




![]()
This blog post will give a quick understanding of Custom AI Algorithms. The Microsoft Azure AI Fundamentals AI-900 Certification is for all those who are looking forward to starting working with or shifting their career in Azure AI and Machine Learning domain.
The previous week, In the Day 1 session, we got an overview of Artificial Intelligence in Azure, Responsible AI, Azure Machine Learning, and basics of Azure AI-900 Fundamentals.
And in this week’s he following topics are covered in this blog in the Azure AI-900 Custom AI algorithms, Classification, Clustering, Compute, and Automated ML
Here are the questions that we discussed in Day 2 Session:
Custom AI
Customize and embed state-of-the-art computer vision image analysis for specific domains with Custom Vision, part of Azure Cognitive Services. Build frictionless customer experiences, optimize manufacturing processes, accelerate digital marketing campaigns, and more. No machine learning expertise is required.
Why use Custom AI on Azure?
Customers can choose to use Azure at any layer of the stack.
Generally speaking, users may want to use the Custom AI on Azure because they want to build their AI solution easy, flexible & customizable way, Time saving, Additionally, many of the tools, algorithms and services are provides by Custom AI on Azure AI-900.
Example – In conversational AI we make Chatbots, E-mail filtering with the help of Custom AI algorithms
|
|
Custom AI on Azure | Cognitive Services |
| Compliance & Security | Mature | Less Mature |
| Flexibility & Customizability | High | Low |
| Costs | Low | High |
*The table above compares the categories in a general sense*
Also Check: Object Detection And Tracking In Azure ML
Here are some FAQs:
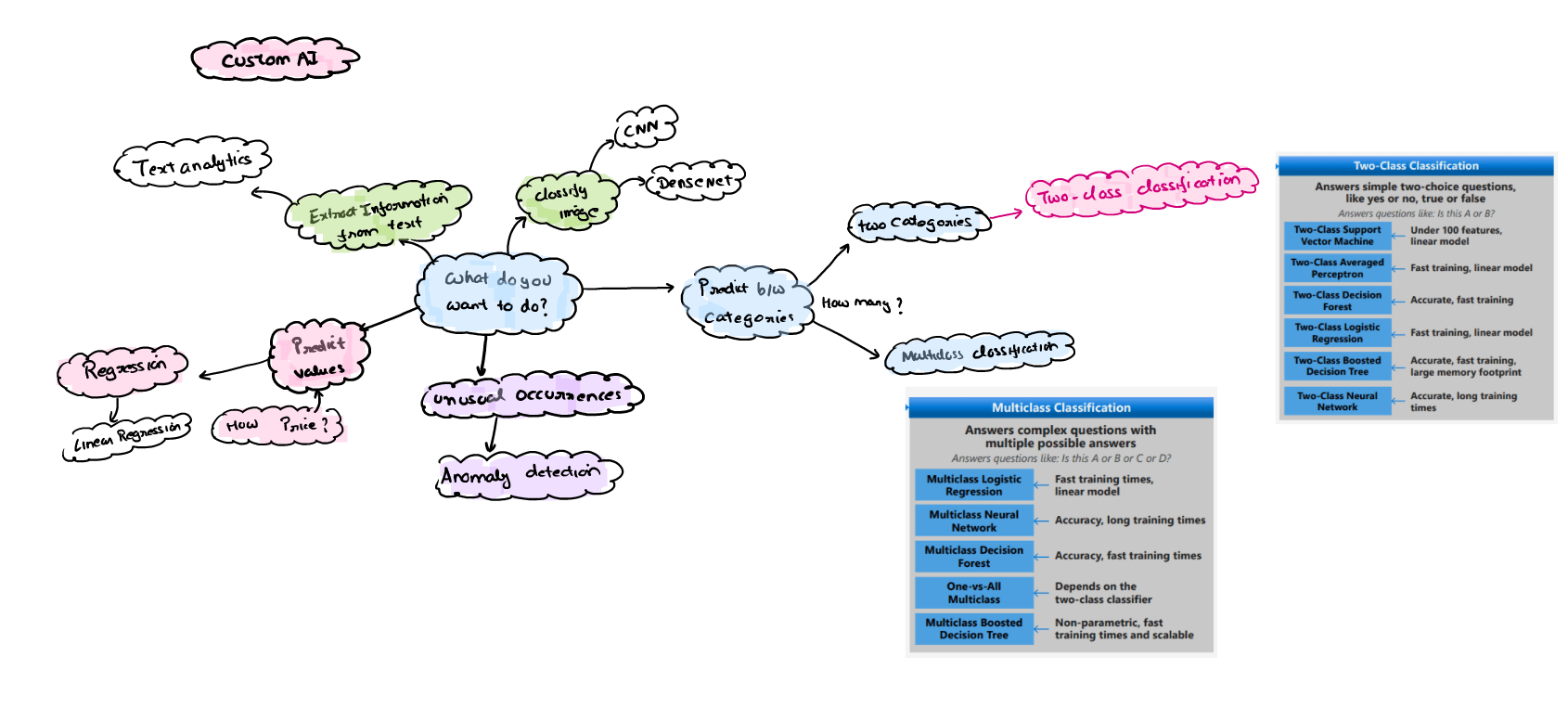
Q.1 Explain Lifecycle or flow chat of Custom AI Algorithms?
