



![]()
In this post, we will cover what are the main Key Features of Hadoop, Why Hadoop Gain the Popularity & What Hadoop is all about & How we Define it.
If you are just starting out in BigData & Hadoop then we highly recommend you to go through these posts below, first:
- Big Data Hadoop Keypoints & Things you must know to Start learning Big Data & Hadoop, check here
- Big Data & Hadoop Overview, Concepts, Architecture, including Hadoop Distributed File System (HDFS), Check here
Let us see what are the main Key Features of Hadoop
Key Features
- License Free: Anyone can go to the Apache Hadoop Website, From there you Download Hadoop, Install and work with it.
- Open Source: Its Source code is available, you can modify, change as per your requirements.
- Meant for Big Data Analytics: It can handle Volume, Variety, Velocity & Value. hadoop is a concept of handling Big Data, & it handles it with the help of the Ecosystem Approach.
- Ecosystem Approach: (Acquire, Arrange, Process, Analyze, Visualize ) Hadoop is not just for storage & Processing, Hadoop is an ecosystem, that is the main feature of Hadoop. It can acquire the data from RDBMS, then arrange it on the Cluster with the help of HDFS, after then it cleans the data & make it eligible for analyzing by using processing techniques with the help of MPP(Massive Parallel Processing) which shared nothing architecture, then in last it Analyze the data & then it Visualize the data. This is what Hadoop does, So basically Hadoop is an Ecosystem.
- Shared Nothing Architecture: Hadoop is a shared nothing architecture, that means Hadoop is a cluster with independent machines. (Cluster with Nodes), that every node perform its job by using its own resources.
- Distributed File System: Data is Distributed on Multiple Machines as a cluster & Data can stripe & mirror automatically without the use of any third party tools. It has a built-in capability to stripe & mirror data. Hence, it can handle the volume. In this, there are a bunch of machines connected together & data is distributed among the bunch of machines on the back panel & data is striping & mirroring among them.
- Commodity Hardware: Hadoop can run on commodity hardware that means Hadoop does not require a very high-end server with large memory and processing power. Hadoop runs on JBOD (just bunch of disk), so every node is independent in Hadoop.
- Horizontal Scalability: We do not need to build large clusters, we just keep on adding nodes. As the data keeps on growing, we keep adding nodes.
- Distributors: With the help of distributors, we get the bundles, also built-in packages, we do not need to install each package individually. we just get the bundle & we will install what we need for.
- Cloudera: It is a US Based Company, started by the employees of Facebook, LinkedIn & Yahoo. It provides the solution for Hadoop & enterprise solution. The products of Cloudera is known as CDH(Cloudera Distribution for Hadoop), it is a strong package which we can download from Cloudera, we can install & work with it. Cloudera has designed a graphical tool called Cloudera Manager, which helps to do the administration easily in a graphical way
- Hortonworks: Its Product are called as HDP (Hortonworks Data Platform), it is not enterprise, it is Open Source & License free. It has a tool called Apache Ambari, which built the Hortonworks Clusters.
