![]()
Databricks is a powerful platform that combines the capabilities of data warehousing and machine learning, making it a sought-after tool among data professionals.
In this blog we are going to cover:
- Introduction to Databricks
- When to Use Azure Databricks
- Dive into Delta Lake
- Apache Spark Architecture Fundamentals
- Preparing Data for Machine Learning
- Deploying Azure Databricks Models in Azure Machine Learning
- Reading and Writing Data in Databricks
- Structured Streaming with Databricks
- Databricks vs. Snowflake
- Conclusion
- Top 30 Databricks Interview Questions and Answers
For beginners, however, navigating through its complex features can be a challenge. This blog aims to simplify Databricks for novices, offering a step-by-step approach to harnessing its full potential.
Introduction to Databricks
Begin your journey with a fundamental understanding of Databricks(DB), exploring its core concepts and applications. Learn more about Azure Databricks.
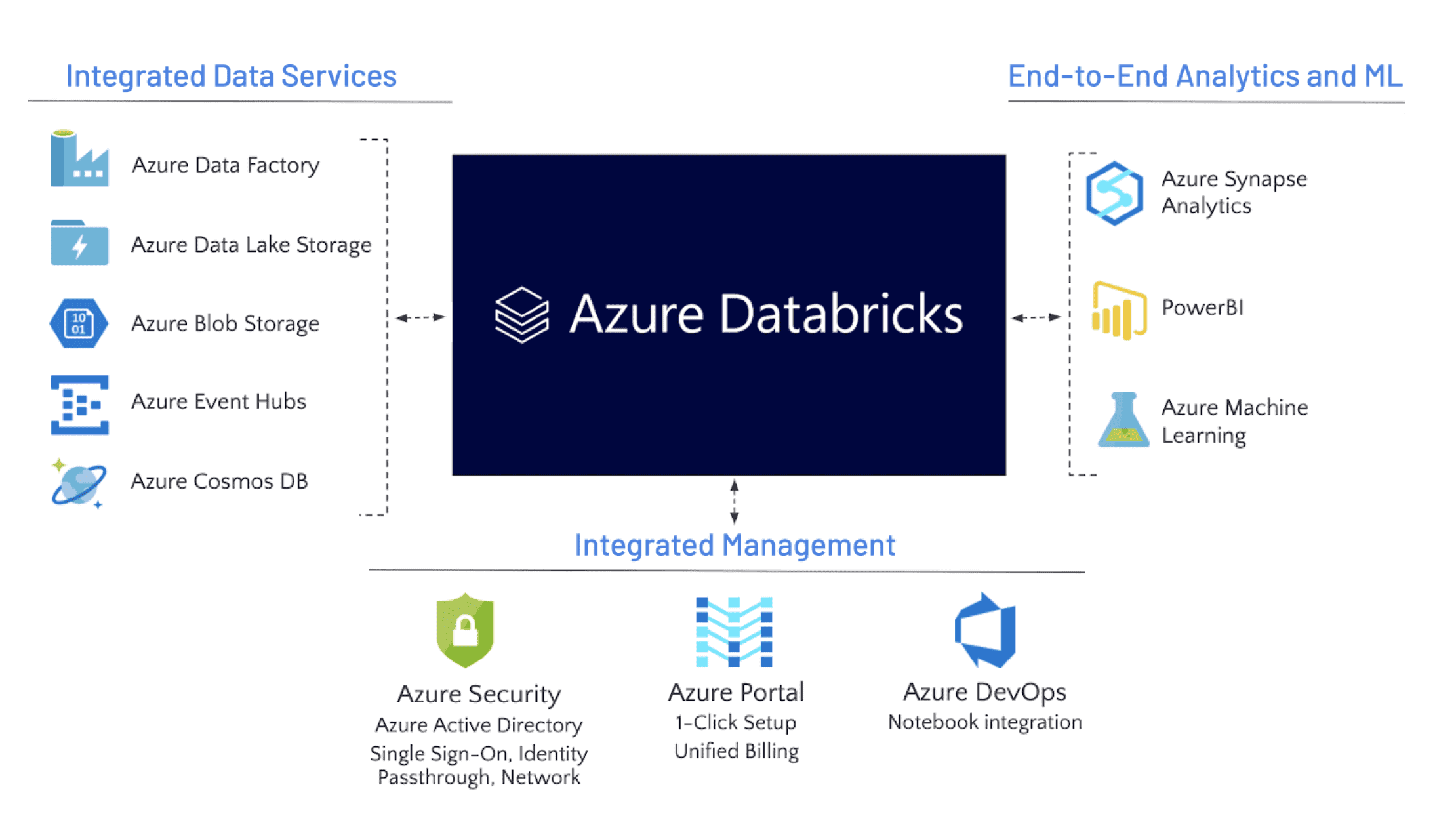
When to Use Azure Databricks
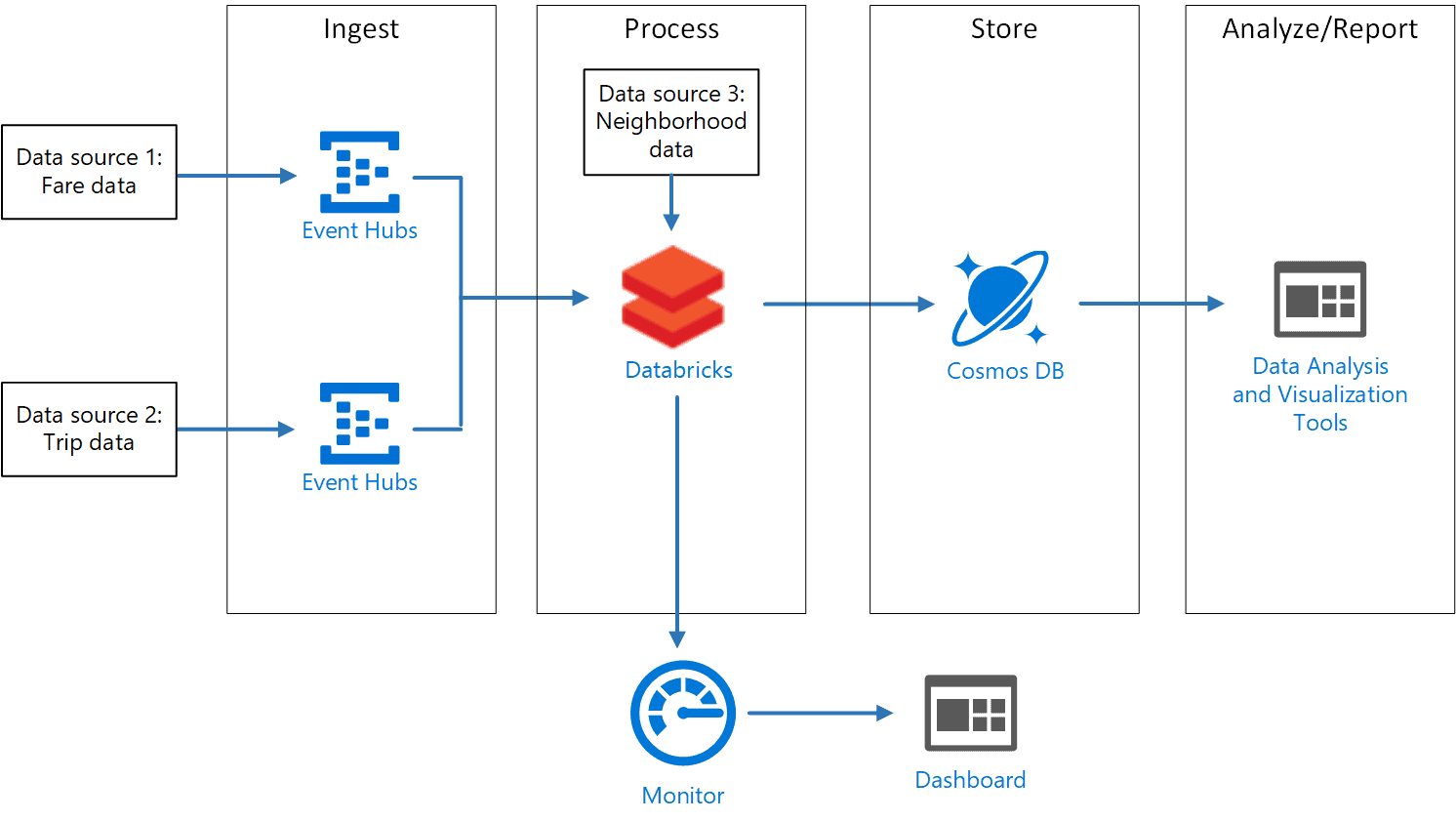
Discover scenarios and use cases that determine the appropriate application of Azure Databricks. Get insights here.