Ans. Let understand few points in the above figure:
- So, if you want to find unusual occurrences and errors in the model = We use Anomaly detection.
- Predict value = Regression Algorithm is used
- Extract information from text = Text analytics
- You want to do image classification = so we have CNN and Dense Net algorithm
- Predict b/w categories = we have Two-class classification and multiclass- classification.
Regression: Regression is a Supervised ML Algorithm
Regression analysis consists of a set of machine learning methods that allow us to predict a continuous outcome variable (y) based on the value of one or multiple predictor variables (x).
Briefly, the goal of the regression model is to build a mathematical equation that defines y as a function of the x variables. Next, this equation can be used to predict the outcome (y) on the basis of new values of the predictor variables (x). It is a problem when the output variable work on a real value of the dataset is provided. Like: Doller dataset, covid19 cases dataset, the weight of humans, age, salary, etc.
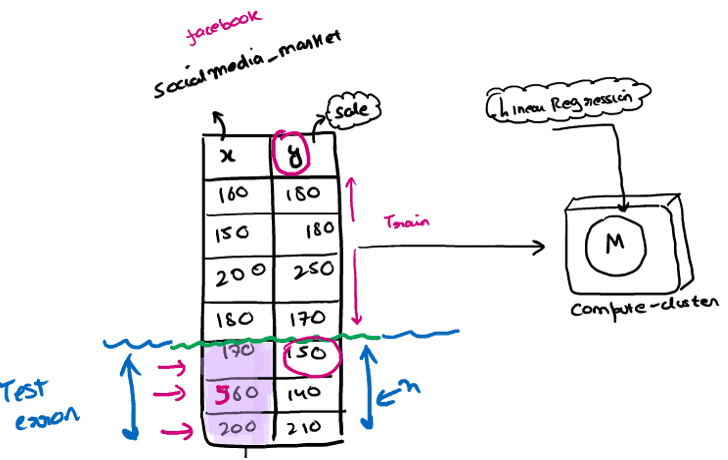
Example: Suppose there is a social media marketing company K21 Academy, which conducts various workshops every weekend or year and gets sales on that. The below list shows the workshop made by the company in the last 5 years and the corresponding sales:
Here are some FAQs:
Q.1 What are Underfitting and Overfitting?
Ans. Overfitting: If our algorithm works well with the training dataset but not well with the test dataset, then such a problem is called Overfitting.
Underfitting: If our algorithm does not perform well even with the training dataset, then such a problem is called underfitting.
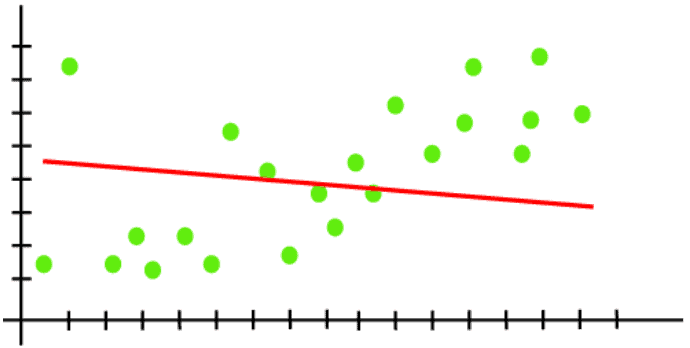
Q.2 What is Linear Regression?
Ans. Linear regression is a statistical regression method that is used for predictive analysis value.
- It is one of the very simple and easy algorithms which works on regression.
- It is used for solving the regression problem in machine learning.
