a variety of data transformations and the extracted raw data is always available to use again and again.
- Cons: It takes high technical knowledge of tools to be implemented for use.
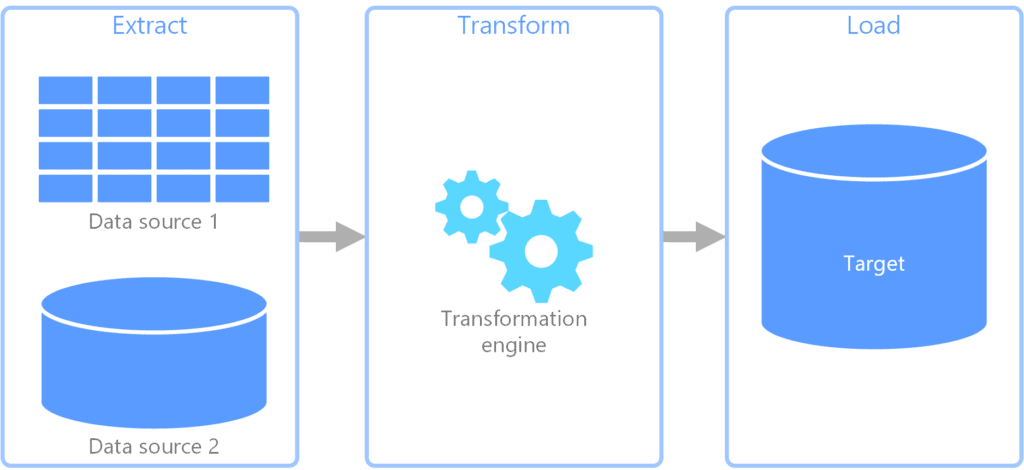
Q2: Which Azure tool is used for ELT purposes?
A: Azure Data Factory is the cloud-based service to create ETL or ELT pipelines. It creates automated data workflows in the Cloud i.e Azure. The data workflows can be created which a graphical user interface or by writing pieces of code. Data Factory can be integrated with various other Azure Services and also provides monitoring of the created pipelines. It can orchestrate data movements and transform data at scale.
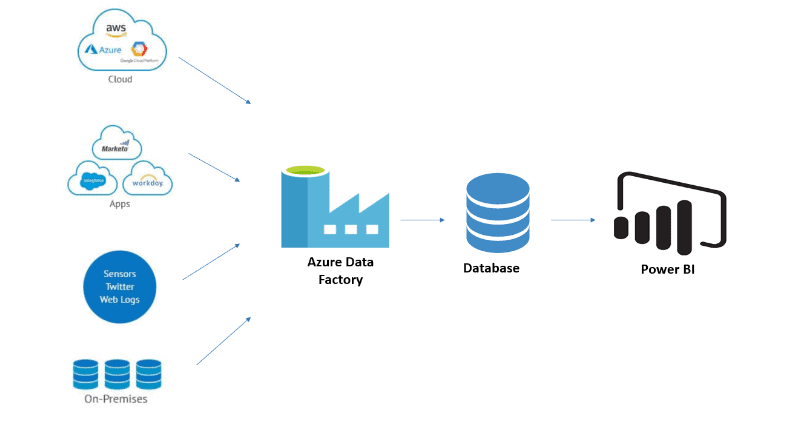
Q3: What is real-time data then? is it not stream?
A: ““Streaming data” or “real-time data” is dynamic data that is continuously generated from a variety of sources like sensors, cameras, social media feeds, and cameras. Examples of real-time data are e-commerce purchases, geo-location tracking, server activity, health data, website activity, weather events, and utility service usage.”
Q4: OLTP Is Batch Processing? and Stram Processing is OLAP?
A: No, OLTP is stream processing and OLAP is batch processing.
Q5: Difference b/w Data Ingestion and SQL Ingestion? is it equal to hacking?
A: Data ingestion is capturing raw data streaming from various sources and string it whereas SQL ingestion is the process of importing data into a relational database. SQL injection is equal to hacking.
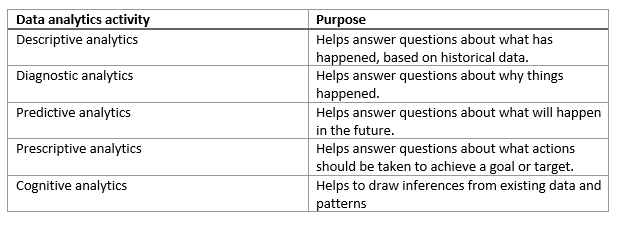
Q6: What is data analytics?