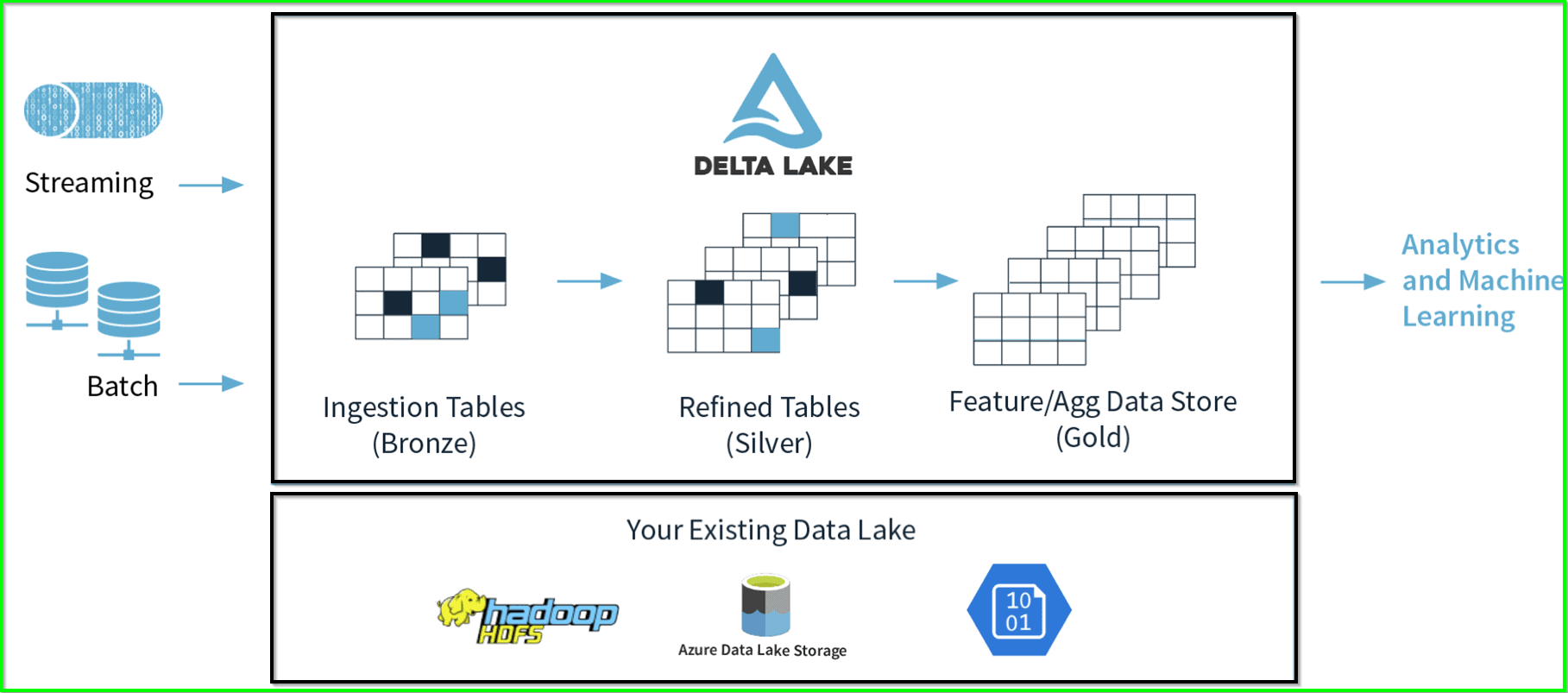
Dive into Delta Lake
Enhance your understanding of Delta Lake, a unified data storage system, and its integration with Databricks. Explore the guide on Delta Lake.
