![]()
Azure Synapse Spark Pools can load data from a variety of sources, including Azure Storage, Azure Data Lake Storage, and other cloud storage providers. You can also load data from on-premises sources using Azure Data Factory.
This blog post will go through some quick tips including Q/A and related blog posts on the topics that we covered in the Azure Data Engineer Day 3 Live Session which will help you gain a better understanding and make it easier for you to
The previous week, In Day 2 session we got an overview of concepts of Build data analytics solutions using Azure Synapse serverless SQL pools, along with Data engineering considerations for source files.
We also covered hands-on lab, 3 out of our 22 extensive labs
So, here are some FAQs asked during the Day 3 Live session from Module 3 Of DP203.
>Azure Databricks
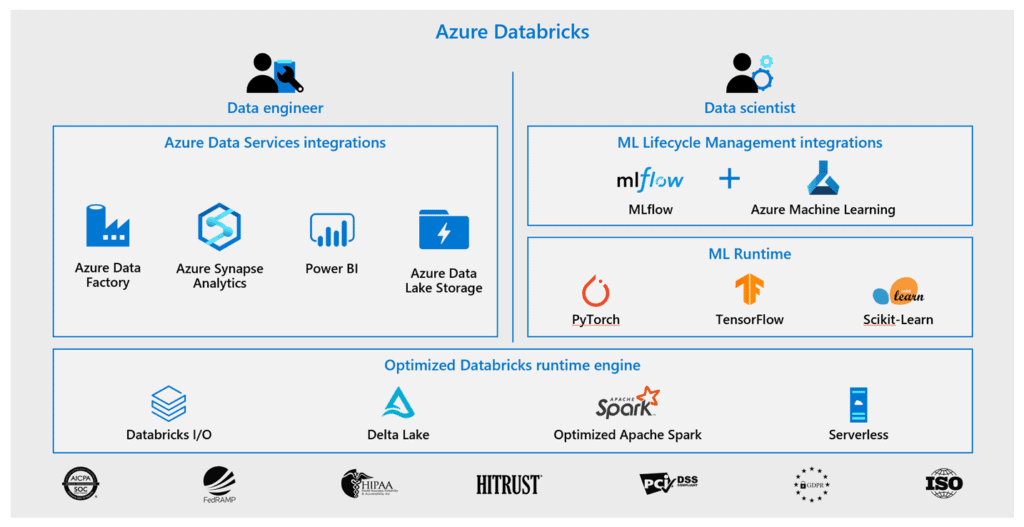
Azure Databricks may be an absolutely managed, cloud-based big data and Machine Learning platform, that empowers developers to accelerate AI and innovation by simplifying the method of building enterprise-grade production data applications. It integrates with Azure Data services which a Data Engineer should be familiar with. These services could include Azure Data Factory, Azure Synapse Analytics, Power BI, and Azure Data Lake Storage.
Azure Databricks uses an optimized Databricks runtime engine, to provide an end-to-end managed Apache Spark platform optimized for the cloud, whilst having the benefits of the enterprise scale and security of the Microsoft Azure platform. Azure Databricks makes it straightforward to run large-scale data engineering Spark workloads.
Source: Microsoft
Ques 1: What is the difference between Azure data bricks and synapse?
Ans: Azure databricks provides the ability to create and manage an end-to-end big data/data science project using one platform. Azure synapse provides the ability to scale efficiently with Apache Spark clusters within a one-stop-shop analytical platform to meet your needs.
Ques 2: What format does Delta Lake use to store data?
Ans: Delta Lake uses versioned Parquet files to store your data in your cloud storage. with the exception of the versions, Delta Lake conjointly stores a dealing log to stay track of all the commits created to the table or blob store directory to produce ACID transactions.

Ques 3: Where does Delta Lake store the data?
Ans: When writing data, you’ll be able to specify the placement in your cloud storage. Delta Lake stores the data in this location in Parquet format.
Check Out: Our blog post on Azure ADF Interview Questions.
>Work with DataFrames in Azure Databricks
Our data processing in Azure Databricks is accomplished by process DataFrames to browse and process the data.