- Linear regression shows the linear relationship between the independent variable (X-axis) and the dependent variable (Y-axis), hence called linear regression.
- If there is only one input variable (x), then such linear regression is called simple linear regression. And if there is more than one input variable, then such linear regression is called multiple linear regression.
The relationship between variables in the linear regression model can be explained using the below image. Here we are predicting the salary of an employee on the basis of the social media market.
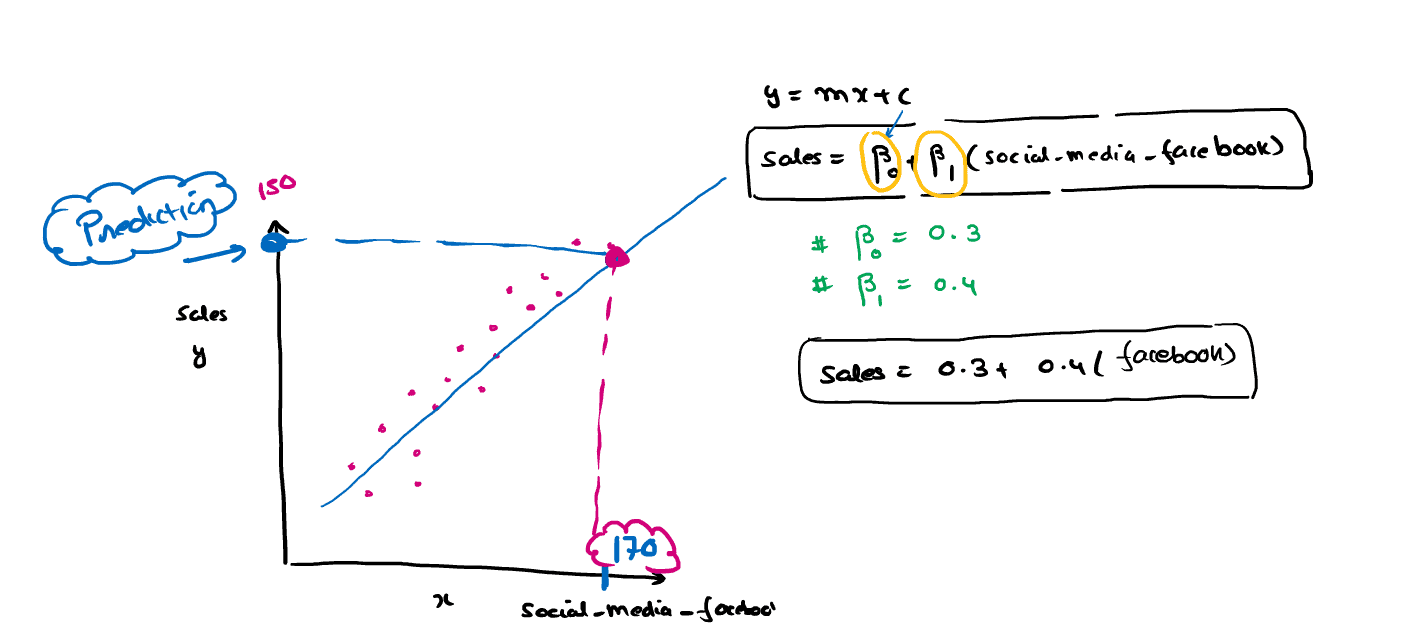
How mathematical operation perform = Y= mx+c
Where-
Y – Dependent variables (target variable),
x- Independent variables (predictor variable),
m and c the linear coefficients
Q.3 How to find and predict errors in the model?
Ans. The best model is defined as the model that has the lowest prediction error. The most popular metrics for the regression include:
- Residual sum of square
- Mean Squared Error
- Root mean square error.