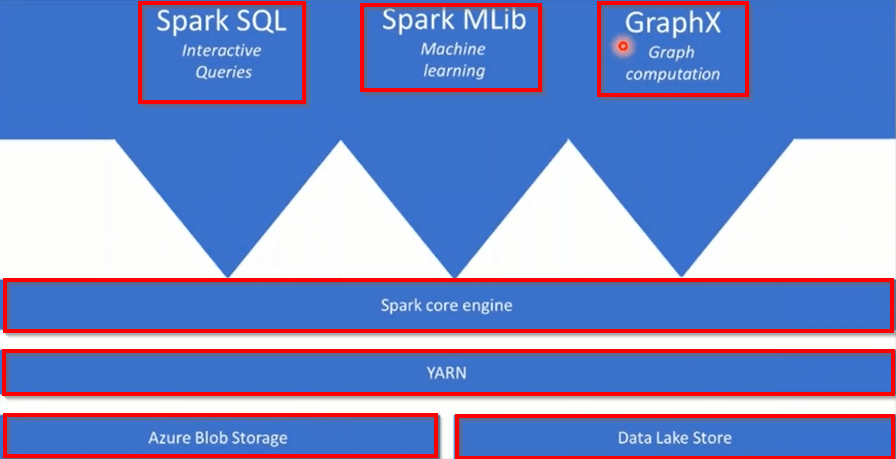
Apache Spark Architecture Fundamentals
Unlock the complexities of Apache Spark and its integral role within Databricks. Learn about Apache Spark architecture fundamentals.
Preparing Data for Machine Learning
Harness the power of Databricks in preparing and processing data for machine learning. Enhance your skills in how to prepare data for machine learning with Azure Databricks.

Deploying Azure Databricks Models in Azure Machine Learning
Step into advanced operations as you learn to deploy DB models within Azure Machine Learning. Deploy Azure Data bricks model in Azure Machine Learning.
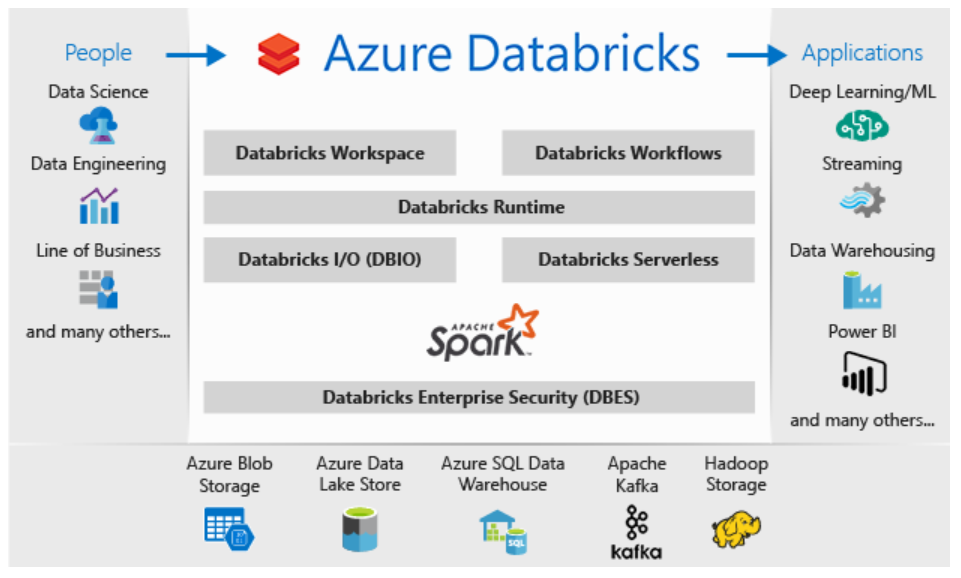
Reading and Writing Data in Databricks
Master the art of data ingestion and extraction efficiently using Databricks. Here’s an insightful guide on reading and writing data in Databricks.