So, above all are the Key Features of Hadoop which makes it strong & its the monopoly opensource Framework for implementing Big Data Analytics
 Hadoop Ecosystem
Hadoop Ecosystem
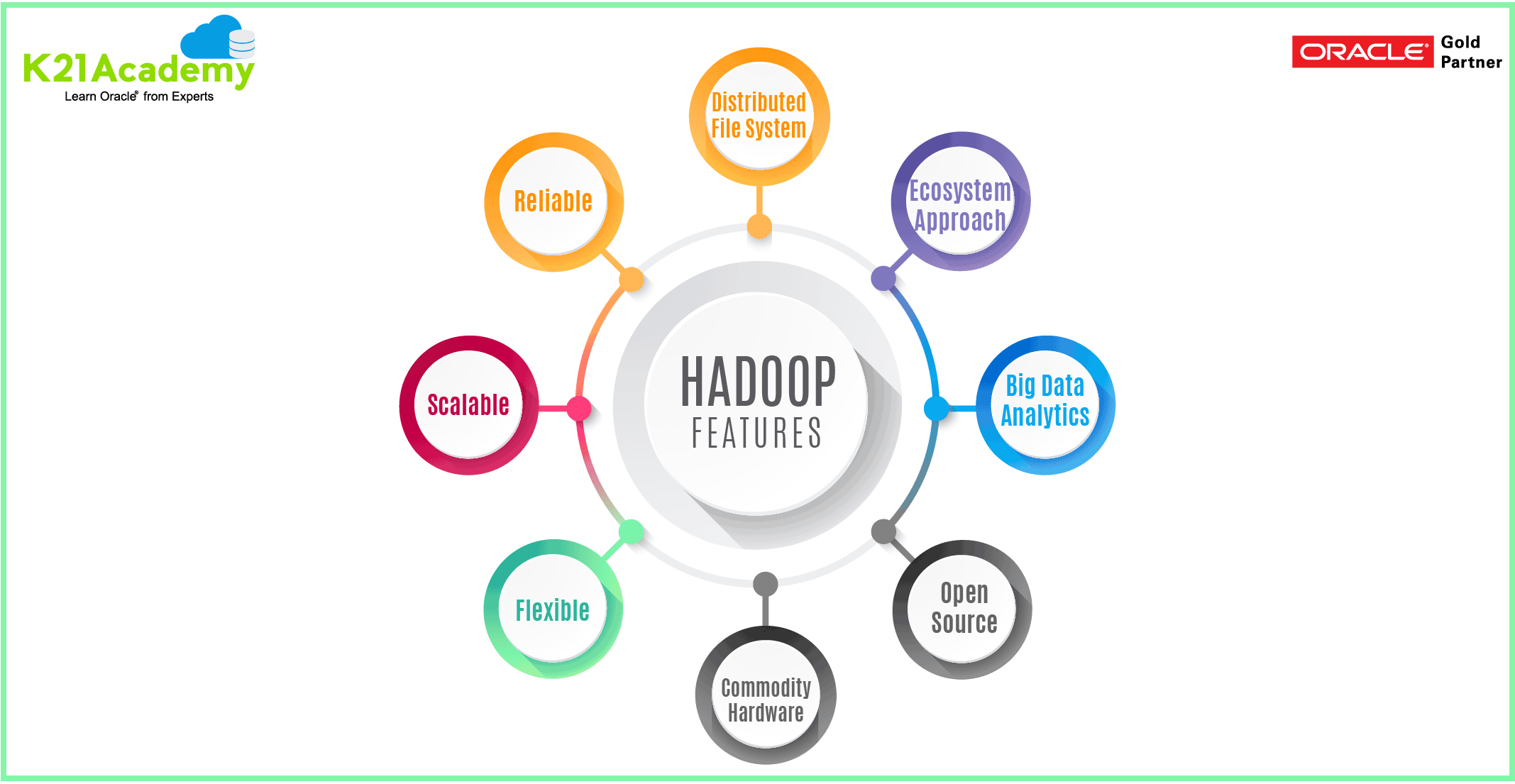 Hadoop Ecosystem
Hadoop EcosystemIt is something which can be useful for implementing your production environment. By its, Ecosystem Hadoop has gained the popularity. It has four phases.
- Where is the Data?
- How much is the data?
- How do the data grow?
- What to do with the data?
These are some basic questions which are generally asked when someone implement Hadoop ecosystem. We can implement when we get the answers. So, the important steps are
- ACQUIRE: SQOOP, Flume, Kafka are the acquired tools. Sqoop is meant for relational database sources to get the data, Flume & Kafka can be used for semi-unstructured data ingestion. once we get the data then we arrange the data.
- ARRANGE: Data is arranged on HDFS, after that, we have to process it
- PROCESS: There are some tools by which we process i.e YARN (MapReduce, SOLR, Spark, Apache Giraph…)
- ANALYZE: PIG, HIVE & IMPALA helps to analyze the data.
