




![]()
The AWS Certified Machine Learning specialty certification is meant for folk that performs an improvement or data science position. It validates a candidate’s capability to design, implement, deploy, and hold machine learning (ML) answers for given enterprise issues.
We have recently started our AWS Certified Machine Learning – Specialty [MLS-C01] Training Program.
This Post will cover some quick tips including FAQs on the topics that we covered in the Day 3 & 4 live sessions which will help you to clear Certification [MLS-C01] & get a better-paid job.
The previous week, In Day 1 & 2 sessions we got an overview of Python basics and Statistics & Probability. And in this week Day 3 & 4, we covered the concepts of Data Engineering Basic and Data Engineering in AWS. We also performed some Hands-on extensive labs.
> Data Engineering Basics
Data Engineering consists of Designing, building, and scaling systems that organize data for analytics

Most people enter the data science world with the aim of turning into a data scientist, while not ever realizing what a data engineer is, or what that role entails. These data engineers are vital parts of any data science project and their demand in the industry is growing exponentially in the current data-rich environment.
Q1: What is bias or variance trade-off?
A: Bias is how far removed the mean of your predicted values is from the “real” answer. In simple words, how far you are from the correct value or how good are your predictions overall in predicting the mean of prediction & whether they are in the right spot.
Variance is however scattered your predicted values are from the “real” answer
Let’s look at the bias and variance of these four cases below (assuming the center is the correct result)
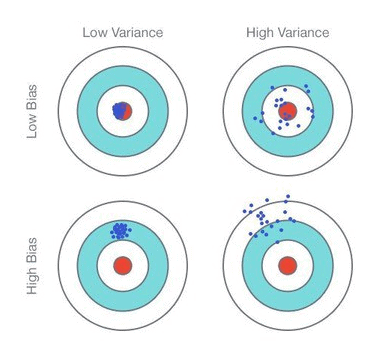
- Bias and variance both contribute to the error
Error = Bias^2 + variance
- But it’s the error you want to minimize, not bias or variance specifically.
- A complex model will have high variance and low bias.
- A too-easy model can have low variance and high bias.
- But both may have the same error.
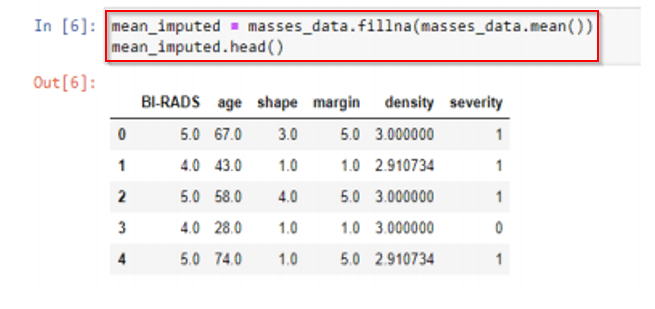
Q2: How to impute missing data using Mean Replacement?
A: Replace missing values with the mean value from the rest of the column (columns, not rows! A column represents a single feature; it only makes sense to take the mean from other samples of the same feature.)
Fast & easy, won’t affect the mean or sample size of the overall data set
Median could also be a far better alternative than mean once outliers are present
Q3: Why drop the row to solve the missing data in Problem?
A: If many rows contain missing data and dropping those rows doesn’t bias your data and you don’t have a lot of time, maybe it’s a reasonable thing to do
But it’s never going to be the right answer for the “best” approach
Almost anything is better. Can you substitute another similar field perhaps? (i.e., review summary vs. full text)
Q4: How to impute missing data using machine learning techniques?
A:
| KNN (k-nearest neighbors) | Deep Learning | Regression |
|---|---|---|
| Find K “nearest” (most similar) rows and average their values. | Build a machine learning model to impute data for your machine learning model! | Find linear or non-linear relationships between the missing feature and other features |
| Assumes numerical data, not categorical There are ways to handle categorical data (Hamming distance), but categorical data is probably better served by… |
Works well for categorical data. Really well. But it’s complicated. | Most advanced technique: MICE (Multiple Imputation by Chained Equations). |
Q5: Is there any other way to impute missing data?
A: Yes, there is a classical method, we have to get the missing data by getting more data. But sometimes you must just try harder or collect more data.
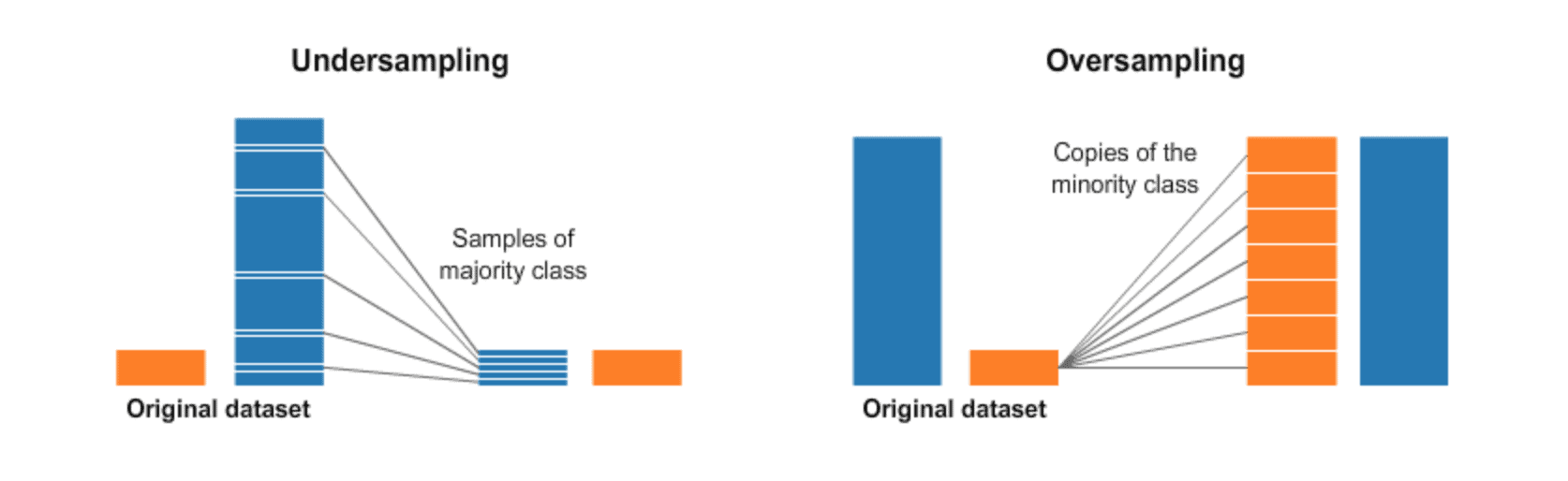
Q6: What is Oversampling and Undersampling?
A: Oversampling is a technique in which we have to duplicate the samples from the minority class and it can be done randomly.
Undersampling is a technique in which we have to delete the samples from the majority class and instead of creating more positive samples, remove negative ones.
Q7: What is Binning?
A: Binning may be a technique that accomplishes precisely what it feels like. it’ll take a column with continuous numbers and place the numbers in “bins” supported ranges that we tend to confirm. this can provide us a new categorical variable feature.
Example: estimated ages of people, Put all 20-somethings in one classification, 30-somethings in another, etc.
Check Out: Amazon Rekognition Pricing. Click here
> Data Engineering In AWS
Before a model is built, before the data is cleaned and made ready for exploration, even before the role of a data scientist begins – this is where data engineers come into the picture. Every data-driven business needs to have a framework in place for the data science pipeline, otherwise, it’s a setup for failure.