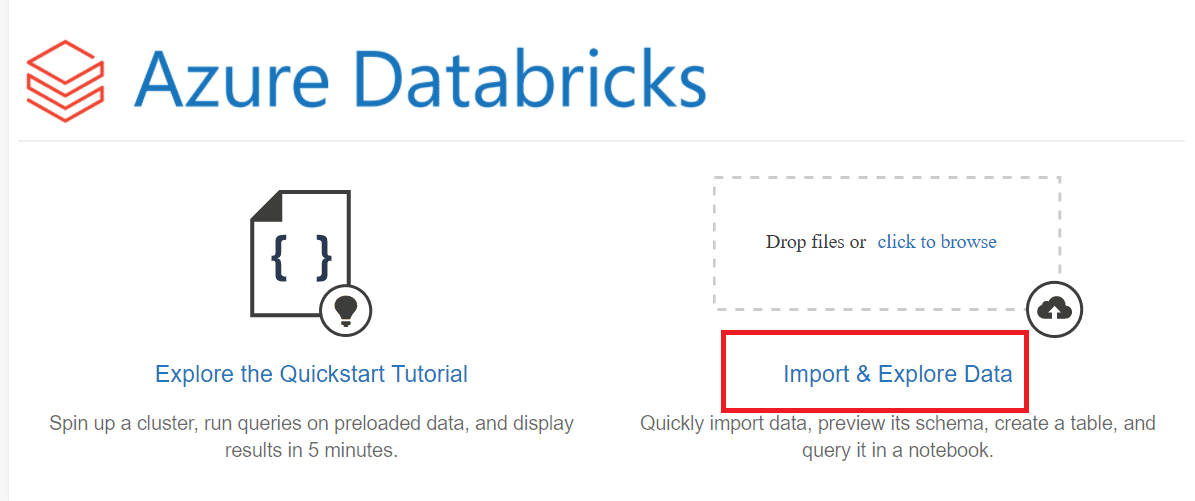
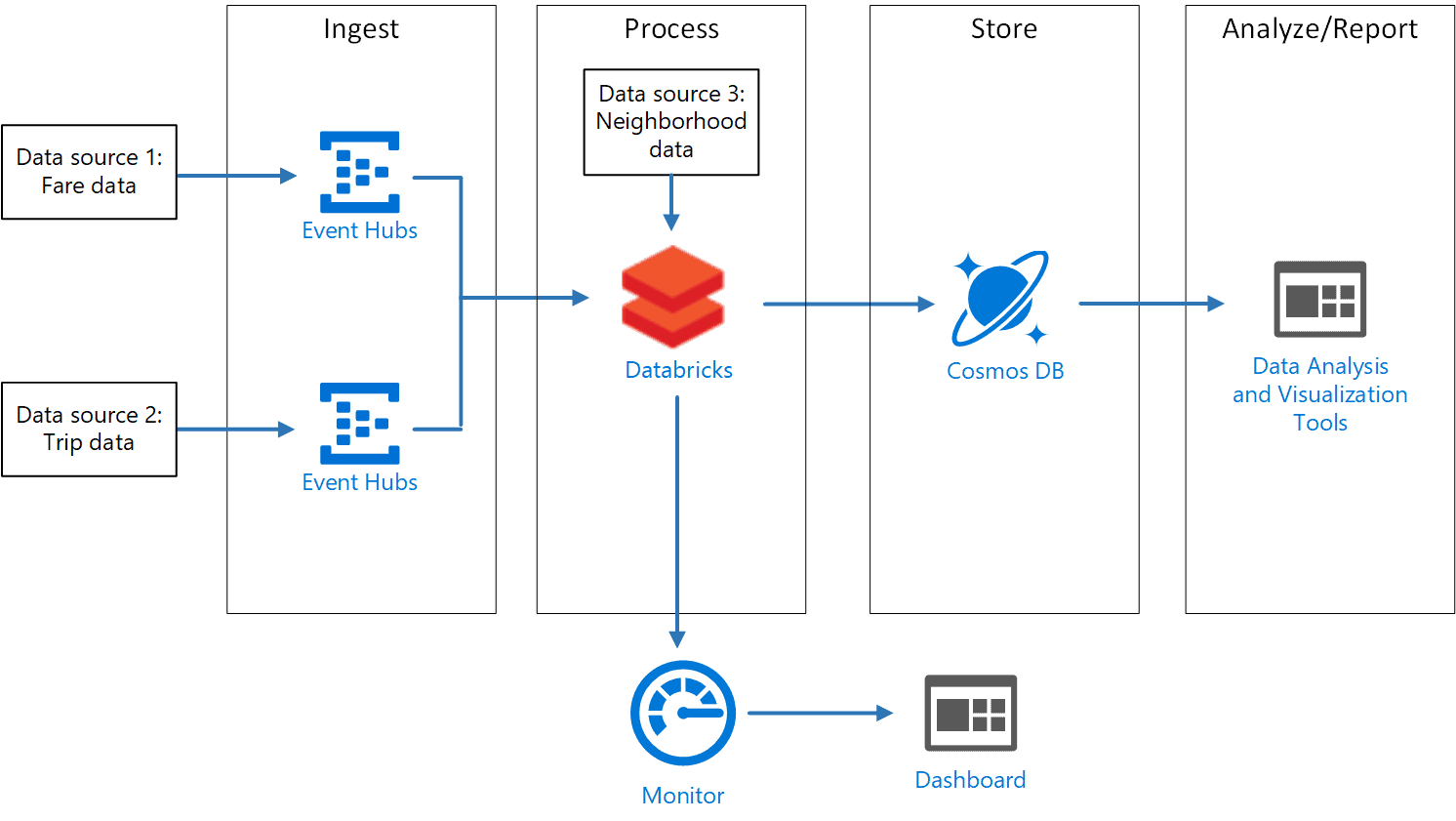
Structured Streaming with Databricks
Dive into the world of real-time data processing with DB’ structured streaming functionalities. Here’s a comprehensive guide on structured streaming with Azure Databricks.
Databricks vs. Snowflake
Unravel the comparative analysis between Databricks and Snowflake, helping you to choose the right platform. Explore the detailed comparison here.

Each section provides a detailed exploration of topics, enriched with practical examples, making your learning journey and interview preparation comprehensive and robust.
Conclusion
With a combination of structured learning from the links above and practical implementations, mastering Databricks becomes an achievable task. Prepare yourself not just to answer interview questions confidently but to harness the full potential of Databricks in real-world applications.
Top 30 Databricks Interview Questions and Answers
Here are some most frequent interview questions that you may be asked:
1. What are the benefits of using Databricks?
The benefits of using it include its ease of use, its scalability, and its wide range of features.
2. What are the different components of Databricks?
The different components of it include the DB Workspace, the DB notebooks, and the Databricks clusters.
3. What is a Databricks notebook?
A DB notebook is a web-based document that allows you to write and run Spark code.
4. What are Databricks clusters?
DB clusters are groups of virtual machines that are used to run Spark applications
5. What is the difference between Spark SQL and Spark DataFrames?
Spark SQL is a component of Spark that allows you to use SQL to query and manipulate Spark DataFrames.
6. What is RDD?
RDD stands for Resilient Distributed Dataset. It is a data structure in Spark that represents a collection of data that is distributed across multiple machines.
7. What is DataFrames API?
DataFrames API is a programming interface in Spark that allows you to manipulate Spark DataFrames.
8. What is Spark Streaming?
Spark Streaming is a component of Spark that allows you to process real-time data streams.
