




![]()
A pipeline in Azure Data Factory represents a logical grouping of activities where the activities together perform a certain task.
This blog post will go through some quick tips including Q/A and related blog posts on the topics that we covered in the Azure Data Engineer Day 7 Live Session which will help you gain a better understanding and make it easier for you to
The previous week, In Day 6 session we got an overview of concepts of Transform data with Azure Data Factory or Azure Synapse Pipelines where we have covered topics like Azure Data Factory or Azure Synapse Pipelines.
In this week, Day 7 Live Session of the Training Program, we covered the concepts of Module 7: Orchestrate data movement and transformation in Azure Synapse Pipelines, where we have covered topics like Azure Data Factory or Azure Synapse Pipelines, Debug data factory pipelines, Add parameters to data factory components.
We also covered hands-on Orchestrate data movement and transformation in Azure Synapse Pipelines out of our 27 extensive labs.
So, here are some FAQs asked during the Day 7 Live session from Module 7 Of DP203.
>Data Factory Pipeline
A pipeline in Azure Data Factory represents a logical grouping of activities where the activities together perform a certain task.
An example of a combination of activities in one pipeline can be, ingesting and cleaning log data in combination with a mapping data flow that analyzes the log data that has been cleaned.
Activities in a pipeline are referred to as actions that you perform on your data. An activity can take zero or more input datasets and produce one or more output datasets
>Debug Pipeline
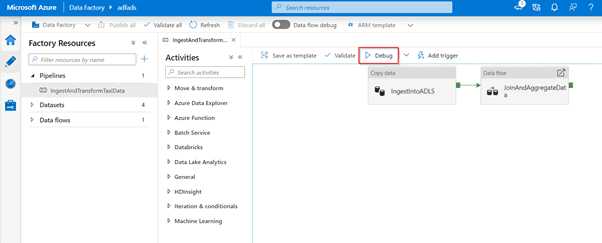
Azure Data Factory can help you build and develop iterative debug Data Factory pipelines when you develop your data integration solution. By authoring a pipeline using the pipeline canvas, you can test your activities and pipelines by using the Debug capability.
Note: When you’re debugging, you can edit the preview of data in a data flow by clicking “Debug Setting”. Examples of changing the data preview could be a row limit or file source in case you use source transformations. When you select the staging linked service, you can use Azure Synapse Analytics as a source.
To debug the pipeline, select Debug on the toolbar.
Check Out: Our blog post on Azure Data Engineer Interview Questions.
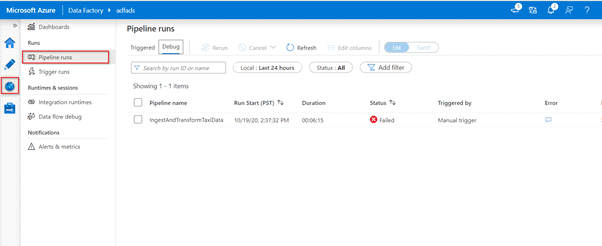
> Monitoring debug runs
In order to monitor debug runs, you can check the output tab, but only for the most recent run that occurred in the browsing session, since it won’t show the history. If you would like to get a view of the history of debug runs or see all the active debug runs, you can navigate to the monitor tab.
Check Out: Azure Data Factory Interview Questions.