A: The term data analytics is a catch-all that covers a range of activities, each with its own focus and goals. You can categorize these activities as descriptive, diagnostic, predictive, prescriptive, and cognitive analytics.
Q6: can u give a simple example of elt
A: Ingesting data into azure datalake transform to the azure data warehouse.
Q7: Are there different tools for ETL and ELT
A: Yes some tools may differ but most of the tools like Talend, Informatica, etc can do both ELT and ETL.
6) Data Visualization
Q1: Is Power BI a licensed tool?
A: Yes, you can also access its free version with your school or workplace email ID.
Q2: Is Power BI provided free within Azure?
A: You can access the free version of Power BI with the help of Azure. Create an Azure user in the portal and use those credentials to access the free Power BI Subscription.
Q3: What is the difference between Key Influencer Chart and Column/Bar Chart?
A: They are almost similar with slight differences and purpose:
- Column/Bar Chart: It shows you a category with its corresponding metric, by a raised bar. The higher the metric value for any category, the higher would be the bar. It is used to visually grasp the diversity or intensity of any metric across various categories.
For example, employee retention percentage (metric) across various company departments (categories) - Key Influencer Chart: They show or highlight a list of factors or categories that highly impact or influence the outcome of a given metric. They are used to highlight which columns or factors are important for the change or effect in the metric.
For example, for employee retention percentage (metric), key influencers could be compensation, work-life balance.
Q4: What are Descriptive and Prescriptive Analytics?
A: Descriptive analytics tells you what happened in the past. It gives you a summary statistic of the past scenarios. Prescriptive analytics recommends actions or measures that you can take to change (improve) a predicted or certain future outcome.
Q5: What is the equivalent of CloudWatch in azure?
A: Azure monitor consumes the telemetry data that all Azure services generate and allows the user to visualize.
Q6: We can generate the reports with the data studio as well.
A: Yes we can generate but power BI has more functionalities than Data Studio.
> General Azure DP-900 Certification FAQ
Q1: What is the difference between Azure AZ-900 and Azure DP-900 Certifications?
A: Azure AZ-900 is intended for candidates who are planning to take their first step in Cloud or are new to Azure. It helps candidates to demonstrate foundational level knowledge of Cloud services and how those services are provided with Microsoft Azure.
Azure Fundamentals can be used to prepare for other Azure role-based certifications like Azure Solution Architect [AZ-305], Azure Administrator [AZ-104], Azure DevOps Engineer [AZ-400], and more, but AZ-900 is not a prerequisite for any of them and you can directly go for any of these Certifications.
Azure DP-900 is for candidates who want to start working with data on the Cloud, get basic skills in Data Platform on Cloud data services, and also build their foundational knowledge of Platform Cloud data services in Microsoft Azure.
Azure Data Fundamentals can be used to prepare for other Azure role-based certifications like Azure Data Engineer Associate [DP-203], Azure Data Scientist Associate [DP-100], and Data Analyst [PL-300], but it’s not a prerequisite for any of these exams.