9. What is Spark MLlib?
Spark MLlib is a machine learning library that is built on top of Spark.
10. What is Delta Lake?
Delta Lake is a unified data storage layer that is built on top of Apache Spark. It provides a variety of features that make it easier to manage and analyze data, such as ACID transactions, schema enforcement, and time travel.
11. What are the benefits of using Delta Lake?
The benefits of using Delta Lake include its ease of use, its scalability, and its wide range of features.
12. What is Databricks SQL?
DB SQL is a managed SQL service that is built on top of Delta Lake. It allows you to run SQL queries against your data without having to manage any infrastructure.
13. What are the benefits of using Databricks SQL?
The benefits of using DB SQL include its ease of use, its scalability, and its high performance.
14. What is Databricks Workspace?
DB Workspace is a unified workspace for data science and engineering. It provides a variety of features that make it easier to develop, deploy, and manage big data applications.
15. What kind of Databricks projects have you worked on?
I have worked on a variety of DB projects, including building a data pipeline to process real-time data streams, developing a machine learning model to predict customer churn, and creating a data dashboard to visualize key business metrics.
16. What Databricks features do you use most often?
The DB features that I use most often are Spark SQL, DataFrames API, and Delta Lake.
17. What are your favorite Databricks features?
My favorite features are Delta Lake and DB SQL. I like Delta Lake because it makes it easier to manage and analyze data, and I like DB SQL because it is a managed SQL service that is easy to use and scalable.
18. What are some of the challenges you have faced when using Databricks?
One of the challenges I have faced when using DB is optimizing the performance of my Spark applications. I have overcome this challenge by learning about the different Spark performance tuning techniques.
19. How have you overcome these challenges?
Another challenge I have faced when using DB is managing the cost of my DB clusters. I have overcome this challenge by learning about the different DB pricing options and by using DB Autoscaling to automatically scale my clusters up and down based on my needs.
20. What are the different ways to create a Databricks cluster?
There are three different ways to create a DB cluster:
- Create a cluster from the UI: This is the simplest way to create a cluster. To do this, go to the Clusters page in the DB UI and click the Create Cluster button.
- Create a cluster using the CLI: The DB CLI is a command-line tool that you can use to manage your DB clusters. To create a cluster using the DB CLI, run the following command:
databricks clusters create
- Create a cluster using the DB REST API: The DB REST API is an HTTP API that you can use to manage your DB clusters. To create a cluster using the DB REST API, make a POST request to the
/clusters/createendpoint.
21. How can you optimize the performance of your Databricks clusters?
There are a few things you can do to optimize the performance of your DB clusters:
- Choose the right cluster type and size for your job. DB offers a variety of cluster types and sizes, so it is important to choose the one that is best suited for your needs.
- Use the right Spark configuration. Spark has a number of configuration parameters that can affect performance. You can tune these parameters to improve the performance of your Spark applications.
- Optimize your data layout. The way you store your data in DB can have a significant impact on performance. You can optimize your data layout to improve the performance of your Spark applications.
22. What are the different ways to share data between Databricks clusters?
There are a few different ways to share data between DB clusters:
- Use the Databricks File System (DBFS): DBFS is a distributed file system that is built on top of Apache Spark. You can share data between DB clusters by storing it in DBFS.
- Use a cloud storage service: You can also share data between DB clusters by storing it in a cloud storage service, such as Amazon S3 or Google Cloud Storage.
- Use a DB Hive Metastore: A DB Hive Metastore is a shared metadata repository that you can use to manage your data. You can share data between DB clusters by storing it in a DB Hive Metastore.
23. How can you use Databricks to process real-time data streams?
DB provides a number of features that you can use to process real-time data streams, including:
- Spark Streaming: Spark Streaming is a component of Spark that allows you to process real-time data streams.
- Delta Live Tables: Delta Live Tables is a feature of DB that allows you to build and manage streaming data pipelines.
- DB SQL: DB SQL is a managed SQL service that you can use to run SQL queries against your data streams.
