




![]()
Understanding data can be tricky, but there are tools to help. One of them is Amazon Athena, an Amazon service that simplifies data analysis. This tutorial will walk you through how to use Amazon Athena, both for beginners and those who want to dive deeper into it.
In this blog, we’ll explore Amazon Athena—a tool that simplifies data analysis.
Topics Covered in the blog:
- What is Amazon Athena?
1. Key Features
2. Benefits - How does Amazon Athena work?
- Common Use Cases for Amazon Athena
- How to create a table in Amazon Athena?
1. Manually
2. Using AWS Glue Crawler for table creation: - When should I use Athena?
- How Much Does Athena Cost?
1. Optimizing AWS Athena Costs - AWS Services Comparisons
- How to differentiate between Amazon Athena and Amazon Redshift?
- Conclusion
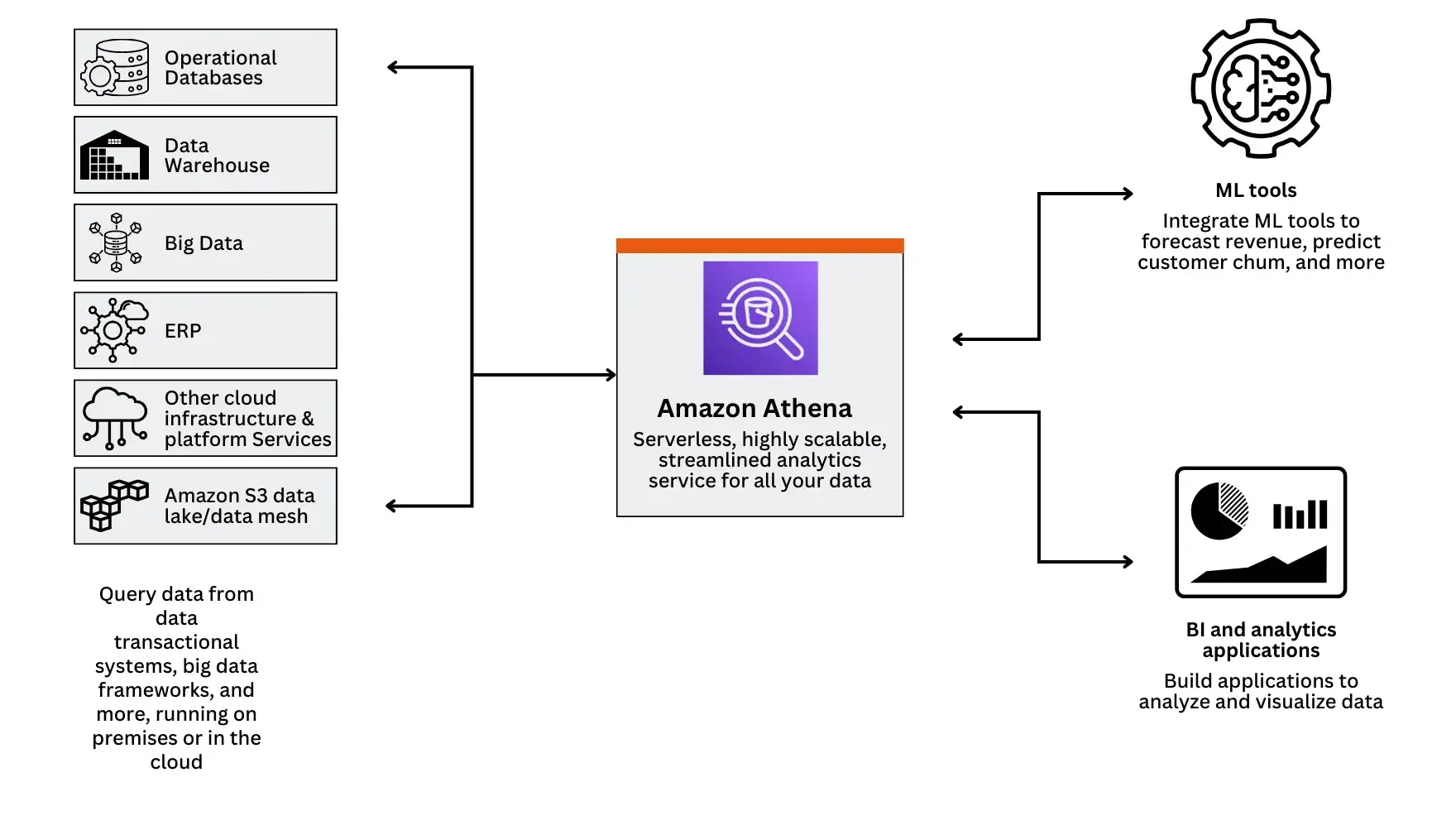
What is Amazon Athena?