The Apache Spark DataFrame API provides an expensive set of functions (select columns, filter, join, aggregate, then on) that permit you to resolve common data analysis issues expeditiously.
DataFrames conjointly permits you to combine operations seamlessly with custom Python, SQL, R, and Scala code. Within the notebook experience in Azure Databricks, files can be read in a single command.
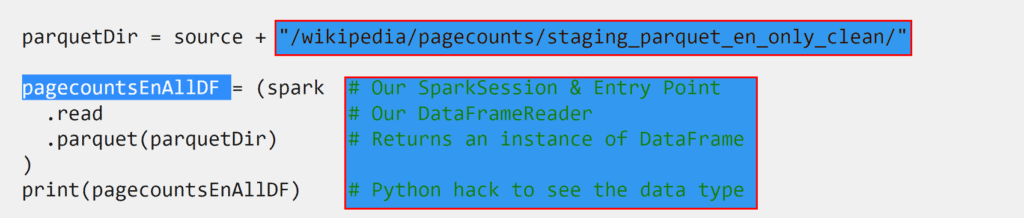
Ques 4: What is a DataFrame?
Ans: You could view DataFrames as you might see data in Microsoft Excel. It’s like a box with squares in it, that organizes data, which we could also refer to as a table of data. It is a single set of two-dimensional data that can have multiple rows and columns in the data. Each row is a sample of data. Each column is a variable or parameter that is able to describe the data.
DataFrames in Azure Databricks helps you move beyond simple data-handling functions by simplifying data exploration and perform data transformations. You can access numerous types of data sources and apply these same transformations, aggregates, and caching functions.
Ques 5: Can we also read data from SAP HANA using data bricks Spark or Python?
Ans: SAP HANA database may be accessed victimization the JDBC drivers. The Azure Databricks supports victimization of external libraries to attach to external systems, therefore the entire method is extremely straightforward! The JDBC adapter for SAP HANA is a component of the database consumer libraries and might be downloaded from the SAP Support Launchpad.
Your Databricks cluster is deployed to a similar virtual network because the SAP HANA database, therefore, doesn’t need to produce peering between vnets. With python script, you can read and displays data stored in the SFLIGHT table
Ques 6: External table also a persistent object?
Ans: No, data is not persistent but the metadata required to access that particular table is persistent.
Ques 7: Data frame- where it stores data Location?
Ans: No, it is a logical table, data is stored in the storage. Also, you can load data from Azure Blob Storage, Azure Data Lake Store Gen 2, and SQL pool. For example, you can ingest data into a Spark DataFrame by reading a CSV from an Azure Data Lake Storage Gen 2 as a Spark DataFrame
Ques 8: Cache similar to Buffer?
Ans: Yes, when you caching data, you are placing it on the worker of the cluster.
Ques 9: Is there a way to check the processing speed of CSV vs parquet files data?
Ans: When managing massive datasets, victimization traditional CSV or JSON formats to store data is very inefficient in terms of question speed and storage prices. Parquet format was nearly 2X quicker than victimization CSV!
Ques 10: What is the difference between Apache Spark for Synapse and Apache Spark?
Ans: Apache Spark for synapse is Apache Spark with other support for integrations with alternative services (AAD, AzureML, etc.) and extra libraries (mssparktuils, Hummingbird) and pre-tuned performance configurations.
Any work that’s presently running on Apache Spark can run on Apache Spark for Azure synapse while not modified.
Ques 11: How do I control dedicated SQL pools, serverless SQL pools, and serverless Spark pools?
Ans: As a starting point, Azure Synapse works with the built-in cost analysis and cost alerts available at the Azure subscription level.
| Dedicated SQL pools | Serverless SQL pools | Serverless Spark pools |
|
You have got observance and value management controls that allow you to cap defrayal at a daily, weekly, and monthly level.
|
You can restrict who can create Spark pools with Synapse RBAC roles
|
>Azure Synapse Analytics
Azure Synapse Analytics is a powerful analytics service provided by Microsoft that combines enterprise data warehousing, big data, and data integration into a single unified platform. It enables you to perform various data engineering tasks using Apache Spark.