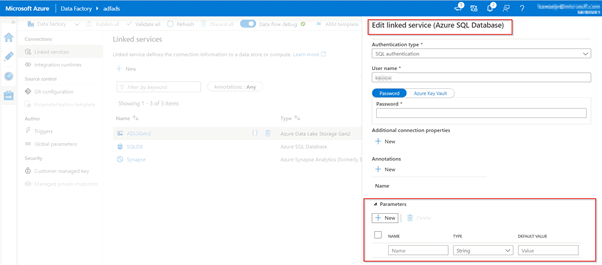
>Add parameters to data factory components
Within Azure Data Factory, it is possible to parameterize a linked service in which you can pass through dynamic values while at run time. A use-case for this situation could be connecting to several different databases that are on the same SQL server, in which you might think about parameterizing the database name in the linked service definition. The benefit of doing so is that you don’t have to create a single linked service for each database that is on the same SQL Server. It is also possible to parameterize other properties of the linked service like a Username
>Lab: Orchestrate Data Movement and Transformation in Azure Synapse Pipelines
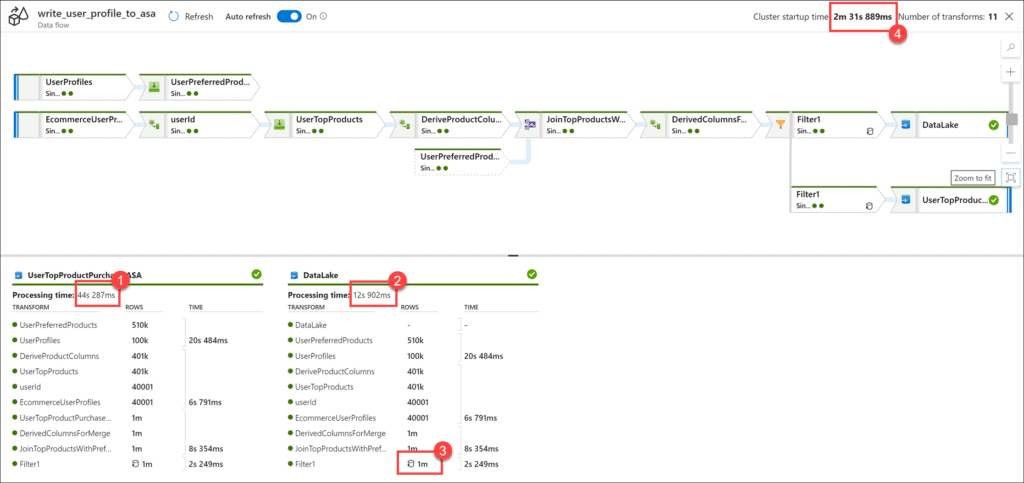
In this lab, by using Synapse Pipelines, you can experience the same familiar interface as ADF without having to use an orchestration service outside of Azure Synapse Analytics.
Check Out: Apache Spark Architecture Overview.
Azure Data Factory Demo: ETL Solutions:
Q1. What is Self-hosted integration runtime?
Ans: A self-hosted IR can run copy activity between a cloud data store and a data store in a private network.
Q2. Which IR to use?
Ans: If one data factory activity associates with quite one style of integration runtime, it’ll resolve to 1 of them. The self-hosted integration runtime takes precedence over Azure integration runtime in Azure data factory-managed virtual network. and therefore the latter takes precedence over public Azure integration runtime. for instance, one copy activity is employed to repeat information from supply to sink. the public Azure integration runtime is related to the joined service to supply and an Azure integration runtime in Azure information industrial plant managed virtual network associates with the joined service for the sink, then the result’s that each supply and sink joined service use Azure integration runtime in Azure data factory managed virtual network. however, if a self-hosted integration runtime associates the joined service for supply, then each supply and sink joined service use self-hosted integration runtime.
Q3. What is a supported connector for built-in parameterization?
Ans: Azure Synapse Analytics is a supported connector for built-in parameterization for Linked Services in Azure Data Factory.
Q4. What is an example of a branching activity used in control flows?
Ans: An example of a branching activity is The If-condition activity which is similar to an if-statement provided in programming languages.
Q5. Does distribution have to define for all fact tables?
Ans: Yes, otherwise, it will consider the default distribution ‘Round Robin’.
Q6. How can we create an ARM template to recreate only resources?
Ans: From the Azure portal menu, select Create a resource. In the search box, type storage account, and then press [ENTER]. Select the down arrow next to Create, and then select Storage account. Select Create new and specify a resource group name of your choice.
Q7.Where do we store the params?
Ans: Params are stored in the working directory of the Azure storage account used by Azure Cloud Shell.
Q8. What is Azure Synapse and how is it different from Azure Data Bricks?
Ans: Databricks is pretty much managed by Apache Spark, whereas Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing, and big data analytics.