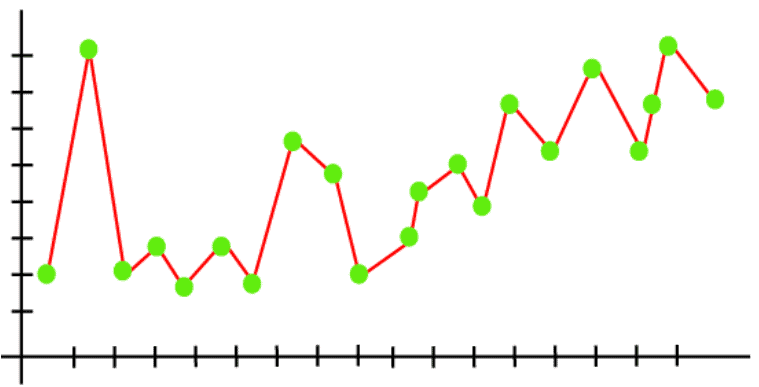
Suppose we want to find the errors in the model so by this graph we can see-
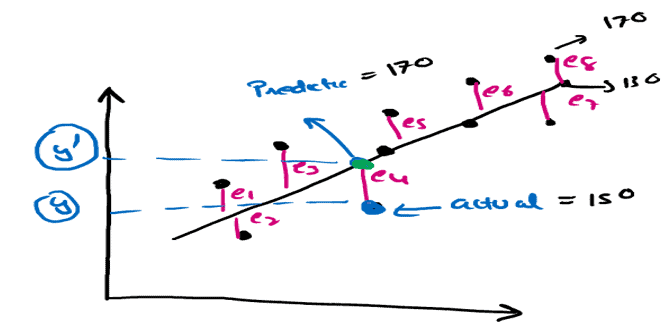
Q.4 What is Mean Absolute Error (MAE)?
Ans. The average difference between predicted values and true values. This value is based on the same units as the label, in this case, dollars. The lower this value is, the better the model is predicting.
Q.5 What is the Residual sum of square (RSS)?
Ans. If we reduced RSS then the line gives us through, they possible its cab be. RSS does not tell the actual error, It tells the total error in the model.
Formula:

where, RSS- Residual sum of squares,  – i^th value of the variable to be predicted,
– i^th value of the variable to be predicted,  – the predicted value of y_i, and n- the upper limit of summation
– the predicted value of y_i, and n- the upper limit of summation
Q.6 What is Mean Squared Error (MSE)?
Ans. Mean Squared Error represents the average of the squared difference between the original and predicted values in the data set. It measures the variance of the residuals.
Formula:

where, MSE- Mean Squared errors, n- number of data points,  – observed values, and
– observed values, and  – predicted values
– predicted values
Q.7 What is Root Mean Squared Error (RMSE)?
Ans. Root Mean Squared Error is the square root of Mean Squared error. It measures the standard deviation of residuals.
Formula:
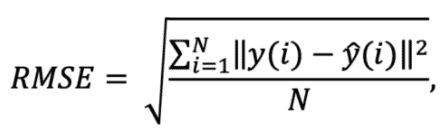
where, N- is the number of data points, y(i)- is the ith measurement, and y ̂(i)- is its corresponding prediction.
Note: RMSE is NOT scale-invariant and hence comparison of models using this measure is affected by the scale of the data. For this reason, RMSE is commonly used over standardized data.
Q.8 _______model to predict the numeric value. Fill this blank?
Ans. Regression
Classification:
Classification is a Supervised ML Algorithm technique It is problem in which when the output variable is divided such as “Red or Blue”, “diseases or No- diseases”.
It is used to identify the category of new observations on the basis of training data. In Classification, a program learns from the given dataset or observations and then classifies new observations into a number of classes or groups. Such as, Yes or No, 0 or 1, Spam or Not Spam, cat or dog, etc. Classes can be called targets/labels or categories.
Use cases of Classification Algorithms =
- Email Spam Detection
- Speech Recognition
- Biometric Identification, etc.
Here are some FAQs:
Q.1 Explain types of Classifiers?
Binary Classifier: If the classification problem has only two possible outcomes.
Examples: YES or NO, MALE or FEMALE, etc.
Multi-class Classifier: If a classification problem has more than two outcomes.
Example: Classification of types of music etc.
In classification algorithm, a discrete output function(y) is mapped to input variable(x).
Q.2 What is Logistic Regression?
Ans. It is used for predicting the categorical dependent variable using a given set of independent variables. Logistic regression predicts the output of a categorical dependent variable. Therefore, the outcome must be a categorical or discrete value. It can be either yes or no, 0 or 1, true or False.
- Logistic Regression is much similar to Linear Regression except that how they are used. Linear Regression is used for solving Regression problems, whereas Logistic regression is used for solving the classification problems.
- The curve from the logistic function indicates the likelihood of something such as whether the cells are cancerous or not, a mouse is obese or not based on its weight, etc.
- Logistic Regression is a significant machine learning algorithm because it has the ability to provide probabilities and classify new data using continuous and discrete datasets.
