




![]()
Natural Language Processing (NLP) is applying Machine Learning models to text and language. Teaching machines to grasp what’s said within the spoken and written word is the focus of Natural Language Processing.
Every time when you dictate something into your iPhone/Android device it truly is then converted to text, that’s an NLP set of rules in action.
In this blog, we are going to cover everything about:
What Is Natural Language Processing?
- Natural language processing (NLP) refers to the branch of computer science and more specifically, the department of AI, concerned with giving computers the capacity to recognize the text and spoken phrases in a great deal the same way people can.
- We can use NLP to developing systems like machine translation, speech recognition, spam detection, sentiment analysis, text simplifications, and plenty more.
- Few Real-Time examples include:
- Google Translate
- Grammarly
- Cortana
- Alexa
- OK Google

Why is natural language processing important for businesses?
Natural Language Processing (NLP) helps businesses understand customer sentiment, automate tasks, improve customer service, and gain insights from large volumes of unstructured data. It enhances decision-making, personalizes customer experiences, and drives efficiency, contributing to competitive advantage.
What is natural language generation (NLG) and how is it applied?
Natural Language Generation (NLG) is an AI-driven process that converts structured data into human-readable text. It’s used in various applications like automated report generation, chatbots, personalized marketing, and data summaries, enhancing efficiency and communication in businesses.
How did NLP develop from the 1950s to the 1990s?
From the 1950s to the 1990s, NLP evolved from rule-based systems and early machine translation efforts to statistical models, such as Hidden Markov Models. The 1980s introduced syntactic parsing, while the 1990s saw a shift to probabilistic models and corpora-based learning.
What is the historical evolution of natural language processing?
Natural Language Processing (NLP) evolved from early rule-based systems in the 1950s, advancing through statistical models in the 1990s, to modern deep learning techniques. Recent innovations include transformer models like BERT and GPT, enhancing contextual language understanding.