Q9.What is the difference between ADF vs Synapse?
Ans: ADF has several templates which allow you to create pipelines based on some standard ETL scenarios. Synapse does not have this. Synapse also does not support Snowflake’s source/destinations. Finally, a few observations regarding the features behaving differently. Synapse has Spark notebooks, Spark job definitions, and SQL pool stored procedure activities that are not available in ADF. Azure Data Factory and its equivalent pipelines feature within Azure Synapse itself provide a fully managed cloud-based data integration service.
Q10. Dataset is just to define the source data, right? it doesn’t store any data, correct?
Ans: A dataset identifies the specific data in a data source that you want to use. For example, the data source might be a table if you are connecting to a database data source. … A dataset also stores any data preparation you have performed on that data, such as renaming a field or changing its data type.
Q11. When to use ADF and when synapse pipeline?
Ans: ADF has several templates which allow you to create pipelines based on some standard ETL scenarios. Synapse does not have this. Synapse also does not support Snowflake’s source/destinations. Finally, a few observations regarding the features behaving differently
Q12. Can you explain why cosmos is chosen over SQL DB?
Ans: SQL DB is a relational database and Cosmos DB is a non-relational DB. So, if it depends on the project how it is designed to allow customers to elastically (and independently) scale throughput and storage across any number of geographical regions. Azure Cosmos DB natively partitions your data for high availability and scalability. Azure Cosmos DB is a fully managed, elastically scalable, and globally distributed database with a multi-model approach. It offers plenty of benefits and provides you the ability to use document, key-value, wide-column, or graph-based data.
Azure Cosmos DB is Microsoft’s fast NoSQL database with open APIs for any scale. The service is designed to allow customers to elastically (and independently) scale throughput and storage across any number of geographical regions
Q13. What is a collection in Cosmos DB?
Ans: A collection is a container of JSON documents and associated JavaScript application logic, i.e., stored procedures, triggers, and user-defined functions.
Q14. Why does PolyBase require Staging?
Ans: Staging tables allow you to handle errors without interfering with the production tables. Polybase is a technology that accesses external data stored in Azure Blob storage, Hadoop, or Azure Data Lake Store using the Transact-SQL language. Polybase helps in the bidirectional transfer of data between Synapse SQL Pool and the external resource to provide fast load performance.
Q15. What is the difference between Debug and Trigger Now?
Ans: Trigger Now will execute your pipeline right away and this will be for just that time only. It won’t schedule anything. You will generally use this when you just want to execute the pipeline once may be for an initial one-time load or may because it was failed earlier etc. There is a subtle difference between the trigger now and the debug. Even though both will execute the pipeline once and that too immediately. The difference lies in the way the log gets captured. When you debug, you can see the pipeline details in the below output pane while when you trigger now, you can see logs in the monitor tab.
Q16. Dataset is just to define the source data, right? it doesn’t store any data, correct?
Ans: A dataset identifies the specific data in a data source that you want to use. For example, the data source might be a table if you are connecting to a database data source. A dataset also stores any data preparation you have performed on that data, such as renaming a field or changing its data type.
Q17. What is a control flow?
Ans: Control flow is an orchestration of pipeline activities that includes chaining activities in a sequence, branching, defining parameters at the pipeline level, and passing arguments while invoking the pipeline on-demand or from a trigger.
