



![]()
This blog explains how to use Azure Data Factory Activities and Azure Synapse Analytics to build end-to-end data-driven workflows for your data movement and data processing scenarios.
One or more pipelines can exist in a Data Factory or Synapse Workspace. A pipeline is a logical collection of activities that work together to complete a task. A pipeline could, for example, have a collection of activities that ingest and clean log data before launching a mapping data flow to analyze the data.
Data movement activities, Data transformation activities, and Control activities are the three types of activities in Azure Data Factory and Azure Synapse Analytics. An activity can take one or more input datasets and output one or more datasets. An input dataset represents the input to a pipeline activity, while an output dataset represents the activity’s output.
1) Data Movement Activities
You may use the Copy Activity in Azure Data Factory and Synapse pipelines to copy data between on-premises and cloud data repositories. After you’ve copied the data, you can transform and examine it using different operations. The Copy activity can also be used to publish transformation and analysis findings for use in business intelligence (BI) and applications.
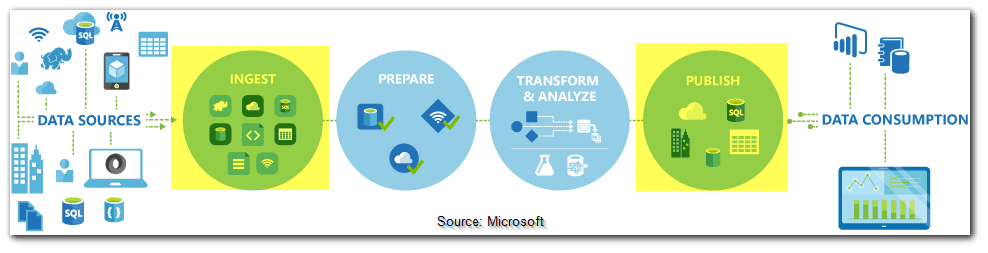
On an integration runtime, the Copy action is performed. For different data copy circumstances, you can employ different sorts of integration runtimes:
- You can use the Azure integration runtime to copy data between two data stores that are both publicly available over the internet from any IP address. This integration runtime is safe, dependable, scalable, and accessible from anywhere on the planet.
- You need to set up a self-hosted integration runtime when copying data to and from data stores on-premises or on a network with access control. For example, an Azure virtual network.
The service that executes the Copy activity follows these steps to copy data from a source to a sink:
- Data from a source data store is read.
- Serialization/deserialization, compression/decompression, column mapping, and other operations are performed. These procedures are carried out based on the input dataset, output dataset, and Copy activity configurations.
- Writes data to the data storage for the sink/destination.
You can use one of the following tools or SDKs to perform the Copy action using a pipeline:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
Read: Azure Resource Manager Template
A complete list of supported properties can be found in the Copy activity template below. Choose those that are appropriate for your situation.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
2) Data Transformation Activities
The following transformation activities are supported by Azure Data Factory and Azure Synapse Analytics and can be added separately or in a chain with another activity.
| Data transformation activity | Description |
| Data Flow | Use the Data Flow activity to transform and move data via mapping data flows. If you’re new to data flows |
| Azure Function | Azure Functions can be run in an Azure Data Factory or Synapse pipeline using the Azure Function activity. A linked service connection is required to launch an Azure Function. The linked service can then be used with an activity that specifies the Azure Function you want to run. |
| Hive | In an Azure Data Factory or Synapse Analytics pipeline, the HDInsight Hive activity runs Hive queries on your own or on-demand HDInsight cluster. |
| Pig | Pig queries are executed on your own or on-demand HDInsight cluster by the HDInsight Pig activity in a Data Factory pipeline. |
| MapReduce | Invokes MapReduce program on your own or on-demand HDInsight cluster using the HDInsight MapReduce activity in an Azure Data Factory or Synapse Analytics pipeline. |
| Hadoop Streaming | In an Azure Data Factory or Synapse Analytics pipeline, the HDInsight Streaming Activity runs Hadoop Streaming applications on your own or on-demand HDInsight cluster. |
| Spark | A Spark application is executed on your own or on-demand HDInsight cluster by the Spark activity in a data factory and Synapse pipelines. |
| ML Studio (classic) activities: Batch Execution and Update Resource | You can quickly develop pipelines that employ a published Machine Learning Studio (traditional) web service for predictive analytics with Azure Data Factory and Synapse Analytics. You can use the Batch Execution Activity in a pipeline to use the Machine Learning Studio (classic) web service to create predictions on the data in batch using the Machine Learning Studio (classic) web service. |
| Stored Procedure | It is not possible to use a copy activity to invoke a stored procedure while copying data into Azure Synapse Analytics. However, in Azure Synapse Analytics, you can use the stored procedure activity to call a stored procedure. |
| U-SQL | It consists of a series of activities, each of which performs a different processing procedure. |
| Custom Activity | You can construct a Custom activity with your own data movement or transformation logic and use it in a pipeline to move data to/from a data store that the service doesn’t support or to transform/process data in a way that the service doesn’t support. Your customized code logic is run on an Azure Batch pool of virtual machines via the custom activity. |
| Databricks Notebook | In your Azure Databricks workspace, the Azure Databricks Notebook Activity runs a Databricks notebook. |
| Databricks Jar Activity | A Spark Jar is launched on your Azure Databricks cluster when the Azure Databricks Jar Activity is used in a pipeline. |
| Databricks Python Activity | A Python file is run on your Azure Databricks cluster by the Azure Databricks Python Activity in a pipeline. |
Read: Azure Data Engineer Interview Questions [Updated – 2022]
3) Control flow activities
The activities listed below are supported by the control flow:
| Control activity | Description |
| Append Variable | Add a value to an array variable that already exists. |