How Does Machine Understand Text?
- We do know that machines only understand numbers i.e. 010101 not words or sentences.
- So, before building Natural language processing models, we want to specialize in an intermediate step, which is the text representation.
- Text representation was created on a basic idea, which is one-hot encodings.
- In one-hot encodings, a sentence is represented as a matrix of shape (NxN) where N represents the number of particular tokens within the sentence.
- For example, in the below picture, each word is expressed as sparse vectors except one cell (occurrences of the word in the sentence).
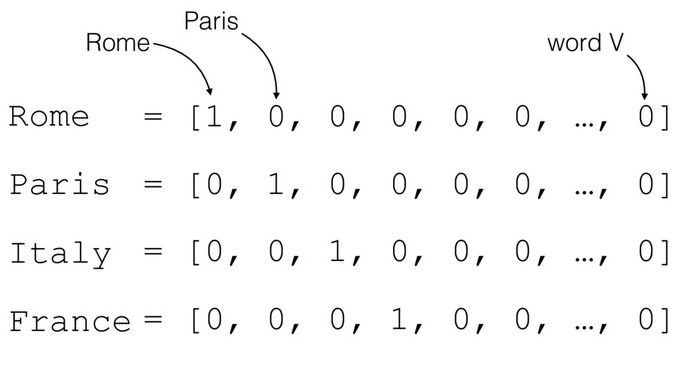
Parts of NLP (Natural Language Processing)
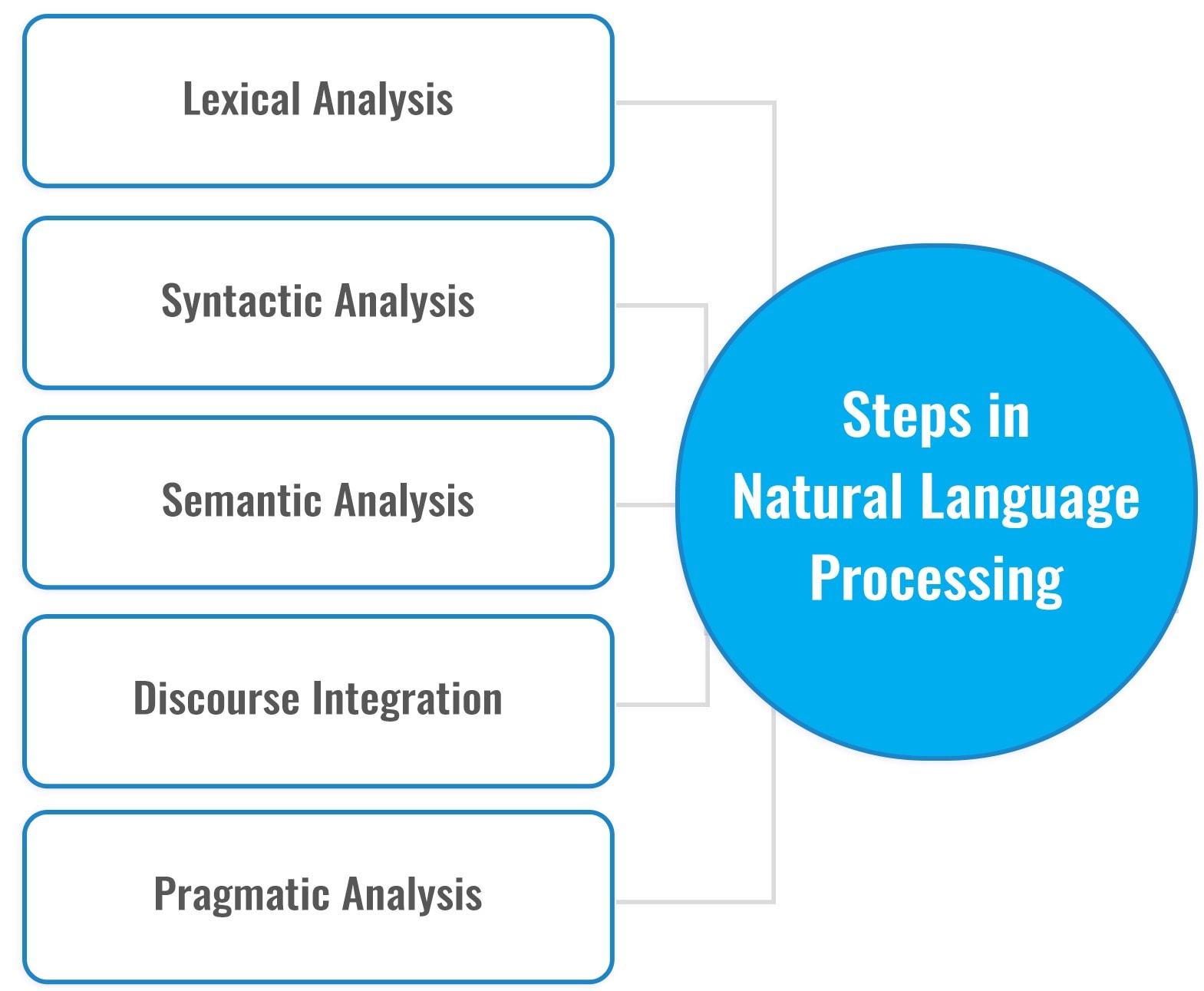
1) Lexical Analysis: With Lexical Analysis, we divide a complete part of the text into paragraphs, sentences, and words, which involves identifying and analyzing the structure of words.
2) Syntactic evaluation: The syntactic analysis includes the evaluation of phrases in a sentence for grammar and arranging phrases in a way that suggests the connection of many of the phrases. as an example, the sentence “the shop is going to the house” does no longer passes.
3) Semantic evaluation: Semantic evaluation attracts the precise meaning for the words, and it analyzes the textual content meaningfulness. Sentences that include “hot ice-cream” do now not skip.
4) Disclosure Integration: Disclosure integration takes into consideration the context of the text. It considers the which means of the sentence before it ends. as an instance: “He works at Google.” in this sentence, “he” needs to be referenced within the sentence earlier than it.
5) Pragmatic evaluation: Pragmatic evaluation offers normal conversation and interpretation of language. It offers with deriving meaningful use of language in diverse conditions.
How can NLP improve the interpretation of vague language elements?
