




![]()
Transform data into insights with the power of these AWS services!
In this blog, we’ll explore important AWS services that are essential for Data Engineers, offering valuable insights and knowledge to boost your success in the field.
To secure a job as an AWS Data Engineer and successfully obtain the AWS Data Engineer Certification, it’s essential to focus on becoming proficient in various AWS services, especially those focused on data processing, storage, analysis, and security.
Explore hands-on labs and real-world projects in AWS Data Engineering, which is ideal for job preparation and certifications, or dive into our blog, AWS Exploration: Amazon Web Services, designed for complete beginners to AWS Cloud.
Here are key AWS services for Data Engineer and areas you should focus on:
- Core AWS Services
- Database Services
- Data Integration Services
- Big Data & Data Analytics
- Application Integration Services
- Data Migration Services
- Machine Learning
- Security and Identity Services
- Monitoring and Management
- Container
- Development Tools
- Conclusion
Core AWS Services
AWS Data Engineering Core Services facilitate different phases of data processing. Data engineers may create secure, scalable, and effective data pipelines with the help of these services, which encourages creativity and insights inside businesses.
1. Amazon S3

Consider Amazon S3 as an enormous digital storehouse where you may arrange and keep all of your possessions (data in this scenario). It’s similar to having a limitless room for storing documents, films, and pictures. S3 ensures that your possessions are safe and easy to find when needed.
How does it operate? You can upload your files into “buckets,” which are containers that you construct for storage. When you require your files, you can retrieve them via the internet by utilizing a special URL that leads to your particular file and bucket.
Related Readings: the AWS S3 Bucket
2. Amazon EC2

Cloud computing capability that is scalable is provided via EC2. Data processing, ETL, and other computation-intensive activities can be executed on EC2 instances by data engineers.
To create and deploy applications more quickly, Amazon EC2 eliminates the upfront hardware investment. Organizations must invest a significant amount of money in purchasing hardware components, and managing them is even more stressful than purchasing them. With EC2, you can set up networking and security, manage storage, and launch as many or as few virtual servers as you require. You no longer need to forecast traffic because EC2 allows you to scale up or down to accommodate required changes or surges in popularity.
Related Readings: AWS EC2 Instance
3. AWS Identity and Access Management (IAM): For Data Encryption

