




![]()
This blog post will cover some quick tips including FAQs on the topics that we covered in the Day 4 live session which will help you to clear Certification [DP-100] & get a better-paid job.
In the previous week’s sessions, in Day 3 session we got an overview of Working with Compute. And in this week’s Day 4 Live Session of the AI/ML & Azure Data Scientist Certification [DP-100] training program, we covered the concepts of Orchestrating Operations with Pipelines. We also covered hands-on Lab 12 out of our 15+ extensive labs.
So, here are some of the Q & As asked during the Live session from Module 6: Orchestrating Operations with Pipelines & Hands-on Lab on Azure Machine Learning Designer of Microsoft Azure Data Scientist [DP-100].
>> Orchestrating Operations with Pipelines
Most big data solutions consist of repeated data processing operations, encapsulated in workflows. A pipeline orchestrator is a tool that helps to automate these workflows. An orchestrator can schedule jobs, execute workflows, and coordinate dependencies among tasks.
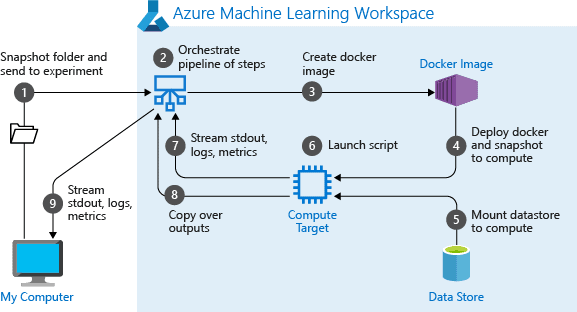
Q1: What are your options for data pipeline orchestration?
Ans: In Azure, the following services and tools will meet the core requirements for pipeline orchestration, control flow, and data movement:
- Azure Data Factory
- Oozie on HDInsight
- SQL Server Integration Services (SSIS)
These can be used independently from one another or used together to create a hybrid solution. For example, the Integration Runtime (IR) in Azure Data Factory V2 can natively execute SSIS packages in a managed Azure compute environment.
Q2: What are the common Pipeline Step types?
Ans: PipelineSteps represent an execution step in an Azure Machine Learning pipeline. The PipelineStep class is the base class from which other built-in step classes designed for common scenarios inherit, such as
- PythonScriptStep
- DataTransferStep
- HyperDriveStep
- EstimatorStep
- AdlaStep
- DatabricksStep
Here are Some Module 5: Working with Data & Module 6: Working with Compute Hands-on Lab Q & As.
Q3: How to configure Export Data?
Ans: Below steps are used to configure Export data
- Add the Export Data module to your experiment in Studio (classic). You can find this module in the Input and Output category.
- Connect Export Data to the module that contains the data you want to export.
- Double-click Export Data to open the Properties pane.
- For Data destination, select the type of cloud storage where you’ll save your data. If you make any changes to this option, all other properties are reset. So be sure to choose this option first!
- Provide an account name and authentication method required to access the specified storage account.
- The option, Use cached results, lets you repeat the experiment without rewriting the same results each time.
- Run the experiment.
Q4: How to define Tabular Dataset?
Ans: A TabularDataset defines a series of lazily-evaluated, immutable operations to load data from the data source into tabular representation. Data is not loaded from the source until TabularDataset is asked to deliver data.
TabularDataset is created using methods like from_delimited_files from the TabularDatasetFactory class.
Q5: How to Create Tabular Dataset?
Ans: To Create Tabular Dataset, Use the from_delimited_files() method on the TabularDatasetFactory class to read files in .csv or .tsv format, and to create an unregistered TabularDataset. To read in files from .parquet format, use the from_parquet_files() method. If you’re reading from multiple files, results will be aggregated into one tabular representation.
The following code gets the existing workspace and the desired datastore by name. And then passes the datastore and file locations to the path parameter to create a new TabularDataset, weather_ds.