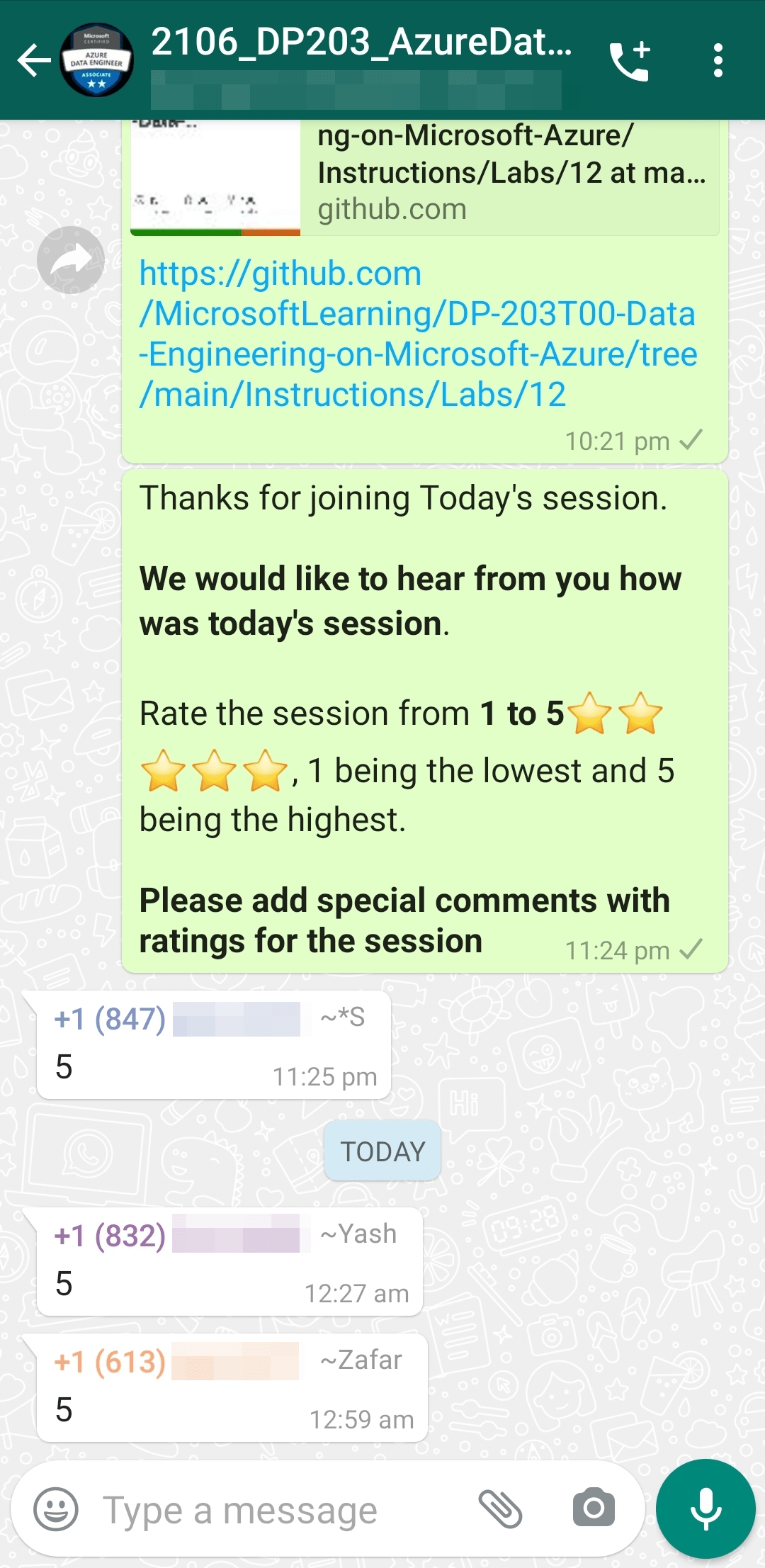
Feedback Received…
Here is some positive feedback from our trainees who attended the session.

Quiz Time (Sample Exam Questions)!
With our Azure Data Engineer Training Program, we cover 500+ sample exam questions to help you prepare for the [DP-203] Certification.
Check out one of the questions and see if you can crack this…
Ques: Which of the following should be used as a technology for the “Data Ingestion” layer?
A. Azure Logic Apps
B. Azure Data Factory
C. Azure Automation
D. Azure Functions
Comment with your answer & we will tell you if you are correct or not!
References
- Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Azure Data Lake For Beginners: All you Need To Know
- Azure Synapse Analytics (Azure SQL Data Warehouse)
- Azure Data Engineer [DP-203] Q/A | Day 1 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 2 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 3 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 4 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 5 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 6 Live Session Review
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.







![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