Security is a major concern at all times, particularly when handling private information. For any AWS service, we use,
We can use IAM to create a specific role that only has the necessary permissions, following the idea of least privilege.
The identity management capabilities of the IAM service include support for identity federation and tools for managing authorizations for operations against AWS services such as Amazon SageMaker and Amazon S3. For each AWS service they use, data engineers can create roles using IAM that follow the least privilege concept.
Related Readings: AWS Identity And Access Management (IAM)
4. Networking Services
For data engineering to guarantee dependable and effective connections between diverse data system components, networking services are crucial. To meet these demands, AWS provides a selection of networking services. By utilizing these networking services, data engineers can create strong and safe network designs that facilitate effective communication and data movement inside their data systems.
Related Readings: AWS Networking Fundamentals
4.1 Amazon VPC (Virtual Private Cloud)
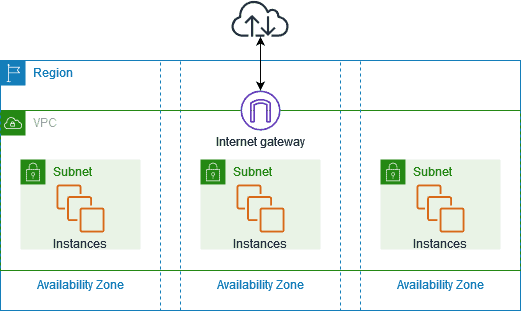
One of Amazon Web Services’ most well-liked and often utilized services is AWS VPC. This is typical because Amazon VPC primarily deals with cloud security principles and data access within third-party data centers. AWS VPC is a private area of AWS where you can store databases and EC2 instances, among other AWS resources. Who can access the resources you put inside the AWS Virtual Private Cloud is completely under your control.
Related Reading: Amazon Virtual Private Cloud Benefits & Components
4.2 AWS Direct Connect
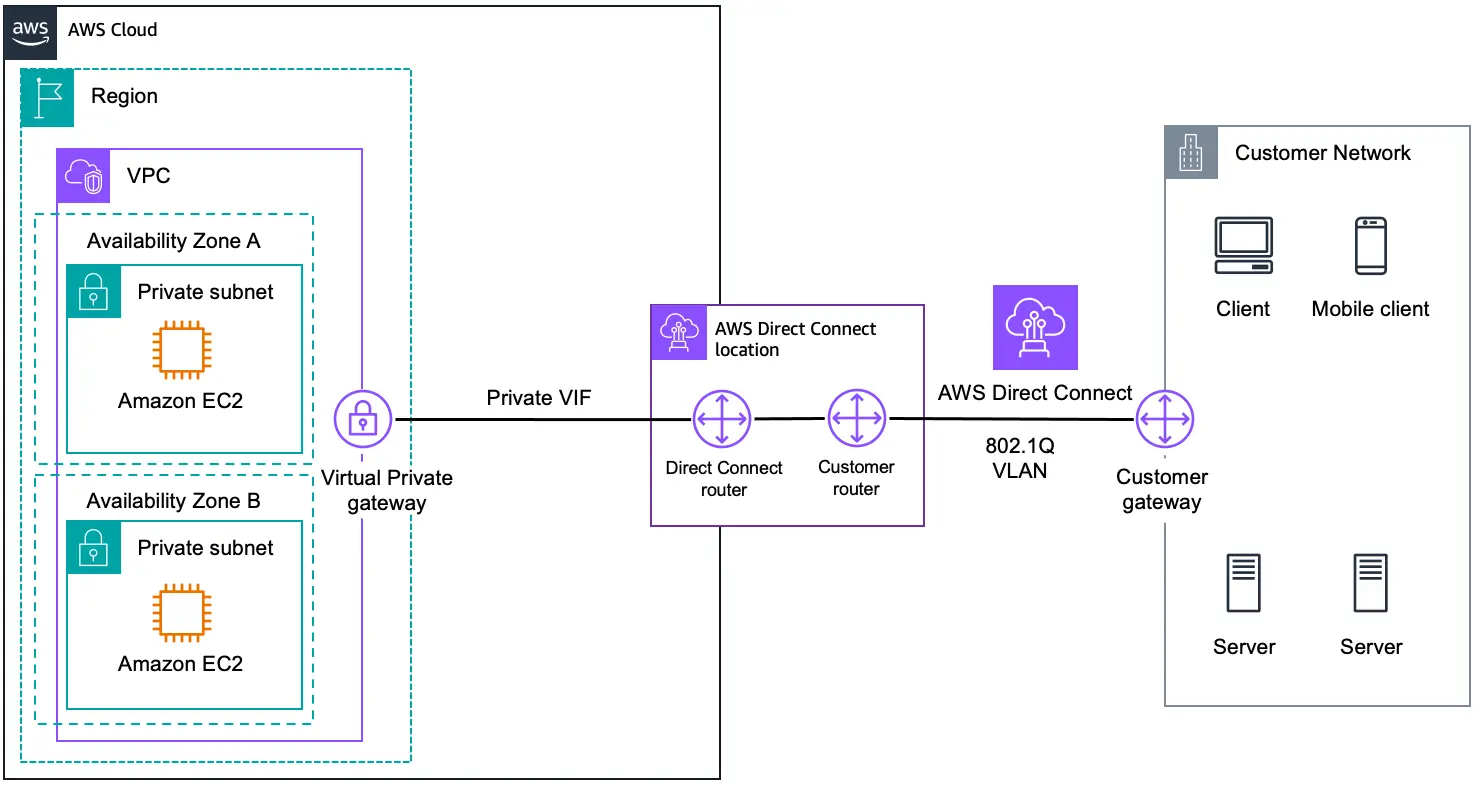
It utilizes a regular Ethernet fiber-optic cable to connect your internal network to an AWS Direct Connect site. The cable is attached to your router on one end and to an AWS Direct Connect router on the other. By passing internet service providers in your network path, you can construct virtual interfaces to public AWS services using this connection.
AWS Direct Connect locations give users access to AWS in the region they are connected to. To access public AWS services in all other public regions, you can use a single connection in a public region or AWS GovCloud (US).
Want to know more about this service? please refer to: AWS Direct Connect
Database Services
AWS provides a range of database services to meet the demands of data engineers. Data engineers can handle, store, and analyze data more effectively thanks to database services, which also make it easier to create scalable and reliable solutions.
 Related Readings: AWS Database Services
Related Readings: AWS Database Services
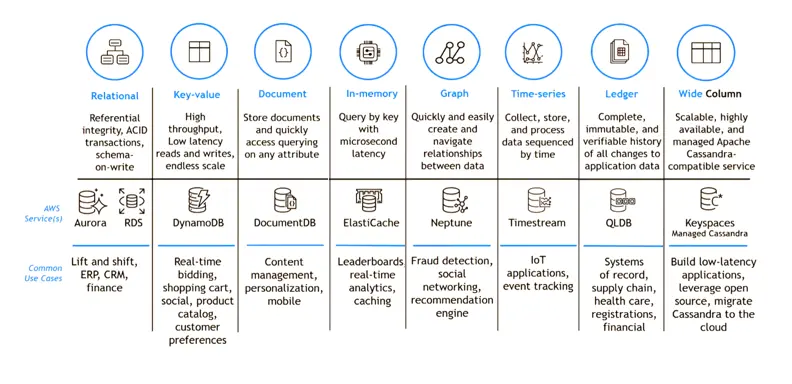
1. Amazon RDS
The databases are managed and arranged for you by Amazon RDS, which functions similarly to a helpful assistant. It makes working with your preferred database easier by supporting a variety of database types.

