



![]()
In today’s digital era, businesses are more reliant than ever on cloud technologies for their day-to-day operations. The cloud offers scalability, flexibility, and cost-efficiency, but it also introduces new challenges and vulnerabilities, including cyber-attacks, data breaches, natural disasters, and human errors. This is where Disaster Recovery (DR) comes into play, serving as a critical component of a comprehensive cloud strategy. In order to better comprehend its effects, we will examine the potential of AWS in helping organizations to accomplish flawless disaster recovery.
- Introduction to Disaster Recovery
- AWS Services for Disaster Recovery
- Steps to Set Up AWS Disaster Recovery
- Architecting a Disaster Recovery Strategy in AWS
- Cost Optimization in AWS Disaster Recovery
- AWS Disaster Recovery Advantages
- Case Studies: Real-world Examples
- FAQs
Introduction to Disaster Recovery
The emergence of cloud computing has revolutionized the field of disaster recovery, offering scalable, cost-effective, and highly resilient solutions. Disaster recovery involves the process of restoring and recovering an organization’s critical systems, infrastructure, and data after a disruptive event. It aims to minimize downtime, recover lost data, and resume normal operations as quickly as possible.
AWS (Amazon Web Services) offers a full range of tools and services to assist organizations in establishing effective disaster recovery strategies. Services like Amazon S3 for secure and reliable object storage, Amazon EC2 for adaptable and scalable computing instances, and AWS Backup for automatic backup and recovery procedures are all provided by AWS. AWS also offers options like cross-region replication which lets companies duplicate data. Also, organizations can improve their capacity to respond to disasters by using AWS for DR.
AWS Services for Disaster Recovery
AWS provides a number of services that act as the cornerstones of a strong disaster recovery plan:
1.) Amazon S3 (Simple Storage Service): Amazon S3 offers scalable and extremely durable object storage. It is perfect for safely storing backup data and making it possible for quick retrieval during the recovery stage.
2.) Amazon EC2 (Elastic Compute Cloud): Virtual servers can be provisioned in the cloud using Amazon EC2 (Elastic Compute Cloud). Organizations can build a failover architecture by replicating their on-premises virtual machine (VM) environments. High availability and seamless failover are made possible by EC2’s Auto Scaling and Load Balancing features.
3.) AWS Database Services: Database services from AWS include Amazon RDS (Relational Database Service), Amazon DynamoDB, and Amazon Aurora. The automated backups, point-in-time recovery, and cross-region replication provided by these services ensure data durability and availability.
4.) AWS Storage Gateway: AWS Storage Gateway acts as a bridge between on-premises environments and AWS storage services. It allows for seamless integration of existing infrastructure with AWS, enabling hybrid cloud architectures for disaster recovery purposes. The Storage Gateway offers features like volume snapshots, replication, and caching to optimize data transfer and recovery.
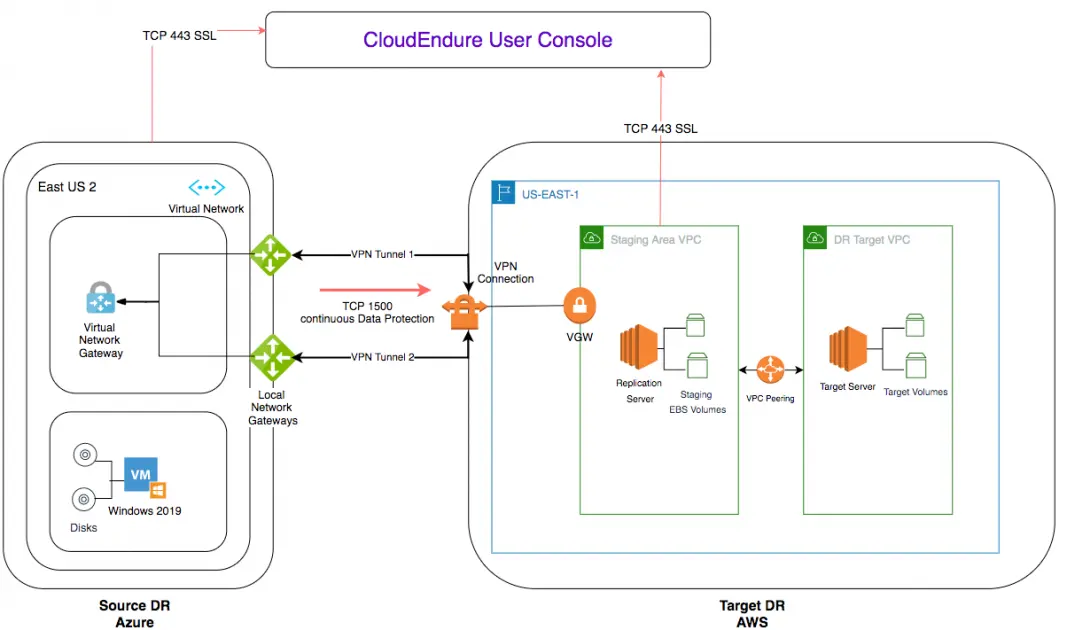
Steps to Set Up AWS Disaster Recovery
- Define Recovery Objectives: Determine RTO and RPO for critical applications and data based on the BIA results.