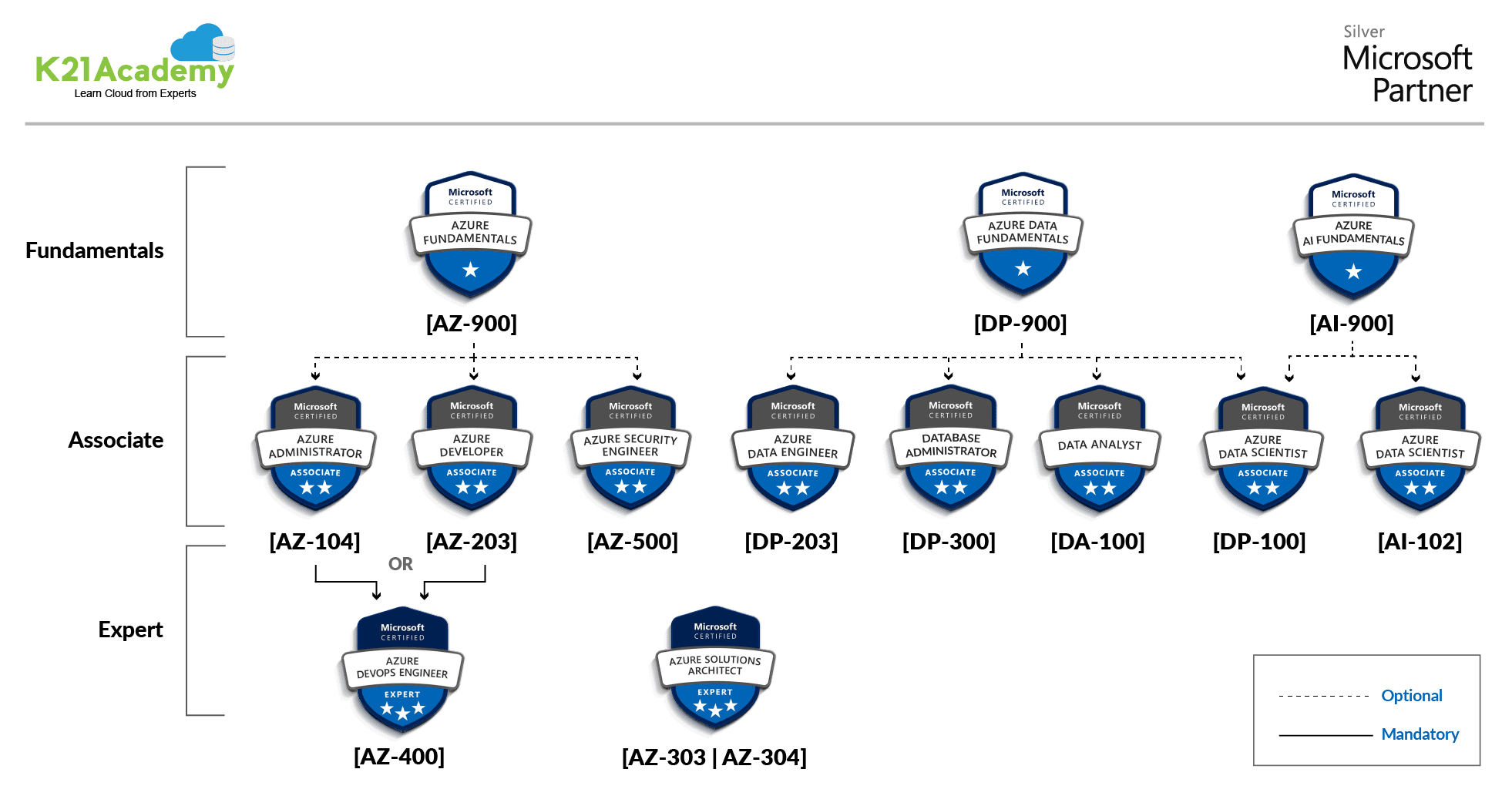
To know more about AZ900 and DP900, see Azure Fundamental Certification: AZ-900 vs AI-900 vs DP-900 (k21academy.com)
Q2: Can a beginner in Azure/Cloud or a person with a non-IT background take the DP900 Course?
A: Yes, the Azure DP900 does not require any technical pre-requisite in IT or the cloud. However, a basic knowledge of the cloud and IT terminologies is recommended and will help you better relate to the concepts in the Course.
Q3: Can a fresher or a non-tech person join this training?
A: Yes, in Azure DP900 we cover and teach all concepts assuming you are a total beginner so that non-techies can also benefit from it.
Q4: After these 2 Days’ Sessions, will I be in a position to appear for DP-900 certification? Or should I need to attend any other training sessions?
A: You can easily crack the Azure DP900 after these two days of our free training. These should give you an all-around knowledge of the Azure DP900 content, you can also enroll in our Azure DP900 Training or best, Azure DP203 Training for in-depth knowledge and a good hands-on experience in using Azure Services.
Q5: By clearing DP-900 Certification, is it possible to get an entry-level job?
A: Entry-level jobs do need some amount of hands-on exposure or experience along with beginner-level certifications like Azure DP900.
Q6: Which Certification I can go for after DP-900?
A: The Azure [DP-900] is the Azure Fundamental Level Certification and is important if you want to get Certified in any Expert-level Certification.