Supported database engines in AWS RDS:
- MySQL: An open-source relational database management system known for its ease of use, flexibility, and strong community support.
- PostgreSQL: An advanced open-source database known for its reliability, robustness, and support for complex data types and advanced features.
- MariaDB: A community-developed fork of MySQL, designed for performance, scalability, and high availability while maintaining compatibility with MySQL.
- Oracle: A commercial relational database management system known for its enterprise-grade features, scalability, and comprehensive data management capabilities.
- SQL Server: A commercial database management system developed by Microsoft, offering comprehensive features for data management, business intelligence, and integration.
- Amazon Aurora: A cloud-native relational database engine built for high performance, scalability, and availability, designed to be compatible with MySQL and PostgreSQL.
How does it operate? RDS configures and manages the database for you after you select a database type (such as PostgreSQL or MySQL). It handles maintenance, scaling, and backups, so you can concentrate on working with your data.
Related Readings: Amazon RDS
2. Amazon DynamoDB
Consider Amazon DynamoDB as an extremely effective data file cabinet. Even as the volume of data increases, our NoSQL database can store and retrieve data rapidly.
 How is it operated? Your data is stored in DynamoDB tables, which you design and can contain various kinds of data (e.g., shopping carts, and user profiles). When you need to store or retrieve data, you submit requests to DynamoDB, and even with growing amounts of data, it finds and returns the data quickly.
How is it operated? Your data is stored in DynamoDB tables, which you design and can contain various kinds of data (e.g., shopping carts, and user profiles). When you need to store or retrieve data, you submit requests to DynamoDB, and even with growing amounts of data, it finds and returns the data quickly.
Related Readings: Amazon DynamoDB
3. Amazon Redshift

All of your data is stored and arranged in an enormous library-like manner on Amazon Redshift. It facilitates rapid and effective data searching, making it simple to locate the answers you want
How does it operate? Your data is loaded into Redshift, where it is stored in tables, in an organized format. Subsequently, you can query Redshift for fast answers to search and analyze the data using SQL, a computer language.
Data Integration Services
Data integration services are essential to data engineering because they make it easier to move and consolidate data across different sources in an efficient manner. AWS provides an extensive range of data integration services aimed at optimizing these procedures. Data engineers may effectively combine various data sources using these services, guaranteeing consistency and dependability in their data pipelines.
1. AWS Glue