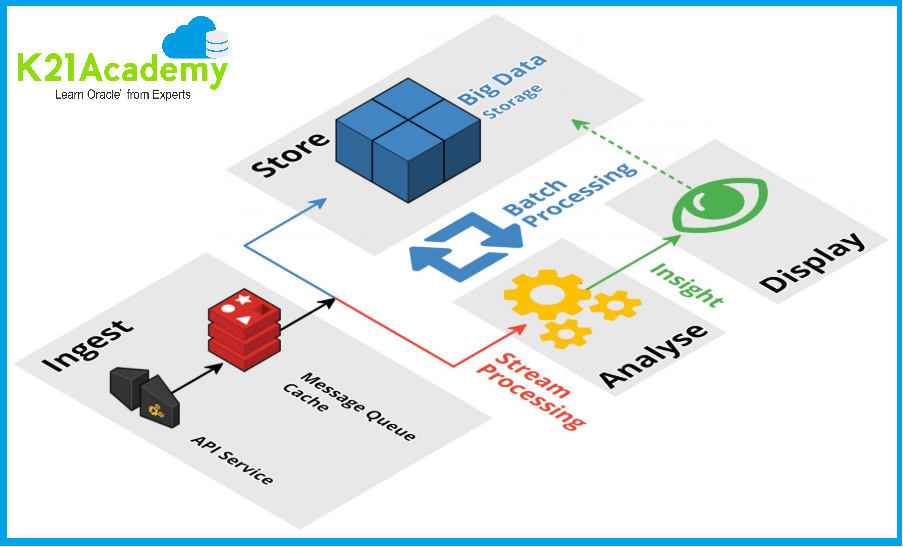
Major Advantages of Hadoop
1. Scalable
Hadoop is a highly scalable storage platform because it can store and distribute very large data sets across hundreds of inexpensive servers that operate in parallel. Unlike traditional relational database systems (RDBMS) that can’t scale to process large amounts of data.
2. Cost-effective
Hadoop also offers a cost-effective storage solution for businesses exploding data sets. The problem with traditional relational database management systems is that it is extremely cost prohibitive to scale to such a degree in order to process such massive volumes of data. In an effort to reduce costs, many companies in the past would have had to down-sample data and classify it based on certain assumptions as to which data was the most valuable. The raw data would be deleted, as it would be too cost-prohibitive to keep.
3. Flexible
Hadoop enables businesses to easily access new data sources and tap into different types of data (both structured and unstructured) to generate value from that data. This means businesses can use Hadoop to derive valuable business insights from data sources such as social media, email conversations.
4. Fast
Hadoop’s unique storage method is based on a distributed file system that basically ‘maps’ data wherever it is located on a cluster. The tools for data processing are often on the same servers where the data is located, resulting in much faster data processing. If you’re dealing with large volumes of unstructured data, Hadoop is able to efficiently process terabytes of data in just minutes, and petabytes in hours.
5. Resilient to failure
A key advantage of using Hadoop is its fault tolerance. When data is sent to an individual node, that data is also replicated to other nodes in the cluster, which means that in the event of failure, there is another copy available for use.
You will get to know all of this and deep-dive into each concept related to BigData & Hadoop, once you will get enrolled in our Big Data Hadoop Administration Training
Related Further Readings
- Roadmap for Learning Hadoop
- Apache Spark Vs Hadoop MapReduce
- BigData Hadoop: Introduction to Apache Spark
- What is Big Data from Oracle
- Big Data Hadoop Administration Live Training
- Step by Step Hands-on Guide for Hadoop Administration
Be Prepared For Your Interview!
Looking for commonly asked interview questions for Big Data Hadoop Administration?
Click below Image and get that in your inbox or join our Private Facebook Group dedicated to Big Data Hadoop Members Only.







![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