Basically, So the data Engineer is doing some designing and scaling systems that organize data for analytics.
Q8: What is Amazon S3?
A: Amazon S3 contains a simple web services interface that you can simply use to store and retrieve any amount of data, at any time, from anywhere on the web. Buckets are the basic containers for data storage in Amazon S3.

Q9: What is S3?
A: Amazon S3 (Simple Storage Service) provides object storage which is built for storing and recovering any amount of information or data from anywhere over the internet.
- Amazon S3 provides storage through a web services interface
- It is designed for developers where web-scale computing can be easier for then
- It provides 99.999999% durability and 99.99% availability of objects
- It can store computer files up to 5 terabytes in size
Q10: What are the benefits of S3?
A: There are much more advantages of s3 as per disadvantages. Some of them are mentioned below:
- Durability
- Low cost
- Scalability
- Availability
- Security
- Flexibility
- Simple data transfer
Q11: What is the Object and bucket in S3?
A: An Object consists of data, key (assigned name), and metadata. The bucket is where the object is being stored When data is added to the bucket, Amazon S3 creates a unique version ID and allocates it to the object

Q12: How does Amazon S3 Work?
A: When files are uploaded to the bucket, the user will specify the type of S3 storage class to be used for those specific objects
Later, users will outline options to the bucket like bucket policy, lifecycle policies, versioning management etc