- Identify DR Architecture: Choose an appropriate architecture based on your recovery objectives, such as active-passive, active-active, or pilot light.
- Replicate Data and Applications: Use AWS services like AWS Database Migration Service, AWS Storage Gateway, or AWS Direct Connect for data replication and synchronization between regions.
- Set Up Automation: Utilize AWS services like AWS CloudFormation, AWS Elastic Beanstalk, or AWS Lambda to automate DR processes, including backup, replication, failover, and recovery.
- Establish Monitoring and Alerting: Configure AWS CloudWatch and AWS CloudTrail to monitor system health, capture logs, and events, and set up alerts for any anomalies.
- Test and Validate: Regularly perform scheduled and ad-hoc disaster recovery tests to validate the effectiveness of your DR plan. Document the outcomes and address any identified gaps.
- Document the DR Plan: Create a comprehensive DR runbook outlining all the necessary steps, roles, and responsibilities involved in the recovery process.
 Architecting a Disaster Recovery Strategy in AWS
Architecting a Disaster Recovery Strategy in AWS
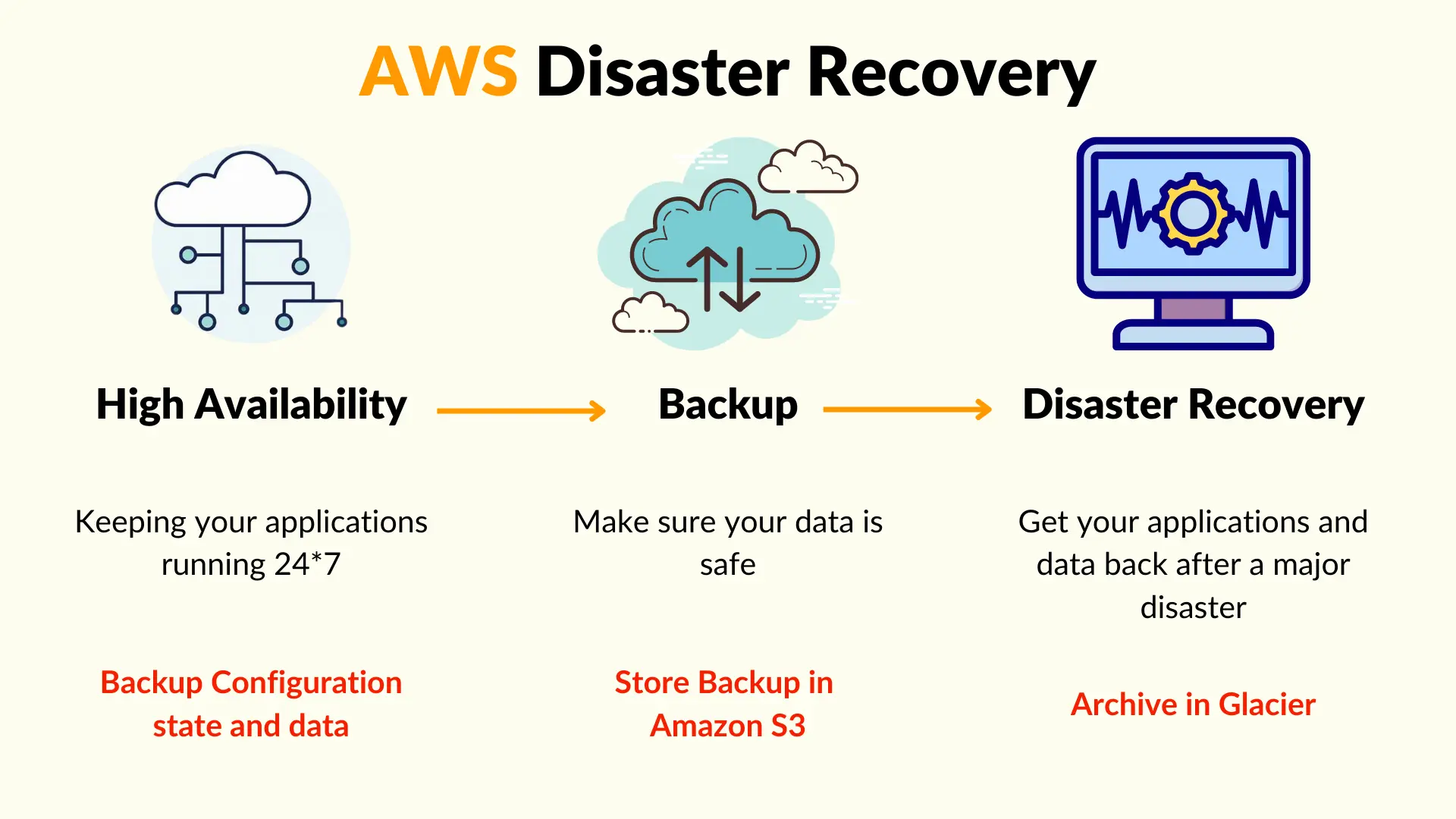 Architecting a Disaster Recovery Strategy in AWS
Architecting a Disaster Recovery Strategy in AWSConsider the following crucial factors while creating a disaster recovery solution on AWS:
a) Assessing Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs): Evaluation of Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs) establishes the maximum allowable downtime and data loss in the event of a disaster. The selection of the right AWS services and configurations will be influenced by these indicators.
b) Designing a Multi-Region or Multi-Availability Zone (AZ) Architecture: Distribute resources across different AWS regions or AZs to provide redundancy and remove single points of failure. This strategy offers resistance against local calamities.