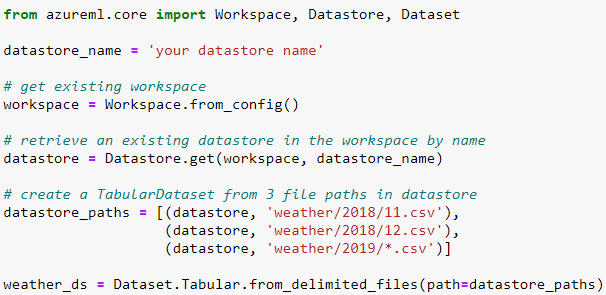
Q6: How to Define File Dataset?
Ans: A FileDataset defines a series of lazily-evaluated, immutable operations to load data from the data source into file streams. Data is not loaded from the source until FileDataset is asked to deliver data.
A FileDataset is created using the from_files method of the FileDatasetFactory class.
Q7: How to Create File Dataset?
Ans: Use the from_files() method on the FileDatasetFactory class to load files in any format and to create an unregistered FileDataset.
If your storage is behind a virtual network or firewall, set the parameter validate=False in your from_files() method. This bypasses the initial validation step and ensures that you can create your dataset from these secure files. Learn more about how to use datastores and datasets in a virtual network.
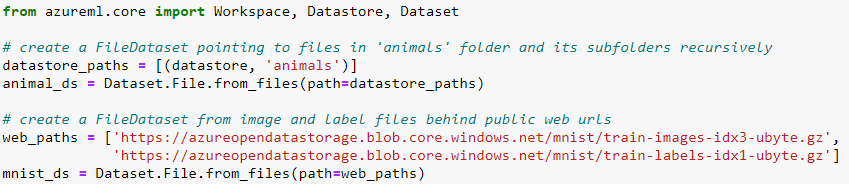
Q8: What is an attach compute?
Ans: Attach a Compute object to a workspace using the specified name and configuration information.
![]()
Parameters:
workspace: The workspace object to attach the Compute object to.
name: The name to associate with the Compute object.
attach_configuration: A ComputeTargetAttachConfigurati
Q9: What is AKS Compute Class?
Ans: Azure Kubernetes Service (AKSCompute) targets are typically used for high-scale production deployments because they provide fast response time and autoscaling of the deployed service. Constructor for the same is below:
AksCompute(workspace, name)
Parameters:
workspace: The workspace object containing the AksCompute object to retrieve.
name: The name of the AksCompute object to retrieve.
Feedback Received…
From our DP-100 day 4 session, we received some good feedback from our trainees who had attended the session, so here is a sneak peek of it.
 Quiz Time (Sample Exam Questions)
Quiz Time (Sample Exam Questions)
 Quiz Time (Sample Exam Questions)
Quiz Time (Sample Exam Questions)With my AI/ML & Azure Data Science training program, we cover 150+ sample exam questions to help you prepare for the certification DP-100.
Check out one of the questions and see if you can crack this…
Ques: You have published a pipeline that you want to run every week. You plan to use the Schedule.create method to create the schedule. What kind of object must you create first to configure how frequently the pipeline runs?
A) Datastore
B) PipelineParameter
C) Schedule Recurrence
Comment with your answer & we will tell you if you are correct or not!!
Related/References
- [AI-900] Microsoft Certified Azure AI Fundamentals Course: Everything you must know
- Azure Machine Learning Service Workflow: Overview for Beginners
- Azure ML Model
- Azure Free Account: Steps to Register for Free Trial Account
- Datastores And Datasets In Azure
- DP-100 Day 1 Live Session Review
- DP-100 Day 2 Live Session Review
Next Task For You
Begin your journey toward Mastering Azure Cloud and landing high-paying jobs. Just click on the register now button on the below image to register for a Free Class on Mastering Azure Cloud: How to Build In-Demand Skills and Land High-Paying Jobs. This class will help you understand better, so you can choose the right career path and get a higher paying job.







![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