NLP can improve the interpretation of vague language elements by utilizing techniques like semantic analysis, context modeling, and machine learning to clarify ambiguous terms, resolve meaning inconsistencies, and provide more precise insights for effective communication and decision-making.
How does the evolving use of language impact NLP?
The evolving use of language, driven by cultural shifts, technology, and globalization, impacts NLP by requiring models to adapt to new vocabulary, slang, idioms, and context. This ongoing change challenges NLP systems to remain accurate and contextually relevant.
What is named entity recognition (NER) in NLP?
Named Entity Recognition (NER) in NLP is a technique used to identify and classify key entities, such as names, dates, locations, and organizations, from text. It helps extract meaningful information, improving text analysis and enabling structured data extraction.
Why is tone of voice and inflection challenging for NLP?
Tone of voice and inflection are challenging for NLP because they convey nuanced emotions, intent, and context, which text-based models struggle to interpret. Without vocal cues, NLP systems may misinterpret the meaning behind phrases, leading to inaccurate responses.
How does word sense disambiguation work in NLP?
Word sense disambiguation (WSD) in NLP is the process of determining the correct meaning of a word based on its context. It uses algorithms, such as machine learning or rule-based methods, to resolve ambiguities in word meanings effectively.
Natural Language Processing Algorithms
Before diving into the coding part, we will first understand the concepts beneath them. The foremost frequently used algorithms in Natural language processing when defining the vocabulary of terms:
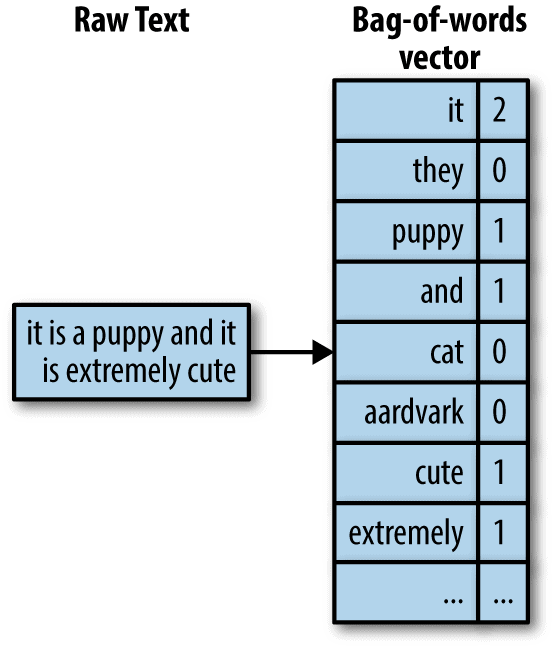
1) Bag of Words
- Is a regularly used model that permits us to count all words in a piece of text. Basically, it makes an occurrence matrix for the sentence or document, disregarding grammar, and word order.
- These word occurrences or frequencies are then used as features for training a classifier.
2) Tokenization
- The process of separating the running text into sentences and words is termed Tokenization. Basically, it’s the task of cutting a text into items called tokens, and at the same time push away certain characters, like punctuation.