When it comes to organizing and cleaning up your data, Amazon Glue is similar to a very intelligent robot. Your data can be automatically found, sorted, and then formatted appropriately so that analysis can begin. You save time and can deal with your data more easily as a result.
How is it operated? For you to know what’s in your data, Glue automatically scans your data and generates a “data catalog”—akin to a thorough inventory list. After that, it can use code, or ETL scripts, to format and reorganize your data so that it is suitable for analysis.
Related Readings:: AWS Glue
2. Amazon Data Pipeline

AWS Data Pipeline transfers data from one location to another like a conveyor belt. It facilitates data processing and analysis by transferring data from on-premises sources or between other AWS services.
How does it operate? When setting up a Data Pipeline, you provide the sources (where your data originates) and destinations (where it travels), as well as any transformations (if any) that should be performed on the data along the way. After that, Data Pipeline transports the data automatically by your instructions, simplifying the processing and analysis of the data in various AWS services or on-premises systems.
Related Readings: AWS Data Pipeline
Big Data &Data Analytics
Data engineering relies heavily on analytics and machine learning to drive smart decision-making and extract useful insights. AWS offers a full range of services designed specifically for machine learning and analytics applications. These services enable data engineers to uncover patterns in data, stimulate innovation inside their companies, and leverage the power of analytics and machine learning.
1. Amazon EMR (Elastic MapReduce)

Consider yourself faced with a massive puzzle that requires assistance to fit all the parts together. Amazon EMR helps you process and analyze large amounts of data, much like a group of enigma solvers. To answer the riddle more quickly and easily, they make use of tools like Hadoop and Spark.
How does it operate? Your data is divided into smaller pieces by the EMR as you load it. Subsequently, EMR uses many computers, referred to as nodes, to process the chunks concurrently, resulting in increased speed and efficiency. After processing is complete, the EMR compiles the findings for additional examination.
Related Readings:: AWS EMR
2. Amazon Athena

Amazon Athena is similar to a lightning-fast search engine that uses SQL to extract information from your data. Because you don’t need to manage or set up any infrastructure in order to utilize it, it is incredibly convenient.
How does it operate? You ask Athena questions about your data with SQL queries, and it looks for the answers in the data that is kept on Amazon S3. Since Athena handles all the heavy lifting, you are spared from having to manage or set up any infrastructure.
Related Readings: Amazon Athena
3. Amazon Kinesis

For real-time streaming data collection and analysis, Amazon Kinesis provides several managed cloud-based services. Data engineers can quickly define requirements, create new streams, and start streaming data by using Amazon Kinesis. Furthermore, engineers can now obtain and analyze data immediately instead of waiting for a data-out report, thanks to Kinesis.
How does it operate? You configure Kinesis to gather incoming data (such as sensor readings or tweets). After that, it runs code to process the data in real time (e.g., to count words or calculate averages) and sends the results to storage systems or other services for additional analysis.
Related Readings: What is AWS Amazon Kinesis?
4. AWS Lake Formation

The ability to fine-tune the security control of data access, even on a particular column, is made possible by the Lake Formation. This service was launched only a year ago. I haven’t had a chance to experiment yet.
Related Readings: AWS Lake Formation: Overview, Architecture & Functionality
5. Amazon Simple Workflow (SWF)

Amazon Simple Workflow Services (Amazon SWF) are task-oriented application interfaces designed to facilitate the coordination of various tasks across dispersed application components. Here, tasks stand for a logical work unit that the application is completing. In accordance with the application’s logical flow, it involves scheduling, concurrency, and intertask interdependence.
Related Readings: Understanding AWS Simple Workflow Service (SWF)
Application Integration Services
1. AWS Step Functions
With AWS Step Functions, developers can design and oversee multi-step application workflows in the cloud using a serverless orchestration platform. Through the use of the service’s drag-and-drop visual editor, teams can quickly combine separate microservices into cohesive processes. So that developers may concentrate on higher-value business logic for their applications, Step Functions handles input, output, error handling, and retries at each stage of a particular process.
Related Readings: AWS Step Functions
Data Migration Services
1. AWS Database Migration Service (DMS)