| Execute Pipeline | A Data Factory or Synapse pipeline can use the Execute Pipeline activity to call another pipeline. |
| Filter | Apply a filter expression to an array of inputs. |
| For Each | In your pipeline, the ForEach Activity defines a repeated control flow. This activity iterates over a collection in a loop, executing specified activities. This activity’s loop implementation is comparable to the Foreach looping structure used in programming languages. |
| Get Metadata | The GetMetadata activity in a Data Factory or Synapse pipeline can be used to retrieve metadata for any data. |
| If Condition Activity | If you want to branch based on whether a condition is true or false, you can use the If Condition. In computer languages, an if statement provides the same functionality as the If Condition activity. When the condition is true, it evaluates a set of activities; when the condition is false, it examines another set of activities. |
| Lookup Activity | Any external source can be utilized to read or look up a record/table name/value using the Lookup Activity. Following operations can use this output as a reference point. |
| Set Variable | Set the value of a variable that already exists. |
| Until Activity | Implements a Do-Until loop that is similar to programming languages’ Do-Until looping structure. It loops over a series of tasks until the condition linked with each one evaluates to true. For the till activity, you can choose a timeout value. |
| Validation Activity | Ensure that a pipeline only runs until a reference dataset is found, a set of conditions is met, or a timeout is reached. |
| Wait Activity | When you use a Wait activity in a pipeline, it waits for the specified amount of time before moving on to the next activity. |
| Web Activity | A pipeline can use Web Activity to call a custom REST endpoint. Datasets and related services can be passed to the activity to be consumed and accessible. |
| Webhook Activity | Call an endpoint and pass a callback URL using the webhook activity. Before moving on to the next activity, the pipeline waits for the callback to be executed. |
Frequently Asked Questions
Q: What is Azure Data Factory?
A: Azure Data Factory is a cloud-based data integration service provided by Microsoft. It allows you to create, schedule, and manage data pipelines that can move and transform data from various sources to different destinations.
Q: What are the key features of Azure Data Factory?
A: Azure Data Factory offers several key features, including data movement and transformation activities, data flow transformations, integration with other Azure services, data monitoring and management, and support for hybrid data integration.
Q: What are the benefits of using Azure Data Factory?
A: Some benefits of using Azure Data Factory include the ability to automate data pipelines, seamless integration with other Azure services, scalability to handle large data volumes, support for on-premises and cloud data sources, and comprehensive monitoring and logging capabilities.
Q: How does Azure Data Factory handle data movement?
A: Azure Data Factory uses data movement activities to efficiently and securely move data between various data sources and destinations. It supports a wide range of data sources, such as Azure Blob Storage, Azure Data Lake Storage, SQL Server, Oracle, and many others.
Q: What is the difference between Azure Data Factory and Azure Databricks?
A: While both Azure Data Factory and Azure Databricks are data integration and processing services, they serve different purposes. Azure Data Factory focuses on orchestrating and managing data pipelines, while Azure Databricks is a big data analytics and machine learning platform.
Q: Can Azure Data Factory be used for real-time data processing?
A: Yes, Azure Data Factory can be used for real-time data processing. It provides integration with Azure Event Hubs, which enables you to ingest and process streaming data in real time.
Q: How can I monitor and manage data pipelines in Azure Data Factory?
A: Azure Data Factory offers built-in monitoring and management capabilities. You can use Azure Monitor to track pipeline performance, set up alerts for failures or delays, and view detailed logs. Additionally, Azure Data Factory integrates with Azure Data Factory Analytics, which provides advanced monitoring and diagnostic features.
Q: Does Azure Data Factory support hybrid data integration?
A: Yes, Azure Data Factory supports hybrid data integration. It can connect to on-premises data sources using the Azure Data Gateway, which provides a secure and efficient way to transfer data between on-premises and cloud environments.
Q: How can I schedule and automate data pipelines in Azure Data Factory?
A: Azure Data Factory allows you to create schedules for data pipelines using triggers. You can define time-based or event-based triggers to automatically start and stop data pipeline runs.
Q: What security features are available in Azure Data Factory?
A: Azure Data Factory provides several security features, including integration with Azure Active Directory for authentication and authorization, encryption of data at rest and in transit, and role-based access control (RBAC) to manage access to data and pipelines. Please note that these FAQs are intended to provide general information about Azure Data Factory, and for more specific details, it is recommended to refer to the official Microsoft documentation or consult with Azure experts.
Related/References
- Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Exam DP-203: Data Engineering on Microsoft Azure
- Azure Data Lake For Beginners: All you Need To Know
- Batch Processing Vs Stream Processing: All you Need To Know
- Introduction to Big Data and Big Data Architectures
- Delta Lake Architecture & Azure Databricks Workspace
- Copy Data From Azure Blob Storage To A SQL Database
- Azure Databricks, Apache spark & Azure Databricks Architecture Overview
- Azure Synapse Analytics
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.





![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)