c) Implementing Replication and Failover Mechanisms: Use AWS services like AWS Elastic File System, AWS Database Migration Service, or storage-level replication to replicate data and configurations between regions or AZs. Use failover techniques such as Route 53 DNS failover or Amazon RDS Multi-AZ deployments for automated failover.
d) Leveraging AWS CloudFormation for Infrastructure as Code: Use AWS CloudFormation to define and provision infrastructure resources as code. This allows for consistent and repeatable deployments, simplifying disaster recovery setup and management.
Cost Optimization in AWS Disaster Recovery:
Optimizing costs while ensuring effective disaster recovery can be achieved through the following strategies:
- Understand AWS Pricing Models and Cost Factors: Familiarize yourself with the pricing models and cost components associated with AWS services. This knowledge helps in making informed decisions about resource usage and configuration.
- Utilize Reserved Instances and Spot Instances: Reserved Instances offer significant cost savings for long-term resource usage, while Spot Instances provide cost-effective options for non-critical workloads during periods of low demand.
- Right-Size Resources: Continuously monitor resource utilization and right-size instances, storage volumes, and database instances based on workload requirements. AWS Cost Explorer can assist in identifying optimization opportunities.
- Implement Lifecycle Policies for Data Storage Optimization: Define lifecycle policies for data stored in Amazon S3 or Glacier to automatically transition data to lower-cost storage tiers as it ages, reducing storage costs.
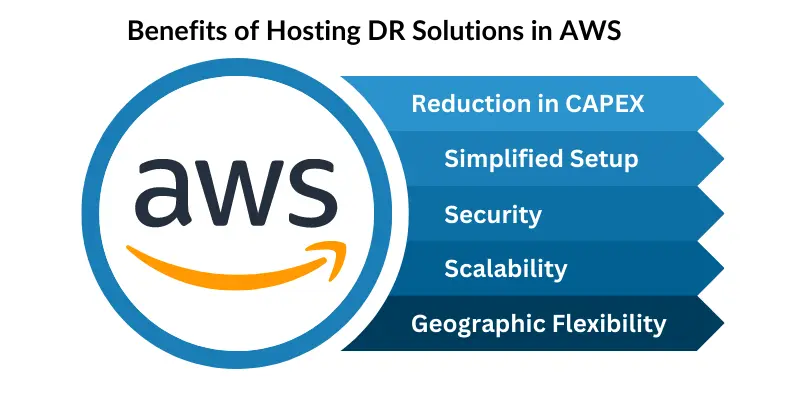
 AWS Disaster Recovery’s advantages
AWS Disaster Recovery’s advantages
 AWS Disaster Recovery’s advantages
AWS Disaster Recovery’s advantagesa) Enhanced Business Continuity: Improved business continuity is made possible by AWS DR solutions, which assist reduce downtime and guarantee continuous operations. This enables organizations to keep up productivity and customer satisfaction even in the face of disaster.