Quick and secure database migration from on-premise DB instances, databases, or databases running on AWS EC2 instances to the cloud is made possible by the AWS Database Migration Service (DMS), a managed and independent service. It allows you to transfer, manage, and alter your AWS cloud setups. Redshift, Aurora, Amazon RDS, ElasticCache, DynamoDB, and Aurora are among the available databases.
The Schema Conversion Tool (SCT): It is a tool provided by AWS to help move database setups from one type of database to another. It’s especially handy when you’re switching between different kinds of databases. It takes care of translating things like tables, indexes, and other parts of your database so that they work properly in the new setup. This helps keep your data safe and minimizes any interruptions during the switch.
How does it operate? The regulated and automated migration service provided by AWS DMS makes it feasible to move data between databases. The method starts with integrating DMS into the endpoints (source and target). To use AWS DMS, you need to host one of your endpoints on an AWS service.
Related Readings: AWS Database Migration Service
2. AWS Snowball

You can move hundreds of terabytes or petabytes of data between Amazon Simple Storage Service (Amazon S3) and your on-premises data centers using AWS Snowball (Snowball). For physical transportation, it mostly uses a secure storage device.
Data identification, compression, encryption, and transport are all accomplished with the AWS Snowball Client program, which is installed locally on a PC. Snow devices feature 256-bit encryption (managed by AWS KMS) and tamper-resistant casings with TPM to protect user data.
Related Readings: AWS Snow Family
Machine Learning
1. Amazon SageMaker

A managed service offered by Amazon Web Services (AWS) in the public cloud is Amazon SageMaker. For predictive analytics applications, it offers the resources needed to create, hone, and implement machine learning (ML) models. The platform streamlines the laborious process of creating an artificial intelligence (AI) pipeline that is ready for production.
Machine learning has several advantages and applications. Detecting threats to back-end security and using advanced analytics for client data are two examples.
Related Reading: Amazon AWS SageMaker
Security and Identity Services
Data engineering, security, and identity services are critical to protecting sensitive data and guaranteeing safe resource access. To meet these needs, Amazon provides a whole range of services. The AWS Security Hub also provides centralized security monitoring and cross-account compliance checks. Data engineers can use these services to put strong security measures in place, protect data assets, and stay in line with industry requirements.
2. AWS Key Management Service (KMS)

AWS KMS is a reliable and secure solution that protects our keys using hardware security mechanisms that have been tested or are currently being evaluated. You can encrypt data within your apps and manage the encryption of stored data across AWS services with the help of the AWS Key Administration Service, which offers highly available key storage, administration, and auditing.
Related Readings: AWS Key Management Service
Monitoring and Management
To guarantee the efficient operation and optimization of data systems, monitoring, and administration are crucial elements of AWS Services for Data Engineering. AWS provides an extensive range of services designed specifically for tracking and controlling data operations. Data engineers may check performance indicators and quickly identify anomalies with the help of Amazon CloudWatch’s logging and monitoring features. Data engineers may efficiently monitor, troubleshoot, and optimize their data workflows with the help of these monitoring and management services, guaranteeing performance and dependability at scale.
1. Amazon CloudWatch

You can create a single, highly scalable service out of all of your system, application, and AWS service logs with the aid of AWS CloudWatch. When developing, it’s helpful to keep a debug log, which data engineers may find in CloudWatch along with the logs for the services they run. With CloudWatch Events, engineers may plan the services they wish to launch at a specified time.
Related Readings: What is CloudWatch?
2. AWS CloudFormation

Amazon With the use of CloudFormation, you can streamline the modeling and configuration of your AWS resources and free up more time to concentrate on your AWS-running apps rather than managing them. CloudFormation handles the deployment and configuration of your desired AWS resources (such as Amazon EC2 instances or Amazon RDS DB instances) once you create a template that lists them all.
Related Readings: AWS CloudFormation
Container
1. Amazon Elastic Kubernetes

Applications can be deployed with Kubernetes by integrating natively with Amazon Elastic Kubernetes Service (EKS), a cloud-based container management tool.
AWS Kubernetes clusters of infrastructure resources are automatically managed and scaled via the EKS service. Installing, running, and maintaining the container orchestration software is not necessary for a company using Kubernetes thanks to Amazon EKS.
Related Readings: Amazon EKS (Elastic Kubernetes Service): Everything You Should Know
Development Tools
1. AWS Lambda