3) Lemmatization
- Lemmatization settles words into their dictionary form for which it needs detailed dictionaries in which the algorithm can view and link words to their corresponding form.

4) Stemming
- In this process, we slicing the end or the beginning of words with the purpose of removing affixes.
- The issue is that affixes can make or expand new forms of the same word or even make new words themselves.

What issues can bias cause in NLP systems?
Bias in NLP systems can lead to unfair, discriminatory outcomes, reinforcing stereotypes, and marginalizing certain groups. It may also affect decision-making, perpetuating social inequalities, and reducing the effectiveness of models, ultimately compromising the reliability and fairness of AI-driven solutions.
How does natural language generation function in NLP applications?
Natural Language Generation (NLG) in NLP applications uses AI to automatically produce human-like text from structured data. It involves algorithms that interpret data patterns and generate coherent, contextually appropriate sentences, aiding in tasks like report writing, content creation, and chatbots.
How has deep learning influenced current NLP approaches?
Deep learning has revolutionized NLP by enabling models like transformers (e.g., GPT, BERT) to better understand context, semantics, and grammar. These models improve tasks such as machine translation, sentiment analysis, and question answering through advanced neural network architectures.
How has NLP evolved from the 2000s to the present?
NLP has evolved from rule-based models in the 2000s to data-driven approaches like machine learning and deep learning. The advent of transformers, particularly models like BERT and GPT, has revolutionized tasks like translation, sentiment analysis, and text generation.
What is text extraction in NLP?
Text extraction in NLP refers to the process of identifying and extracting relevant information, such as entities, dates, or keywords, from unstructured text. It enables machines to convert raw data into structured, actionable insights for further analysis or decision-making.
How does morphological segmentation work?
Morphological segmentation breaks down words into smaller units like stems, prefixes, and suffixes. It helps in understanding word structure, enabling better natural language processing (NLP) by identifying meaningful components to enhance tasks like tokenization and word sense disambiguation.
Python Library For Text Processing
- In Python, Natural Language Toolkit (NLTK) is a known open-source package, which allows us to run all common Natural language processing tasks.
- It comes with easy-to-use interfaces and a suite of text processing libraries like tokenization, tagging, classification, and semantic reasoning.

Text Preprocessing
It is required to preprocess the data before making models and analysis. In simple words preprocessing convert raw text data into a logical format for the computer.
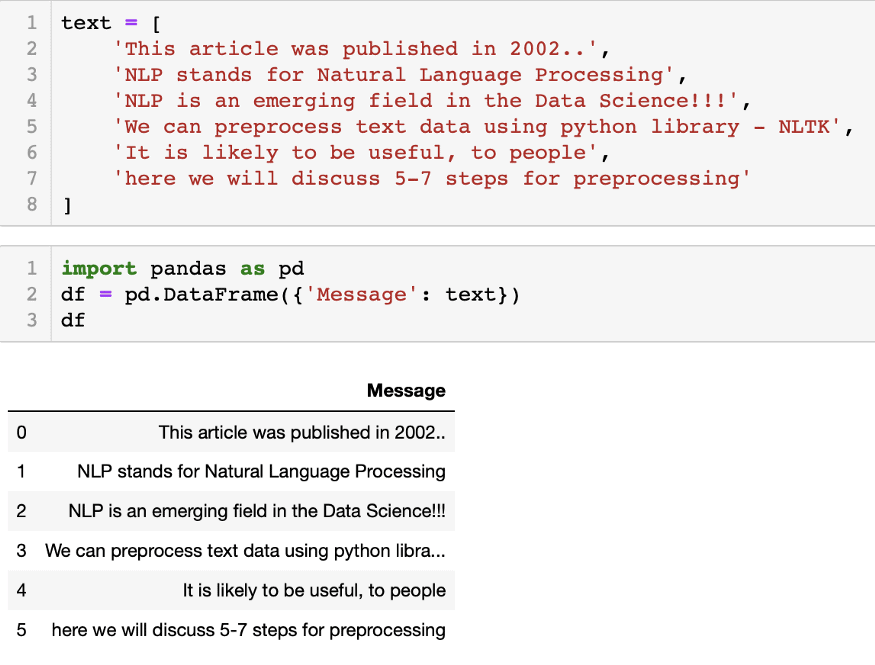
1) Let’s first create a data frame (df) to do some hands-on preprocessing of text data.
2) Then make text in lowercase, to make all the data in a uniform format.

3) Punctuation doesn’t add any additional information. This step shortens the size of the data and therefore increases computational efficiency.