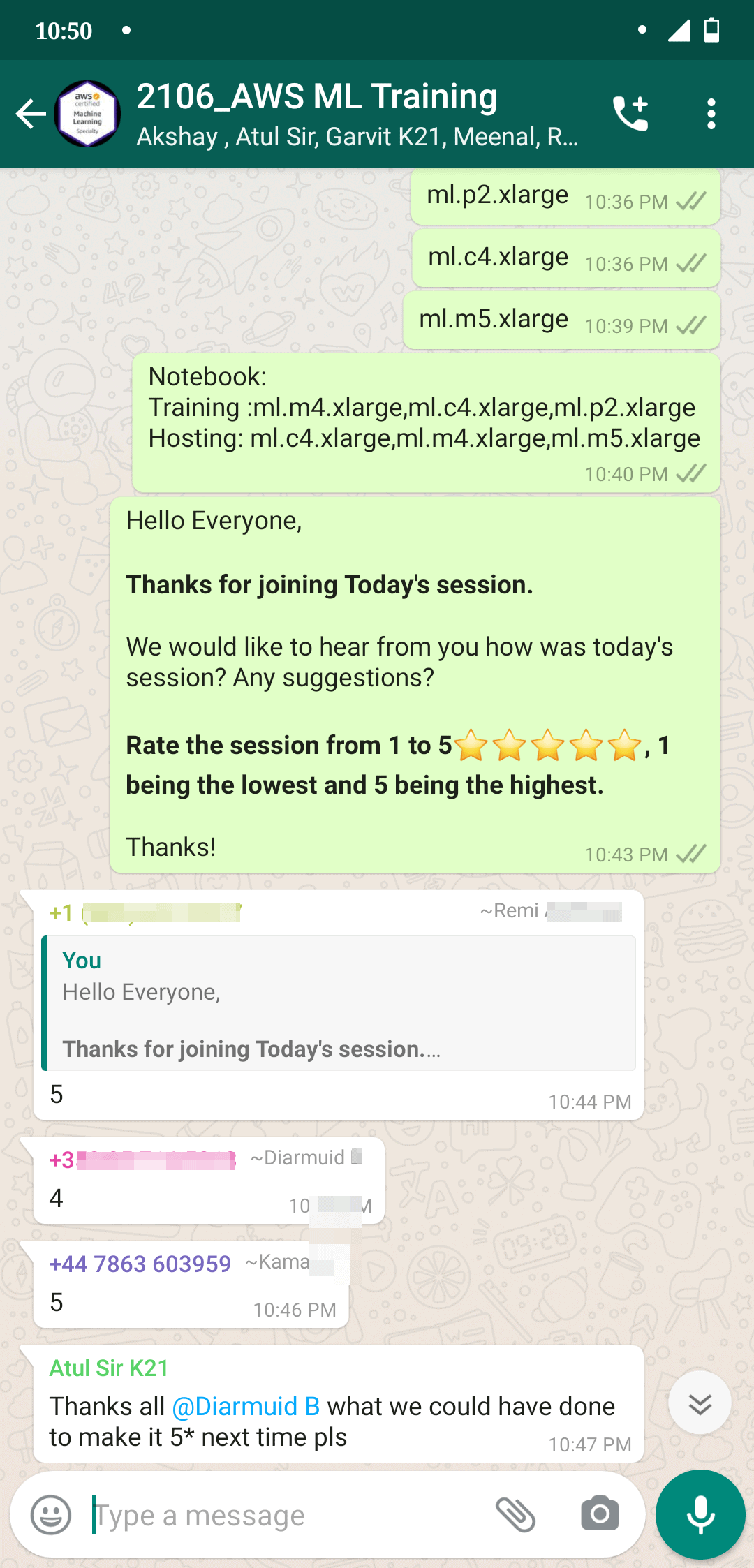
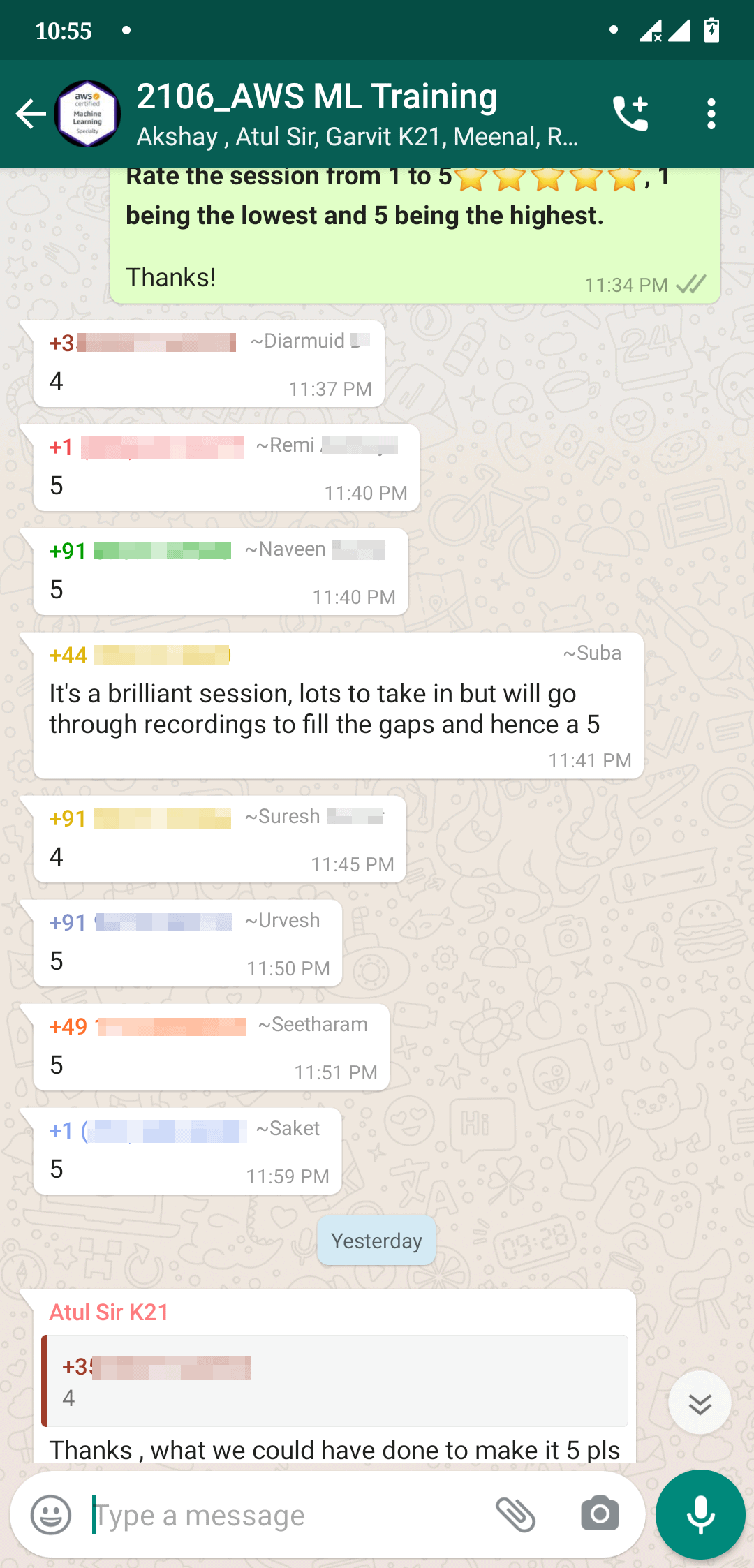
Feedback Received…
From our AWS-ML Day 3 & day 4 session, we received some good feedback from our trainees who had attended the session, so here is a sneak peek of it.
To know more about AWS-ML certification and whether it is the right certification for you, read our blog on AWS Certified Machine Learning – Specialty[MLS-C01]: Everything you must know
Quiz Time (Sample Exam Questions)!
With our AWS Certified Machine Learning – Specialty training program, we cover 150+ sample exam questions to help you prepare for the certification [MLS-C01].
Check out one of the questions and see if you can crack this…
Ques: Amazon S3 is which type of storage service?
A) Object
B) Block
C) Simple
D) Secure
Comment with your answer & we will tell you if you are correct or not!!
Related/References
- AWS Certificate Manager: Overview, Features and How it Works?
- Data Engineering With AWS Machine Learning
- AWS Database Services – Amazon RDS, Aurora, DynamoDB, ElastiCache
- Multi-Account Management Using AWS Organizations
- AWS Certified Solutions Architect: Roles & Responsibilities
- Amazon Kinesis Overview, Features And Benefits
- AWS Certified Machine Learning Specialty: All You Need To Know
Next Task For You
If you are also interested and want to more about the AWS certified Machine Learning Specialist then join the Waitlist.






![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