AWS Lambda is a serverless computing solution that easily controls the underlying computing resources while executing your code in response to events. Lambda is useful when gathering raw data is necessary. To visit an API endpoint, get the result, process the data, and save it to S3 or DynamoDB, data engineers can create a Lambda function.
Related Readings: AWS Lambda: Serverless Compute Service
2. Amazon Quicksight

When data analytics and insights are presented to stakeholders and the business, visualization makes sense much more readily. With Amazon QuickSight, it’s simple to make and share interactive dashboards that can be delivered via email, seen on any device, and integrated into other programs and websites. A managed serverless business intelligence solution is called Amazon QuickSight. RedShift and S3, two AWS services, have native integration with the data sources.
Related Reading: Amazon QuickSight: A Business Intelligence Service
https://www.youtube.com/watch?v=Qwvy6dPHKBU
Conclusion
In the field of data engineering, becoming proficient with AWS Services for Data Engineering is critical to opening up countless opportunities and succeeding in your professional path. From data processing and storage to analytics and machine learning, AWS provides an extensive range of services designed to satisfy the needs of contemporary data engineering.
Aspiring data engineers may construct strong data pipelines, evaluate huge datasets, and produce useful insights for their companies by concentrating on essential AWS services like Amazon S3, Amazon EC2, and AWS Glue.
Remember to use Real-World Projects and Interactive Labs to enhance your comprehension and practical abilities as you begin your journey to become an AWS Data Engineer and work towards Certification. You’ll be well-equipped to succeed in the fast-paced profession of data engineering and have a significant impact on the industry with commitment, ongoing education, and practical experience.
Related Links/References
- AWS Data Engineer: Hands-On Labs & Projects for Jobs & Certification Bootcamp
- AWS Certified Data Engineering Associate DEA-C01 Exam
- AWS S3 Bucket
- AWS Exploration: Amazon Web Services
- Get Started with AWS: Creating a Free Tier Account
Frequently Asked Questions
What skills are essential for a data engineer working with AWS tools?
To secure a job as an AWS Data Engineer and earn the AWS Data Engineer Certification, focus on mastering key AWS tools such as AWS Glue for ETL, Amazon Kinesis for real-time data streaming, Amazon S3 for storage, Amazon RDS for relational databases, Amazon Redshift for data warehousing, and AWS QuickSight for business intelligence. Additionally, understanding AWS Identity and Access Management (IAM) for security is crucial. By honing these skills, you’ll be well-prepared for data engineering roles and meet the expectations of most job descriptions.
What are the capabilities of Amazon Redshift as a data warehousing solution?
Amazon Redshift is a powerful data storage and analysis tool that organizes data in tables, enabling fast and efficient querying using SQL. It handles large volumes of data with petabyte-scale capacity, offering serverless functionality for easy data import and querying without managing infrastructure. Advanced features like schema and table creation, visual data import, and Query Editor v2 help users navigate and analyze data effortlessly, making Redshift essential for data-driven decisions in any organization.
What are the top AWS services used for data engineering projects?
Top AWS services for data engineering include Amazon S3 for scalable storage, AWS Glue for ETL processes, Amazon Redshift for data warehousing, Amazon RDS for relational databases, Amazon Kinesis for real-time data streaming, AWS Lambda for serverless compute, Amazon DynamoDB for NoSQL storage, Amazon EMR for big data processing, Amazon Athena for querying data in S3, and AWS Data Pipeline for orchestrating data workflows. These services enable efficient, scalable, and secure data processing and analytics.
How does Amazon Athena enable interactive querying of data stored in Amazon S3?
Amazon Athena enables interactive querying of data stored in Amazon S3 by allowing users to run SQL queries directly on the data without needing to move it into a database. It is serverless, meaning there is no infrastructure to manage. Athena automatically scales to handle large datasets, making it easy to analyze structured, semi-structured, and unstructured data directly from S3, and it only charges for the amount of data scanned by each query.
Next Task For You
Begin your journey toward becoming an AWS Data Engineering Program Bootcamp by clicking on the below image and joining the waitlist.







![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