The below image is showing the logistic function graph:
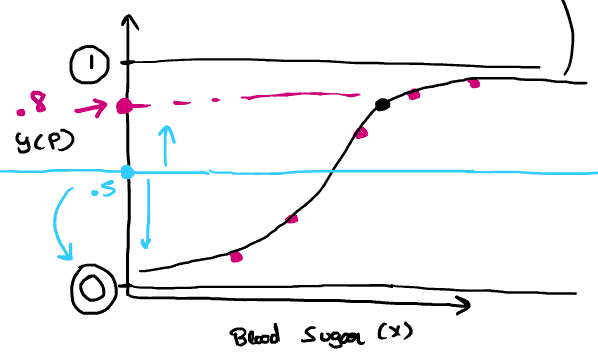
where y(p) =
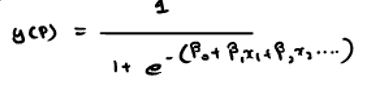
Q.3 What is a confusion matrix?
Ans. The confusion matrix provides us a matrix/table as output and describes the performance of the model. It is also known as the error matrix. The matrix consists of predictions result in a summarized form, which has a total number of correct predictions and incorrect predictions. The matrix looks as below table:
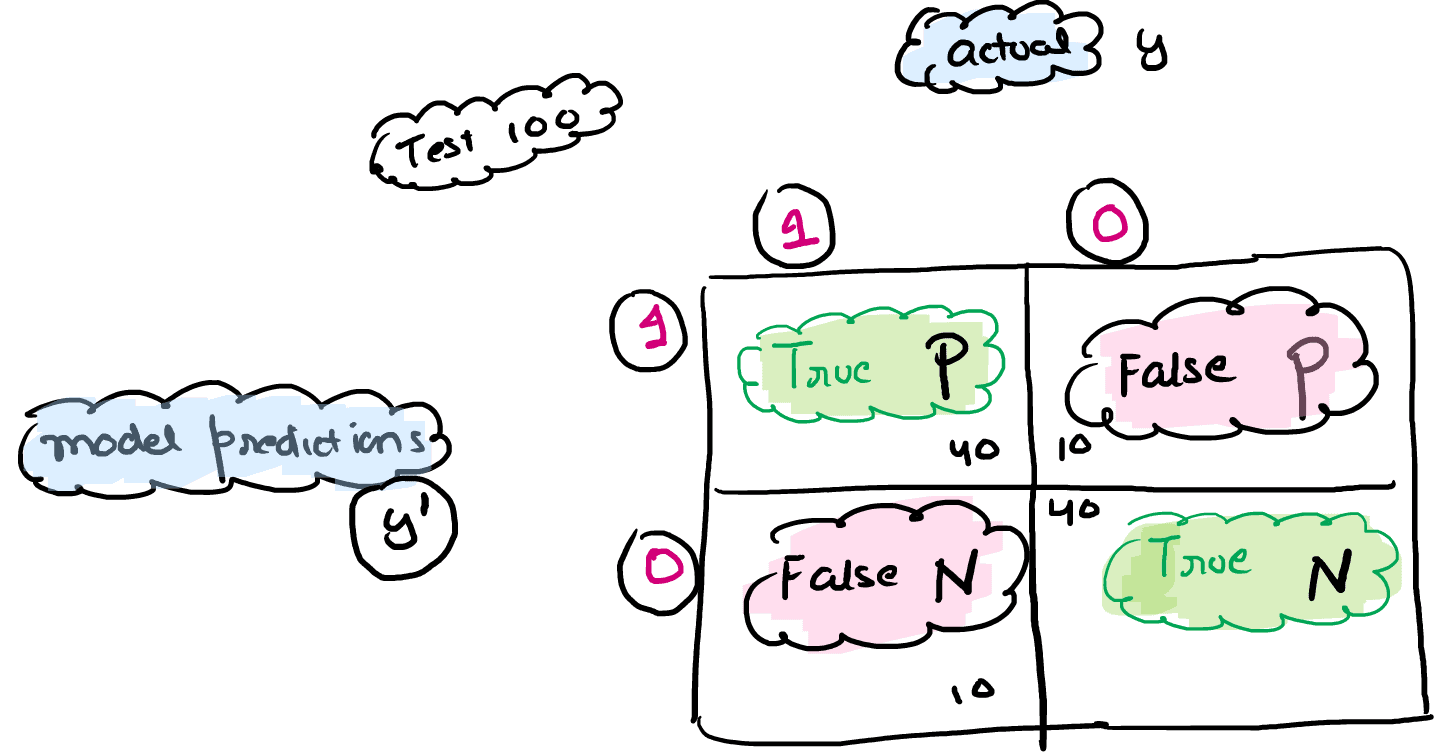
To find Accuracy we have a formula:
Accuracy = TP+TN/TP+TN+FP+FN
Example: 40+40/100 = 80%
Recall = When it was actually correct How many times your model correctly predicted
Recall: TP/TP+FN
Precision = When your model says
Precision: TP/TP+FP
Q.4. A bank wants to use historic loan repayment records to categorize loan applications as low-risk or high-risk based on characteristics like the loan amount, the income of the borrower, and the loan period. What kind of machine learning model does the bank need to create?