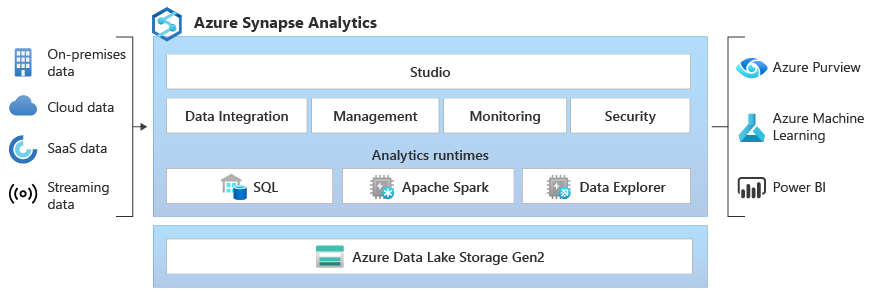
Q1: What are Azure Synapse Apache Spark Pools?
A: Azure Synapse Apache Spark Pools is a serverless Apache Spark offering in Azure Synapse Analytics, which provides a big data processing engine for data engineering and analysis tasks. It allows you to scale up or down based on your workload requirements without managing the underlying infrastructure.
Q2: How can I perform data engineering with Azure Synapse Apache Spark Pools?
A: To perform data engineering with Azure Synapse Apache Spark Pools, you can write Spark code using languages like Scala, Python, or SQL. You can use Spark APIs and libraries to read data from various sources, transform and clean the data, and load it into desired destinations.
Q3: Can I analyze data with Apache Spark in Azure Synapse Analytics?
A: Yes, you can analyze data with Apache Spark in Azure Synapse Analytics. Spark provides a wide range of analytical capabilities such as data exploration, aggregation, machine learning, and graph processing. You can leverage Spark’s distributed processing power to perform complex analytics on large datasets.
Q4: How can I transform data with Spark in Azure Synapse Analytics?
A: You can transform data with Spark in Azure Synapse Analytics by applying various data manipulation operations such as filtering, grouping, joining, and aggregating. Spark’s DataFrame and Dataset APIs provide a rich set of transformations that you can use to shape and modify your data.
Q5: What is Delta Lake in Azure Synapse Analytics?
A: Delta Lake is an open-source storage layer that provides ACID transactions, schema enforcement, and data versioning for big data workloads. It allows you to store data in a tabular format and provides reliability and consistency guarantees. Delta Lake is tightly integrated with Azure Synapse Analytics and can be used to build robust and scalable data pipelines.
Q6: How can I use Delta Lake in Azure Synapse Analytics?
A: You can use Delta Lake in Azure Synapse Analytics by leveraging the Delta Lake connector for Spark. This connector allows you to read and write data in Delta Lake format directly from Spark. You can use Delta Lake’s transactional capabilities to ensure data integrity and enable efficient data updates and deletes.
Q7: Can I use Azure Synapse Apache Spark Pools for real-time streaming data processing?
A: Azure Synapse Apache Spark Pools is primarily designed for batch processing and interactive analytics on large datasets. For real-time streaming data processing, you can leverage other Azure services such as Azure Stream Analytics, Azure Databricks, or Azure HDInsight with Apache Kafka integration.
Q8: What are the advantages of using Azure Synapse Apache Spark Pools?
A: Some advantages of using Azure Synapse Apache Spark Pools include automatic scaling to handle large workloads, serverless architecture for simplified management, tight integration with other Azure services, support for multiple programming languages, and access to a rich set of Spark libraries and APIs.
Q9: What is the difference between Enterprise applications and App Registrations?
A: App Registration is basically the apps local to the tenant/organization in which they have been registered to generate a unique application id.
Enterprise apps blade shows global apps (belonging to other tenants) which can be configured and used within your tenant/organization.
Q10: Do we need to mount ADL every time when cluster gets created?