4) Changing numbers into words or removing numbers. Eliminate numbers if they are not significant or change to words.

5) Stop words are very natural words in the sentence that carry no meaning or less meaning compared to other keywords. If we eliminate the words that are less commonly used, we can focus on meaningful keywords instead.

6) Tokenizing text an essential step in text preprocessing where the text is split into basic meaningful units.

7) At the end of Text preprocessing, we apply lemmatization which extracting a root word by considering the vocabulary.
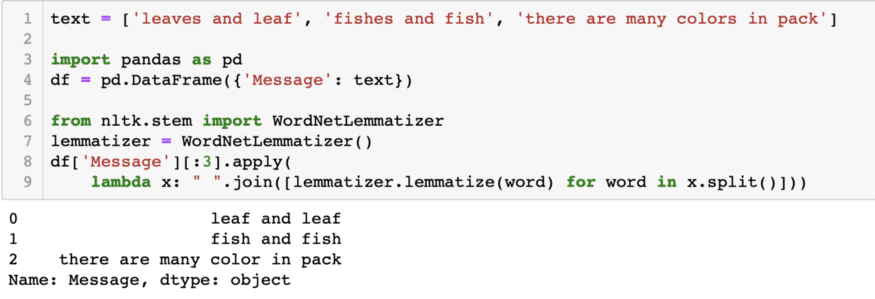
8) Text Preprocessing is completed, now you can use this data for more complex NLP tasks.
What are some potential future developments in NLP?
Future developments in NLP may include improved language models with better contextual understanding, zero-shot learning, enhanced multi-lingual capabilities, real-time dialogue systems, ethical AI for content generation, and more personalized AI assistants for specific industries and tasks.
What challenges does NLP face?
NLP faces challenges like language ambiguity, context understanding, handling diverse dialects, and variations in sentence structure. Additionally, NLP models often struggle with sarcasm, irony, and cultural nuances, making accurate interpretation and response generation difficult in real-world applications.
Deep Learning in Natural Language Processing
Deep learning has revolutionized Natural Language Processing (NLP) by enabling machines to understand and generate human language more accurately. Techniques like Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Transformer models are widely used to process sequential data, making tasks such as language translation, sentiment analysis, and text generation possible. Deep learning models excel in extracting meaningful patterns from large datasets, eliminating the need for manual feature engineering. With advancements in architecture, like GPT and BERT, deep learning continues to push the boundaries of NLP applications.
Natural Language Processing with tensorflow
Natural Language Processing (NLP) with TensorFlow enables the development of powerful models for text classification, sentiment analysis, machine translation, and more. TensorFlow offers pre-built layers and models like the TextVectorization layer, which simplifies preprocessing, and Embedding layers to represent words in continuous vector spaces. By leveraging TensorFlow’s flexibility, you can design custom NLP pipelines and train them efficiently on large datasets. With tools like Keras and TensorFlow Hub, it’s easier to fine-tune pre-trained models and apply NLP techniques for a variety of business use cases, such as chatbots and content analysis.
Text Processing in Python
Text processing in Python involves various techniques for handling and analyzing text data, commonly used in Natural Language Processing (NLP). Python offers powerful libraries like NLTK, spaCy, and regular expressions for tasks such as tokenization, stemming, lemmatization, and text cleaning. Preprocessing steps like removing stopwords, punctuation, and normalizing case help in preparing text data for further analysis or model training. Python’s flexibility and extensive ecosystem make it ideal for text manipulation, enabling tasks like sentiment analysis, text classification, and information extraction. These techniques are foundational in extracting valuable insights from textual data.
Related References
- Visit our YouTube channel “K21Academy”
- Join Our Generative AI Whatsapp Community
- Introduction to Recurrent Neural Networks (RNN)
- Introduction To Data Science and Machine Learning
- Deep Learning Vs Machine Learning
- Introduction to Artificial Neural Network in Python
Next Task: Enhance Your Azure AI/ML Skills






![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