Amazon Athena, launched by Amazon in November 2016, is a service designed for analyzing data stored in Amazon S3 using standard SQL queries. It’s like having a super-fast detective for your data! With Athena, there’s no need to set up or manage any infrastructure—it’s completely serverless. Plus, you only pay for the queries you run, making it cost-effective. All you have to do is point your data stored in Amazon S3(Simple Storage Service), define the schema (how your data is organized), and start querying using standard SQL.
Key Features:
- Serverless: No need to set up or manage any computer stuff. Just focus on analyzing data without worrying about tech stuff.
- Standard SQL Queries: Use regular English-like commands to ask questions about your data. Easy for anyone who knows a bit of SQL.
- Integration with Amazon S3: Easily connect to your data stored in Amazon S3, like opening files from a folder.
- Scalability: Works fast even with big data and complex questions. It can handle a lot without slowing down.
- Pay-Per-Query Pricing: You only pay for the questions you ask, which keeps costs low for both big and small projects.
- Ease of Use: It’s simple to use with a user-friendly interface. Just log in and start asking questions without any hassle.

Benefits:
- Efficiency: Amazon Athena helps you quickly understand big sets of data, so you can make decisions faster.
- Cost-Effective: You only pay for the questions you ask, which saves money on data analysis.
- Accessibility: If you know a bit of SQL, you can easily ask Athena questions without fancy tools.
- Scalability: Athena can manage an increasing amount of data as your requirements expand, ensuring seamless operations.
- Integration: Utilising Athena with Amazon S3 is simple, allowing you to analyze data straight out of your storage buckets.
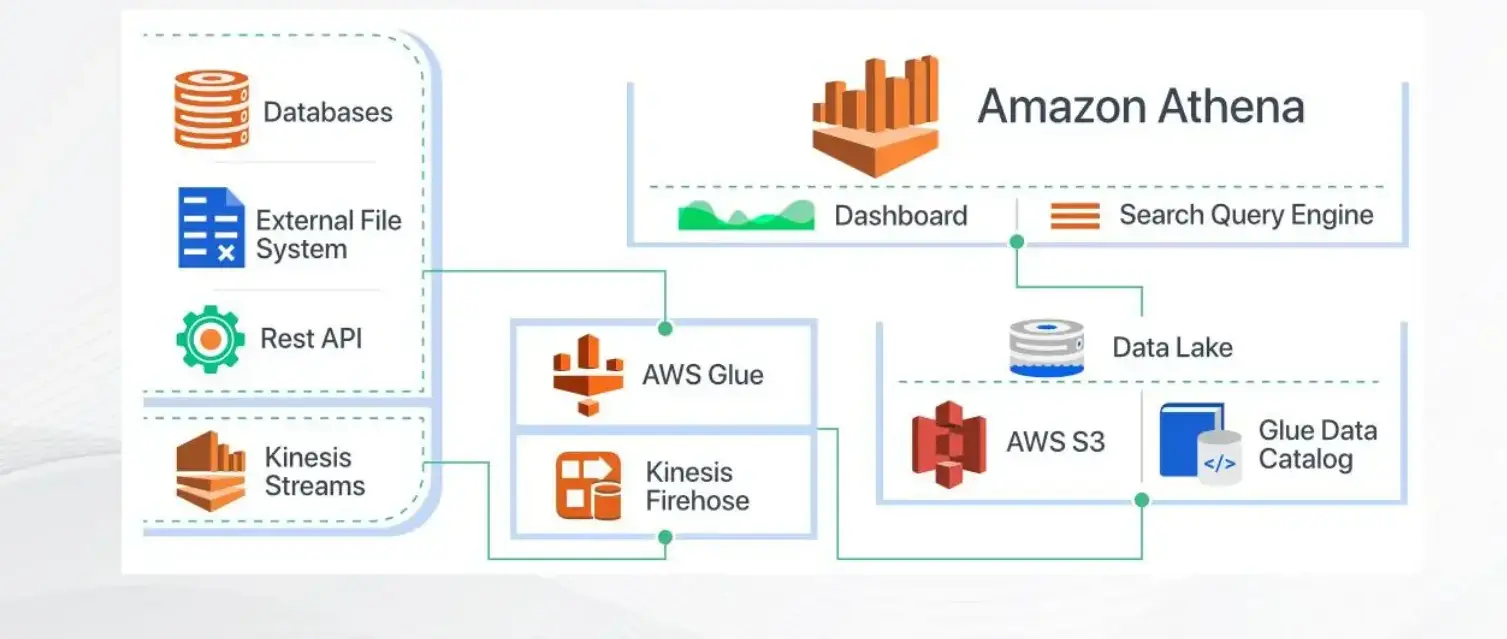
 How does Amazon Athena work?
How does Amazon Athena work?
 How does Amazon Athena work?
How does Amazon Athena work?Here’s a simplified workflow of how Amazon Athena works:
- Data Storage: Amazon S3 (Simple Storage Service) buckets are where you keep your data. These could be several kinds of data, such as Parquet files, JSON, CSV files, or even logs.