24. How can you use Databricks to build machine learning models?
DB provides a number of features that you can use to build machine learning models, including:
- Spark MLlib: Spark MLlib is a machine learning library that is built on top of Spark.
- DB MLflow: DB MLflow is a platform for managing the machine learning lifecycle.
- DB AutoML: DB AutoML is a tool that automates the machine learning process.
25. How can you use Databricks to create data dashboards and visualizations?
Databricks provides a number of features that you can use to create data dashboards and visualizations, including:
- DB SQL: DB SQL allows you to create data dashboards and visualizations using SQL.
- DB SQL Dashboards: DB SQL Dashboards is a tool that allows you to create interactive data dashboards.
- DB Visualizations: DB Visualizations is a library of pre-built data visualizations that you can use in your DB notebooks and dashboards.
26. What are some of the security features that Databricks offers?
Databricks offers a number of security features, including:
- Role-based access control (RBAC): RBAC allows you to control who has access to your DB resources.
- Network isolation: DB clusters are isolated from the public internet and from each other.
- Data encryption: DB encrypts all data at rest and in transit.
- Audit logging: DB logs all activity in your Databricks Workspace.
27. What are some of the best practices for using Databricks?
Here are some of the best practices for using Databricks(DB):
- Choose the right cluster type and size for your job.
- Use the right Spark configuration.
- Optimize your data layout.
- Use the Databricks File System (DBFS) to share data between DB clusters.
- Use a cloud storage service to store large datasets.
- Use a DB Hive Metastore to manage your data.
- Use Spark Streaming or Delta Live Tables to process real-time data streams.
- Use Spark MLlib, DB MLflow, or DB AutoML to build machine learning models.
- Use DB SQL, DB SQL Dashboards, or DB Visualizations to create data dashboards and visualizations.
- Use role-based access control (RBAC) to control who has access to your DB resources.
- Use network isolation to isolate your DB clusters from the public internet and from each other.
- Use data encryption to encrypt all data at rest and in transit.
- Use audit logging to log all activity in your DB Workspace.
28. Can you tell me about a time when you used Databricks to solve a challenging problem?
Sure. One time I used it to solve a challenging problem was when I was working on a project to develop a machine-learning model to predict customer churn. The dataset I was working with was very large and complex, and it was difficult to train a model that was accurate and performant.
I used DB to solve this problem by following these steps:
- I used Spark Streaming to process the real-time data stream of customer activity.
- I used Spark MLlib to train a machine learning model to predict customer churn.
- I used DB MLflow to deploy the model to production.
- I used DB SQL to create a data dashboard to monitor the performance of the model.
As a result of this project, I was able to develop a machine learning model that accurately predicted customer churn and helped the company to reduce customer churn by 10%.
29. What are some of the things you like and dislike about Databricks?
Here are some of the things I like and dislike about Databricks:
Likes:
- It is a unified platform that provides a wide range of features for data science and engineering.
- It is easy to use and scalable.
- It offers a variety of pricing options, so you can choose the one that best fits your needs.
Dislikes:
- It can be expensive, especially for large datasets and complex workloads.
- It can be difficult to troubleshoot, especially when you are new to the platform.
30. What are some of the new Databricks features that you are most excited about?
I am most excited about the following new DB features:
- DB SQL Analytics: DB SQL Analytics is a new feature that provides a faster and more scalable way to run SQL queries against your data.
- DB Machine Learning: DB Machine Learning is a new feature that provides a unified platform for managing the machine learning lifecycle.
- DB Geospatial: DB Geospatial is a new feature that provides a unified platform for working with geospatial data.
Related/References
- Exam DP-203: Data Engineering on Microsoft Azure
- Azure Databricks, Apache Spark & Azure Databricks Architecture Overview
- Azure Databricks and Azure Synapse Analytics: Use Cases
- Prepare Data for Machine Learning with Azure Databricks
- Deploy Azure Databricks Model in Azure Machine Learning
- Reading and Writing Data In DataBricks
- Databricks vs Snowflake – Data Engineer
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.


Leave a Reply