You can go for any of these Certifications after clearing Azure DP-900…
- Azure DP-203 (Data Engineer)
- Azure PL-300 (Data Analyst)
- Azure DP-100 (Data Scientist)
Anything else? Or not sure which one should you pick? Comment with what Certifications you have done and what you want to do next.
Q7: Do I need to know about Big Data tools to get Azure DP-900 Certified?
A: There is no such pre-requisite to be aware of big data and its tools since Azure DP900 gives you a brief as to what is Big Data and how Azure provides services to work and manage big data.
Q8: I am from a non-technical background. Will your course help change my stream?
A: The Azure DP900 Course gives you overall know-how to change your stream in Azure Data Engineer (Dp203), Azure Data Scientist (DP100), or Azure Data Analyst (DA100).
Q9: Can we do both Data Engineering and Data Scientist Certifications?
A: Yes, you can be certified in both of them one after the other.
Q10: Is there any certificate for this DP900 free course?
A: Since it is a free class open for all, we do not provide certification for the same.
Q11: Is any programming knowledge required to know for a Data Scientist?
A: Python is the most popular and recommended one along with SQL, we have covered Python concepts in our DP100 (Azure Data Scientist) Training.
Q12: I’m currently working on ETL. Is it good to move to a Data engineer?
A: YES! The Data Engineer role is used very commonly along with ETL skills. You will be definitely moving towards an interesting area from a big data perspective. Programming is not a necessary prerequisite as Azure data services are easy to learn for people from SQL backgrounds.
Q13: I have Oracle DBA 20 years of experience. What is the best path for my career?
A: I think you should opt for Azure Data Engineer [DP-203] because this course is for people who have DB experience. To get the guidance on Azure Data Engineer [DP-203], I have a FREE Class for you.
Q14: Can we take DP 900 Exam after next week’s session?
A: Yes, you can take but before taking the exam please do some hands-on and do know azure services knowledge as well.
Q15: I have a gap of 5 years how can I restart my career?
A: Please don’t worry nowadays company never sees career gap if you have good technical knowledge of whatever the company requires. Also, attend a 60-90 mins Free Class where we cover everything about azure data engineering.
Q16: What are AZ & DP keywords?
A: AZ stands for Azure, DP stands for Data Platform
Q17: What would be the best cheap way to transfer files from azure to aws?
A: Move your data from AWS S3 to Azure Storage using AzCopy for more details please go through this link https://azure.microsoft.com/en-in/blog/move-your-data-from-aws-s3-to-azure-storage-using-azcopy/
Q18: Who are data stewards?
A: A data steward is a role in an organization’s oversight or data governance that ensures the quality and fitness for purpose of the organization’s data assets, including the metadata for those data assets.
> Other Azure Certifications FAQ
Q1: I am working as an SAP Consultant. Is this course being beneficial for me?
A: Azure Solution Architect 303/304 or Azure Admin AZ-104 will be better for you. Azure DP900 is beneficial for all those in data-related roles to get a glimpse at Azure Data Services and for certifications like DP203, PL300.
Q2: Do you also have Azure Security Certification Training available?
A: Yes we have AZ-500 which is an Azure Security Certification for security professionals.
Q3: Would this course help me in enhancing the skills for taking a role in Data Analyst?
A: For Data Analysts and BI professionals we have Microsoft Azure Data Analyst Associate [Pl300] Certification, you can register for the free class, take a look at the hands-on labs.
Q4: Do you have a complete course from start to end for Data Science? Including the Cloud services?
A: Yes, we provide training for Azure DP100 Azure Data Scientist. This course teaches you to leverage your existing knowledge of Python and machine learning to manage data ingestion and preparation, model training and deployment, and machine learning solution monitoring in Microsoft Azure.
To know what you can expect in the training program and what all we cover in the Hands-On-Labs, attend this FREE Class.
References
- Microsoft Azure Data on Cloud Bootcamp: Hands-On Labs & Projects for Job-Ready Skills
- Azure Data Lake For Beginners: All you Need To Know
- Batch Processing Vs Stream Processing: All you Need To Know
- Introduction to Big Data and Big Data Architectures
Next Task For You
In our Azure Data on Cloud Job-Oriented training program, we will cover 50+ Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified Associate and Get High-Paying Jobs check out our FREE CLASS.







![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