A: Mount Azure Data Lake Storage Gen1 resource using a service principal and OAuth 2.0. You can mount an Azure Data Lake Storage Gen1 resource or a folder inside it to Databricks File System (DBFS).
The mount is a pointer to data lake storage, so the data is never synced locally.
Q11: Which cases do we need to register our application under Azure AD?
A: Applications are added to Azure AD to leverage one or more of the services it provides including Application authentication and authorization. User authentication and authorization. SSO using federation or password.
Q12: How can I change the type of column?
A: Changing a column’s type or dropping a column requires rewriting the table.
Q 13: What are the benefits of cache ()?
A: The ability to cache data is one technique for achieving better performance with Apache Spark.
This is because every action requires Spark to read the data from its source (Azure Blob, Amazon S3, HDFS, etc.) but caching moves that data into the memory of the local executor for “instant” access. cache() is just an alias for persist()
Q14: Need guidance/steps to resolve the issue “Pick an account — selected user account does not existing tenant ‘Microsoft Services’ and cannot access the application … in that tenant. The account needs to be added as an external user in the tenant first.”
A: You have multiple user accounts, and you are trying to log in with the wrong account that is why you face this error.
Q15: Display limit (100). Does it mean, it will display 100 lines from the top?
A: yes, and the display limit to 1000 rows.
Q16: Why a temporary view needs to create on top of DataFrame?
A: Apache Spark permits you to form a brief read employing a data frame. it’s rather like a read in an exceeding database. Once you have got a view, you’ll be able to execute SQL on that view.
Q17: What if the file having 1st row correct then 2nd row broken in between and 3rd row onwards having single value. how cleansing will work in such cases?
A: You need to write error handling logic to route the records that are not in the right format and filter the erroneous records.
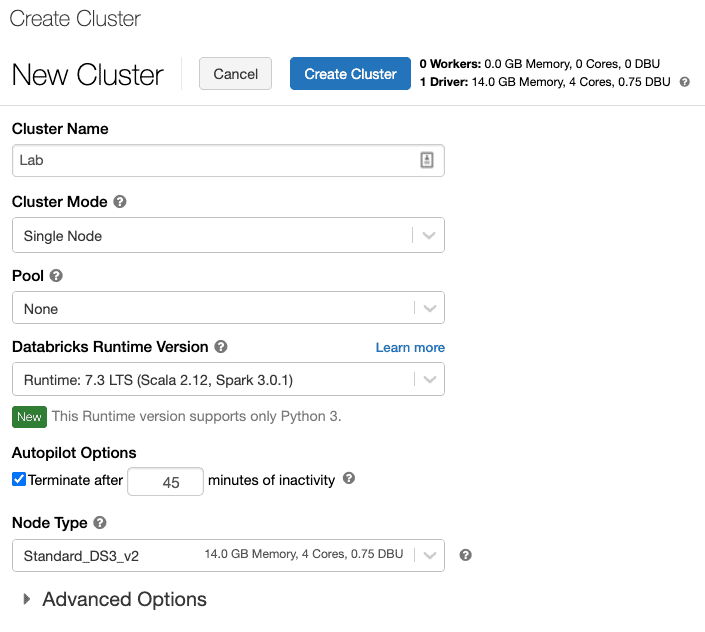
Q18: How can I create a Databricks cluster in the free account?
A: When your Azure Databricks workspace creation is complete, select the link to go to the resource.
- Select Launch space to open your Databricks space in a very new tab.
- In the left-hand menu of your Databricks space, choose Clusters.
- Select create Cluster to feature a brand new cluster.
- Enter a name for your cluster. Use your name or initials to simply differentiate your cluster from your coworkers.
- Select the Cluster Mode: Single Node.
- Select the Databricks RuntimeVersion: Runtime: 7.3 LTS (Scala 2.12, Spark 3.0.1).
- Under Autopilot Options, leave the box checked, and in the text box enter 45.
- Select the Node Type: Standard_DS3_v2.
- Select Create Cluster.
Q19: Compare Sql pool and spark pool?