Ans. Classification
Q.5 A health clinic might use the characteristics of a patient (such as age, weight, blood pressure, and so on) to predict whether the patient is at risk of diabetes. In this case, the characteristics of the patient are the features, and the label is a classification of either 0 or 1, representing non-diabetic or diabetic. What kind of model is this?
Ans. Classification
Clustering
Clustering is an unsupervised machine learning technique used to group similar entities based on their features. It is a way of grouping the data points into different clusters, consisting of similar data points. The objects with the possible similarities remain in a group that has fewer or no similarities with another group.
For example, a researcher might take measurements of penguins, and group them based on similarities in their proportions. Suppose we have three clusters of penguins.
Source: Microsoft
Here are some FAQs:
Q.1 What are K-Mean Clustering Algorithms?
Ans. The k-means algorithm is one of the most popular clustering algorithms. It classifies the dataset by dividing the samples into different clusters of equal variances. The number of clusters must be specified in this algorithm. It is fast with fewer computations required.
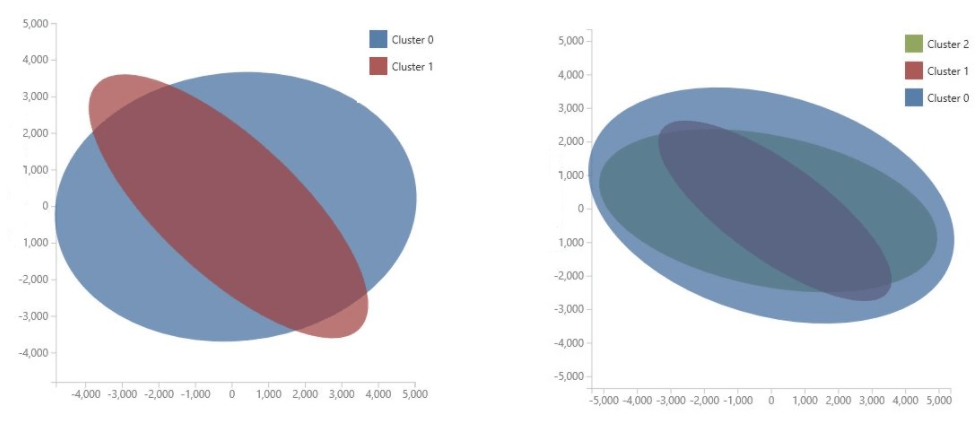
For example- the following PCA charts represent the results from two models trained using the same data: the first was configured to output two clusters, and the second was configured to output three clusters. From these charts, you can see that increasing the number of clusters did not necessarily improve the separation of the classes.
Working of Simple Clustering –
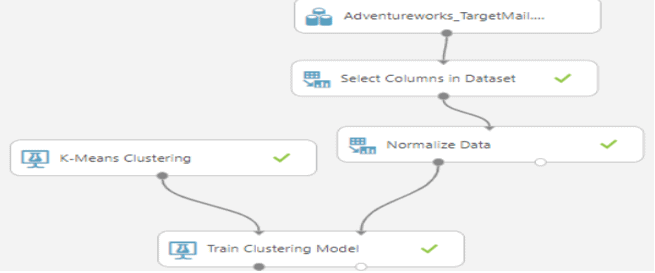
Source: Microsoft
Q.2 _______ is a form of machine learning that is used to group similar items into clusters based on their features?
