


![]()
The way businesses develop chatbots, knowledge assistants, recommendation systems, and corporate copilots is being drastically changed by generative AI applications. The two most effective methods for enhancing the performance of large language models (LLMs) are fine-tuning and retrieval-augmented generation (RAG).
Services like Vertex AI, Gemini models, Vector Search, BigQuery, and Cloud Storage on Google Cloud enable both strategies. Many AI engineers and businesses, however, find it difficult to choose between RAG and fine-tuning.
This blog provides a thorough comparison of RAG vs Fine-Tuning on Google Cloud, including architecture, benefits, limitations, cost considerations, and real-world use cases.
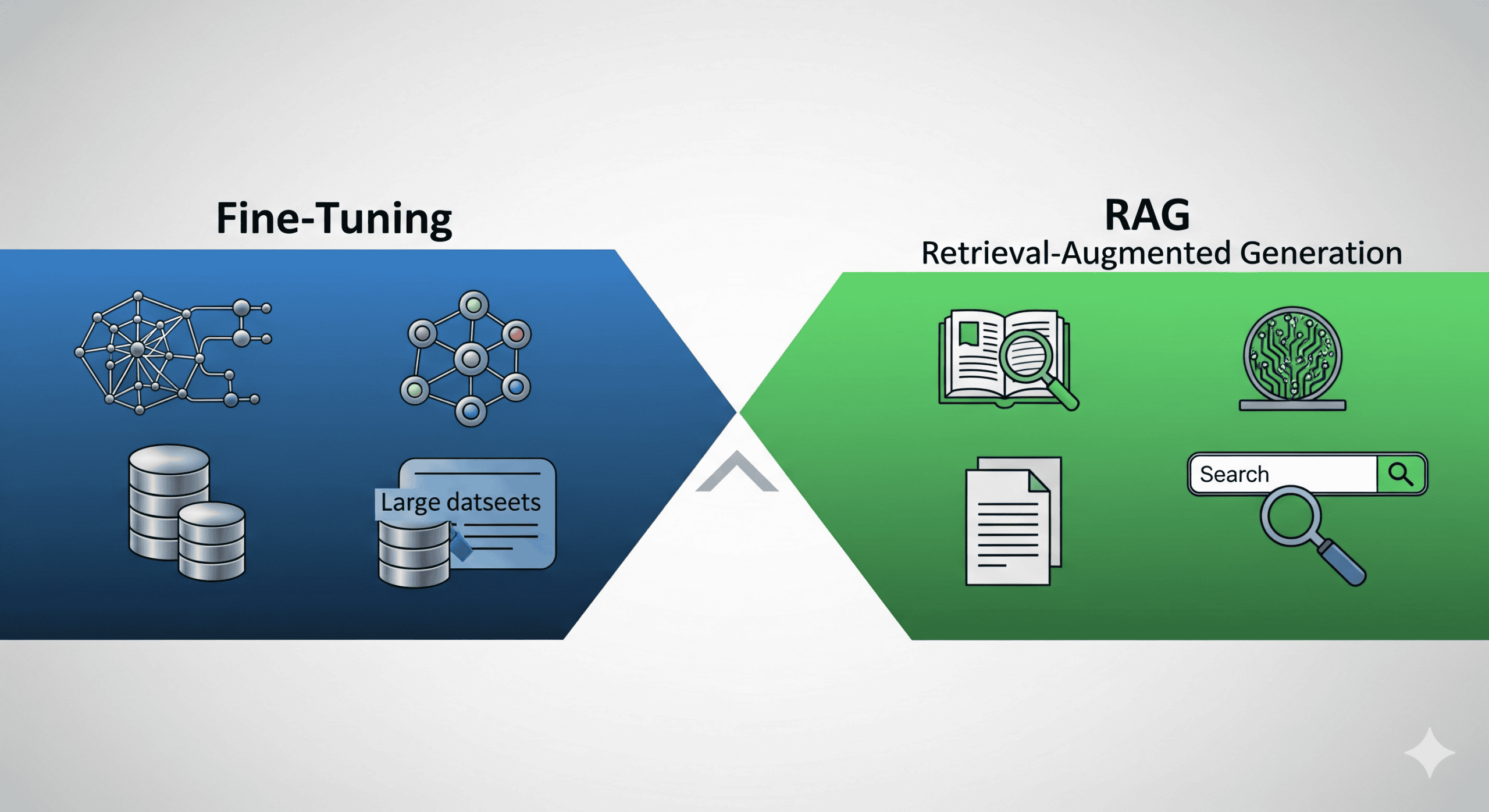
Understanding the Problem: Why Adapt LLMs at All?
Out-of-the-box LLMs are trained on public, general-purpose data. While powerful, they suffer from key limitations:
- No access to your private or proprietary data
- Knowledge cutoff (no awareness of recent updates)
- Generic tone and behavior
- Risk of hallucinations
Teams usually select one of two tactics to get around this:
- Bring the data at query time using Retrieval-Augmented Generation (RAG).
- Fine-tuning: Modify the model’s behaviour indefinitely
What Is RAG (Retrieval-Augmented Generation)?
Consider RAG (Retrieval-Augmented Generation) as an AI open-book test.
A conventional LLM functions similarly to a student sitting for a closed-book test:
- It simply responds based on what it learnt in training.
- It is unable to search for new or confidential data.
- When uncertain, it could make a confident assumption (hallucination).
This is entirely altered by RAG. Rather than having the model “remember” everything, RAG enables it to:
- When the question comes up, look up pertinent facts
- Make use of your own materials as sources.
- Provide a fact-based response rather than a guess.
How RAG Works on Google Cloud
- Data is stored in Cloud Storage, BigQuery, or databases.
- Documents are converted into embeddings with the help of Vertex AI Embeddings API.