A: SQL pool is a Big Data Solution that stores data in a relational table format with columnar storage. It also uses a Massive Parallel Processing (MPP) architecture to leverage up to 60 nodes to run queries.
An Apache Spark pool provides open-source big data compute capabilities.
Q20: What do you mean by executing access?
A: Execute permission on files means the right to execute them if they are programs. (Files that are not programs should not be given the execute permission.) For directories, execute permission allows you to enter the directory (i.e., cd into it), and to access any of its files.
Q21: If a user given write access will get read access also by default?
A: Yes if a user is given write access, then they can get read access also by default.
Also Check: Our blog post on Apache Spark Architecture.
Q22: What is Azure databricks?
A: Azure Databricks is a data analytics platform optimized for the Microsoft Azure cloud services platform. This new service, named Microsoft Azure Databricks, provides data science and data engineering teams with a fast, easy, and collaborative Spark-based platform on Azure.
Q23: How do Azure databricks fundamentally differ from Azure synapse?
A: They do have common ground to some extent, but they are not the same thing. Databricks is pretty much run by Apache Spark, whereas SQL Data Warehouse manages synapse Analytics
Q24: Why do we use databricks?
A: While Azure Databricks is ideal for massive jobs, it can also be used for smaller-scale jobs and development/ testing work. This allows Databricks to be used as a one-stop-shop for all analytics work. We no longer need to create separate environments or VMs for development work.
Q25: What is a control plane?
A: The control plane provides management and orchestration across an organization’s cloud environment. This is where configuration baselines are set, user and role access provisioned, and applications sit so they can execute with related services.
Q26: When using azure Databricks for ML/AI without a Dedicated SQL pool/DW, datalake will be utilized as Datawarehouse. am I right?
A: No Azure Databricks for ML/AI will not be utilized as Datawarehouse.
Q27: Is databricks a Platform?
A: Yes Databricks is a platform. Databricks provides a unified, open platform for all your data. It empowers data scientists, data engineers, and data analysts with a simple collaborative environment to run interactive, and scheduled data analysis workloads.
Q28: What are SSO credentials mean?
A: Single sign-on (SSO) is a session and user authentication service that permits a user to use one set of login credentials — for example, a name and password — to access multiple applications.
Q29: We do not necessarily need a pool to create a cluster, correct?
A: Yes, we can create a pool independently.
Q30: What is Databricks Community?
A: The Databricks Community Edition is the free version of our cloud-based big data platform. Its users can access a micro-cluster as well as a cluster manager and notebook environment. All users can share their notebooks and host them free of charge with Databricks.
Q31: How do cluster and pool work when executing this code
A: The clustered servers (called nodes) are connected by physical cables and by software. If one or more of the cluster nodes fail, other nodes begin to provide service (a process known as failover). In addition, the clustered roles are proactively monitored to verify that they are working properly.
Q32: Do we need to mount ADL every time when cluster gets created?
A: Mount Azure Data Lake Storage Gen2 resource using a service principal and OAuth 2.0. You can mount an Azure Data Lake Storage Gen1 resource or a folder inside it to Databricks File System (DBFS).
The mount is a pointer to data lake storage, so the data is never synced locally.
Check Out: Our blog post on Azure Data Engineer Interview Questions.
Feedback Received…
Here is some positive feedback from our trainees who attended the session:
Quiz Time (Sample Exam Questions)!
Ques: You need to create a new Azure Databricks cluster. This cluster would connect to Azure Data Lake Storage Gen2 by using Azure Active Directory (Azure AD) integration.
Which of the following advanced options would you enable?
A. Blob access control
B. Table access control
C. Credential Passthrough
D. Single Sign-On
Comment with your answer & we will tell you if you are correct or not!
References
- Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Azure Data Lake For Beginners: All you Need To Know
- Azure Data Engineer [DP-203] Q/A | Day 1 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 2 Live Session Review
- Azure Data Engineer,Data Science & Data Analyst Certifications: DP-900 vs DP-100 vs DP-203 vs DA-100A
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.


Leave a Reply