Ans. Clustering
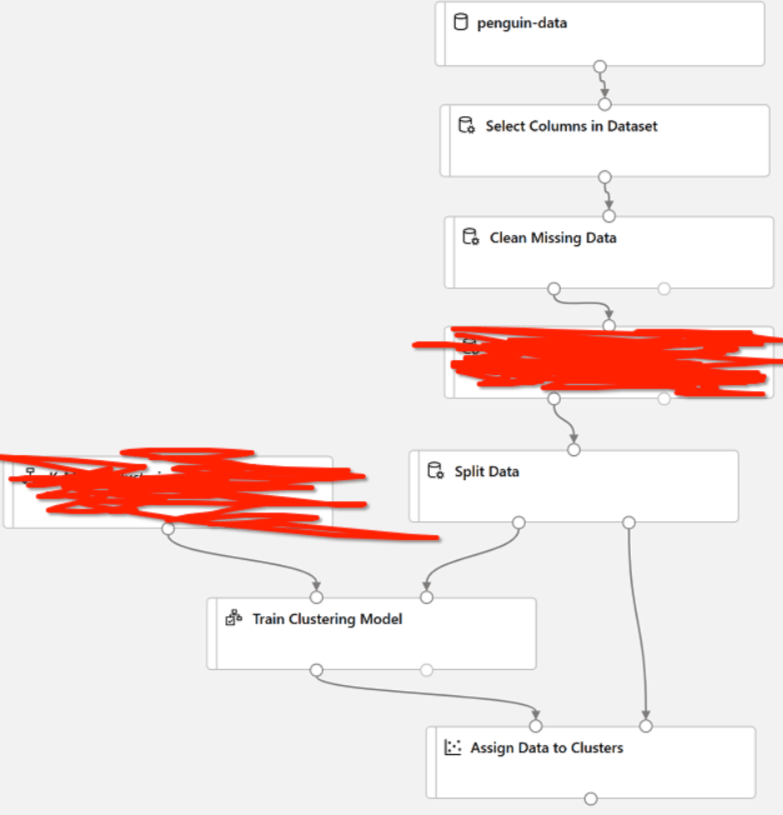
Q.3 To train a clustering model, you need to apply a clustering algorithm to the data, using only the features that you have selected for clustering. You’ll train the model with a subset of the data, and use the rest to test the trained model. This is the complete pipeline for clustering what are the missing modules in the following pipeline?
Source: Microsoft
Ans. Normalize Data
K-Means Clustering
> Compute
Azure comput is an on-demand computing service for running cloud-based applications. It provides computing resources like multi-core processors and supercomputers via virtual machines and containers. It also provides serverless computing to run apps without requiring infrastructure setup or configuration. The resources are available on-demand and can typically be created in minutes or even seconds. You pay only for the resources you use and only for as long as you’re using them.
There are four common techniques for performing compute in Azure:
- Virtual machines
- Containers
- Azure App Service
- Serverless computing
Here are some FAQs:
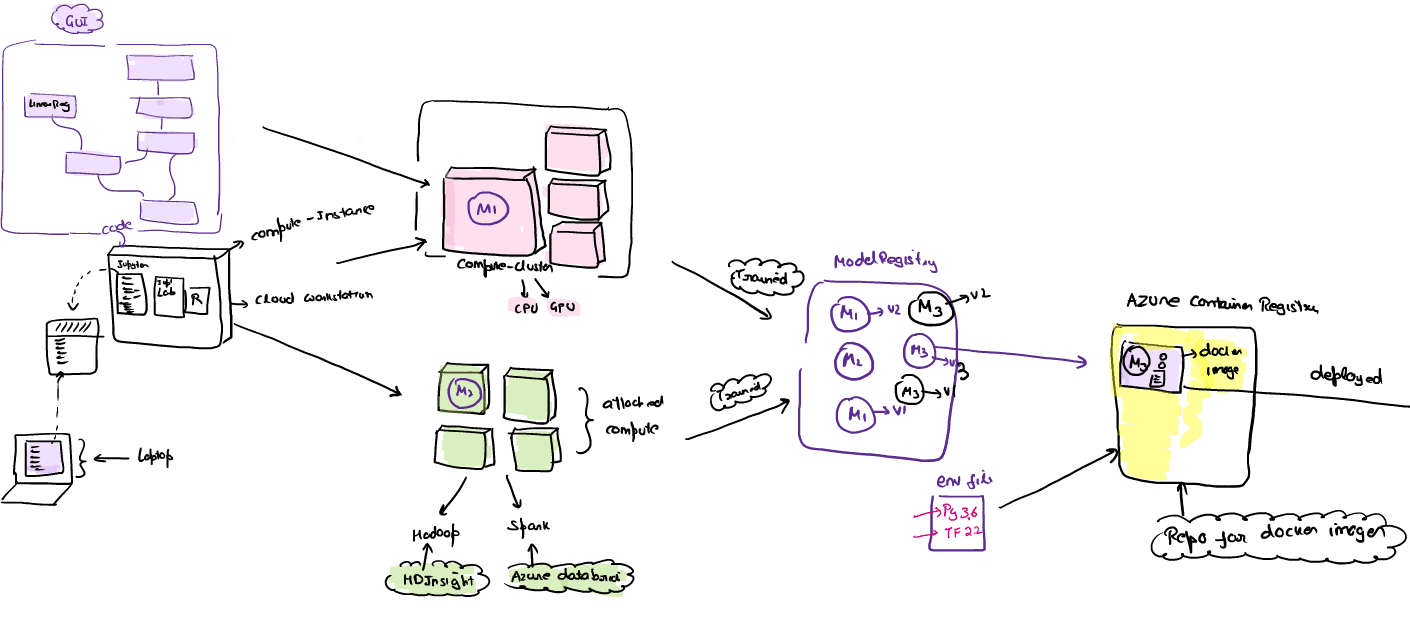
Q.1 How to computation works?