- Embeddings are stored in Vertex AI Vector Search or a vector database.
- User query is converted into an embedding.
- Relevant documents are retrieved using similarity search.
- Retrieved context is injected into the prompt for the Gemini model.
Related Readings: Google Cloud Vertex AI: What, Why, and How
What is Fine-Tuning?
The process of training a base model on unique datasets to teach it particular domain knowledge, tone, or tasks is known as fine-tuning. In contrast to RAG, fine-tuning adjusts the model’s weights to enhance performance for certain tasks.
How Fine-Tuning Works on Google Cloud
- Prepare labeled training datasets (JSONL, structured text).
- Use Vertex AI Fine-Tuning APIs or custom training pipelines.
- Train a tuned Gemini or foundation model.
- Deploy the tuned model as an endpoint.
- Use the model directly without external retrieval.
Advantages of RAG on Google Cloud
1) Always Updated Information: RAG is perfect for quickly evolving industries like banking, healthcare, and technology since it pulls the most recent records
2) No Need for Model Retraining: There is no requirement to retrain the model; you can add documents to update knowledge.
3) Cheaper Training: Only embedding and storage expenses & no costly training tasks
4) Integration of Enterprise Knowledge: RAG readily interfaces with Google Drive, BigQuery, Confluence, Internal databases
5) Explainability: By displaying retrieved sources, you may increase compliance and trust.
Limitations of RAG
- Requires vector databases and retrieval pipelines
- Higher inference latency
- Context window limits restrict document size
- Quality depends on retrieval accuracy
Advantages of Fine-Tuning on Google Cloud
1) Enhanced Task Efficiency: Fine-tuning is excellent at Classification, Structured output, Code generation & Domain-specific writing.
2) Reduced Latency for Inference: Responses are quicker when there is no retrieval step.
3) Personalised Style and Tone: Models can be trained to fit legal tone, compliance standards, or brand voice.
4) Limited or Offline Setting: Models that have been fine-tuned can function without using external databases.
Limitations of Fine-Tuning
- High training cost
- Requires labeled datasets
- Knowledge becomes outdated quickly
- Risk of overfitting
When to Use RAG on Google Cloud
Use RAG when:
- You need real-time knowledge updates
- Data changes frequently
- You want to avoid retraining costs
- You need citations or source tracking
- Enterprise documents are large and unstructured
Common RAG Use Cases
- Enterprise knowledge assistants
- Customer support bots
- Research copilots
- Internal documentation search
- Financial and legal Q&A systems
When to Use Fine-Tuning on Google Cloud
Use fine-tuning when:
- Task performance must be highly optimized
- Structured output is required
- Tone consistency is critical
- Latency must be minimal
- Domain data is stable
Common Fine-Tuning Use Cases
- Automated email generation
- Medical coding and classification
- Fraud detection text models
- Brand-specific content generation
- Code copilots for internal APIs
Hybrid Approach: RAG + Fine-Tuning
Many enterprise systems combine both approaches.
How Hybrid Architecture Works
- Fine-tune a base model for domain tasks and tone
- Use RAG to inject real-time enterprise knowledge
This approach delivers:
- High accuracy
- Fresh knowledge
- Brand consistency
Google Cloud supports hybrid architectures using Vertex AI Pipelines, LangChain, and Agent Builder.
Cost Comparison on Google Cloud
RAG is cheaper upfront, while fine-tuning has higher initial costs but lower per-query overhead for repetitive tasks.
RAG Cost Components
- Embedding API calls
- Vector database storage
- Retrieval compute
- LLM inference
Fine-Tuning Cost Components
- Training compute (GPU/TPU)
- Data preparation
- Storage for tuned models
- Inference endpoints
Performance & Scalability Considerations
RAG Performance
- Scales with vector database
- Dependent on retrieval quality
- Works well for large document repositories
Fine-Tuning Performance
- Faster inference
- Performance limited by training dataset quality
- Requires retraining for knowledge updates
Best Practices for RAG on Google Cloud
- Use chunking and overlap strategies
- Optimize embeddings with domain-specific preprocessing
- Use reranking models for better retrieval accuracy
- Monitor retrieval quality metrics
Best Practices for Fine-Tuning on Google Cloud
- Use high-quality labeled datasets
- Avoid overfitting with validation splits
- Monitor drift and retrain periodically
- Use parameter-efficient fine-tuning (PEFT) where possible
RAG vs Fine-Tuning: Decision Framework
Choose RAG if:
- Knowledge changes frequently
- Explainability is required
- Budget is limited
Choose Fine-Tuning if:
- Task-specific performance is critical
- Low latency is required
- Tone and style must be consistent
Choose Hybrid if:
- You need both accuracy and fresh knowledge
Future of RAG and Fine-Tuning on Google Cloud
Google is rapidly evolving its AI ecosystem with:
- Gemini multi-modal models
- Agentic workflows
- AutoRAG pipelines
- Managed fine-tuning services
Future enterprise AI systems will increasingly use adaptive RAG and continual fine-tuning for self-improving AI agents.
Conclusion
RAG and fine-tuning are complementary methods rather than rivals. Both are top-notch features on Google Cloud that allow for enterprise-level, scalable generative AI systems.
RAG is the ideal option if your application requires explainability and dynamic knowledge. Fine-tuning is the best strategy if you require low latency and highly optimised work performance. A hybrid RAG + fine-tuning architecture works best for the majority of businesses.
Understanding RAG vs fine-tuning on Google Cloud helps AI teams design cost-effective, scalable, and future-ready AI solutions.
Next Task For You
Don’t miss out on our GCP AI/ML & Gen AI Offer. Master cutting-edge AI and machine learning technologies with Google tools. Join a growing community of learners ready to elevate their careers.
Click the image below to know more about the program!




![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