b) Cost Efficiency: Conventional disaster recovery techniques frequently call for large up-front expenditures for infrastructure and upkeep. Pay-as-you-go services from AWS enable companies to cut costs by doing away with the requirement for specialized physical infrastructure.
c) Flexibility and Scalability: AWS enables businesses to scale their DR solutions in response to changing business requirements. Businesses are able to quickly adjust to shifting workloads because to on-demand resources and automatic scaling capabilities.
d) Geographic Redundancy: AWS provides a worldwide infrastructure with numerous regions and Availability Zones, enabling businesses to replicate their data and applications across various locations. This ensures data redundancy and minimizes the impact of localized disasters.
e) Automation and Orchestration: AWS provides a suite of tools and services that enable automated DR processes, including backup scheduling, replication, failover, and recovery. This reduces human error and ensures consistency and reliability in disaster recovery procedures.
 Case Studies: Real-world Examples
Case Studies: Real-world Examples
 Case Studies: Real-world Examples
Case Studies: Real-world ExamplesSeveral organizations have successfully implemented disaster recovery solutions in AWS, including:
- Netflix: Netflix utilizes AWS services to achieve seamless disaster recovery, ensuring continuous streaming services to millions of users worldwide.
- Dow Jones: Dow Jones implemented multi-region deployments in AWS, allowing for resilient and highly available infrastructure to support critical financial data services.
- Airbnb: Airbnb leverages AWS services to ensure high availability for their online marketplace, enabling uninterrupted booking and hosting services.
 FAQs
FAQs
 FAQs
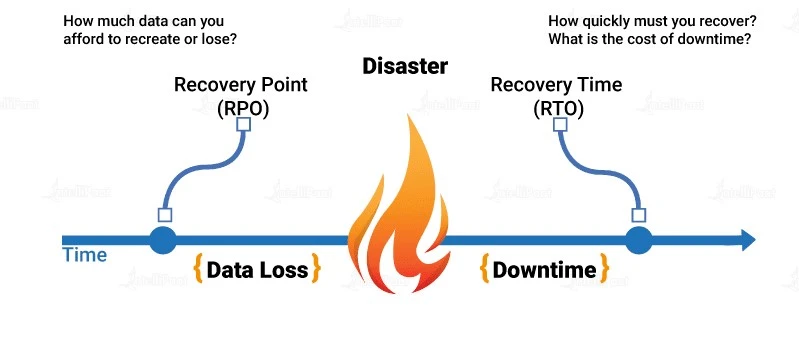
FAQsQ1. What is the difference between RPO and RTO in AWS disaster recovery?
Answer: RPO (Recovery Point Objective) represents the maximum tolerable amount of data loss during a disaster. It indicates the point in time to which data must be restored to ensure minimal loss. RTO (Recovery Time Objective) refers to the maximum acceptable downtime for applications or systems after a disaster. It represents the time it takes to recover and resume normal operations. Determining RPO and RTO helps organizations define their recovery goals and design an appropriate disaster recovery solution.
Q2. What AWS services can be utilized for automated disaster recovery?
Answer: a) AWS CloudFormation: Enables infrastructure provisioning and deployment automation. b) AWS Lambda: Allows organizations to run code in response to events, automating recovery processes. c) AWS Elastic Beanstalk: Facilitates application deployment and management with built-in scaling and failover capabilities. d) AWS Route 53: Provides DNS failover for redirecting traffic to healthy instances or regions. e) AWS CloudWatch: Monitors system health and triggers automated actions based on predefined metrics or thresholds.
Q3. Can AWS disaster recovery be combined with on-premises infrastructure?
Answer: Yes, AWS offers services like AWS Storage Gateway, which enables seamless integration between on-premises systems and AWS cloud storage. This allows organizations to extend their disaster recovery strategies to include both on-premises and cloud environments, creating a hybrid disaster recovery solution.
Q4. How does AWS handle regional failures in disaster recovery?
Answer: AWS is designed with high availability and fault tolerance in mind. In the event of a regional failure, where an entire AWS region becomes unavailable, applications and data can be quickly recovered and redirected to other regions using services like Amazon Route 53 for DNS failover and load balancing.
Related Links/References
- AWS Certified Solutions Architect Associate SAA-CO3
- Overview of Amazon Web Services & Concepts
- Storage – Amazon Elastic Compute Cloud – AWS Documentation
- Amazon Simple Email Service (AWS SES): Feature, Working & Best Practices
- AWS VPC and Subnets – A Comprehensive Guide
- Introduction To Cloud & AWS
Next Task For You
Begin your journey towards an AWS Cloud by joining our FREE Informative Class on Amazon Cloud Free Class by clicking on the below image.







![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