Ans. Step -1
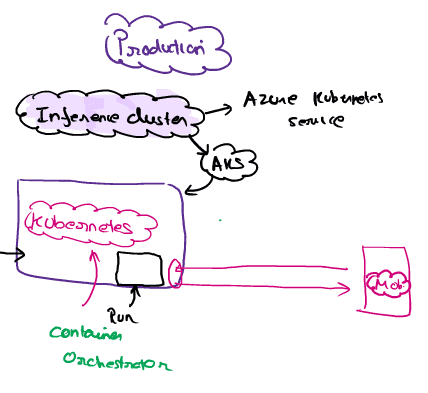
Step-2 we want to deploy and production –
> Automated ML:
Q.1 How to Train a regression model with Automated ML and how it works?
Ans. Automated machine learning, also referred to as automated ML or Automated ML, is the process of automating the time-consuming, iterative tasks of machine learning model development. It allows data scientists, analysts, and developers to build ML models with high scale, efficiency, and productivity all while sustaining model quality. Automated ML in Azure Machine Learning is based on a breakthrough from our Microsoft AutoML
Traditional machine learning model development is resource-intensive, requiring significant domain knowledge and time to produce and compare dozens of models. With automated machine learning, you’ll accelerate the time it takes to get production-ready ML models with great ease and efficiency.
When to use Automated ML: classify, regression, & forecast

Source: Microsoft
Also Check: Automated Machine Learning
Quiz Time (Sample Exam Questions)!
Question. A bank wants to use historic loan repayment records to categorize loan applications as low-risk or high-risk based on characteristics like the loan amount, the income of the borrower, and the loan period. What kind of machine learning model does the bank need to create?
1: Classification
2: Regression
3: Clustering
4: Time Series Forecasting
Answer- 1
Question. Can we import our own algorithms?
Ans. Yes.
Question. You plan to use the Custom Vision service to train an image classification model. You want to create a resource that can only be used for model training, and not for prediction. Which kind of resource should you create in your Azure subscription?
1: Custom Vision
2: Cognitive Services
3: Computer Vision
4: None of these
Answer- 1
Explanation: When you create a Custom Vision resource, you can specify whether it is to be used for training, prediction, or both.
Question. You want to use the Computer Vision service to analyze images. You also want to use the Text Analytics service to analyze text. You want developers to require only one key and endpoint to access all of your services. What kind of resource should you create in your Azure subscription?
1: Computer Vision
2: Cognitive Services
3: Custom Vision
4: None of these
Answer: 2
Question. Which of the following types of machine learning is an example of unsupervised machine learning?
1: Classification
2: Regression
3: Clustering
4: Time Series Forecasting
Answer: 3
Related/References:
- In Azure Machine Learning how-to-select-algorithms
- Microsoft Azure AI Fundamentals [AI-900]: Step By Step Activity Guides (Hands-On Labs)
- Machine Learning algorithm cheat-sheet
Next Task For You
To know more about AI, ML, Data Science for beginners, why you should learn, Job opportunities, and what to study to clear Microsoft Azure AI Fundamentals Certification [AI-900].
Click on the below image to Register for our FREE Class on AI, ML, and Data Science for Beginners Azure Certifications | Live Demo & Q/A
Now to start your Artificial Intelligence journey as a beginner!






![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