- Create Table: In Athena, you define a table schema that points to the location of your data in S3. This step tells Athena how to interpret the data.
- Data Preparation Using Data Tools: Leverage data tools such as AWS Glue, Apache Spark, or AWS Data Wrangler to clean, format, and transform your data stored in S3. These tools ensure your data is structured and optimized for querying in Athena.
- Query Execution: You write SQL queries using standard SQL syntax. When you submit a query to Athena, it analyzes the query and orchestrates the execution across a managed fleet of servers.
- Parallel Processing: Athena automatically parallelizes your query across multiple servers, which allows it to process large amounts of data quickly.
- Data Retrieval: Once the query is executed, Athena retrieves the relevant data from S3, processes it according to your query, and returns the results.
- Result Presentation: Finally, Athena presents the results of your query back to you, typically in tabular format. You can visualize or further analyze these results as needed.
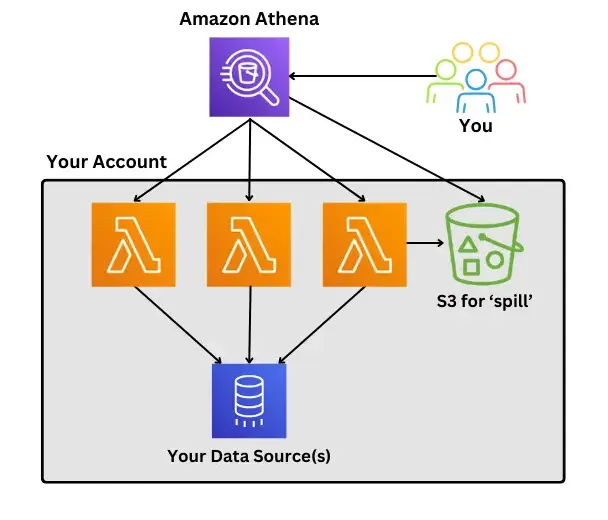
 Common Use Cases for Amazon Athena
Common Use Cases for Amazon Athena
 Common Use Cases for Amazon Athena
Common Use Cases for Amazon Athena- Data Analysis and Exploration:
1. Athena enables users to perform ad-hoc analysis on large datasets stored in S3 without the need for setting up and managing complex infrastructure.
2. Analysts and data scientists can run SQL queries to explore data, identify patterns, and derive insights quickly. - Serverless Data Warehousing:
1. For organizations that require on-demand analytics without the overhead of managing traditional data warehouse infrastructure, Athena offers a serverless solution.
2. Users can run complex SQL queries against structured and semi-structured data in S3, achieving agility and cost-efficiency. - Business Intelligence (BI) and Reporting:
1. Athena integrates seamlessly with popular BI tools like Tableau, Amazon QuickSight, and Power BI, enabling users to create dashboards and reports based on real-time data.
2. Analysts can visualize query results and share insights across the organization for informed decision-making.
How do you create a table in Amazon Athena?
To analyze data stored in Amazon S3 using Amazon Athena, you need to create a table that’s linked to your data files. The good news is, that you’re only charged for the queries you run, not for the data itself. However, if you’re uploading data files to Amazon S3, charges will apply.
There are two ways to create external tables in Athena:
- Manual Creation: You can manually define the structure of your data files and create an external table in Athena to access them.
- Using AWS Glue Crawler: Alternatively, you can use AWS Glue Crawler, a tool that automatically discovers the schema and structure of your data files in Amazon S3 and creates the corresponding external table in Athena. This method saves time and effort, especially for large datasets with complex structures.
Manual Creation Of Table in Amazon Athena:
- Define Structure: You specify the layout of your data, including column names and data types (like text, numbers, and dates).
- Location: You tell Athena where to find your data in Amazon S3.
- Format: You specify the format of your data, whether it’s CSV, JSON, Parquet, etc.
- Partitioning (optional): If your data is partitioned, you define the partition keys, which help Athena optimize queries.
- DDL Statement: You use Data Definition Language (DDL) statements in SQL to create the table based on the defined structure.
Using AWS Glue Crawler for table creation:
- Data Discovery: AWS Glue Crawler automatically scans your data stored in Amazon S3 to understand its structure and format.
- Schema Inference: Based on the scanned data, the crawler infers the schema, including column names and data types.
- Table Creation: With the inferred schema, the crawler creates tables in the AWS Glue Data Catalog, which serves as a metadata repository.
- Integration with Athena: Once tables are created in the Glue Data Catalog, they become accessible to Amazon Athena for querying using SQL.
- Automation: AWS Glue Crawler can be scheduled to run at regular intervals, ensuring that your table definitions stay up-to-date as new data is added or existing data changes.
When should I use Athena?
- When you need to analyze massive amounts of data where it’s stored without having to worry about managing any infrastructure, you should utilize Amazon Athena.
- It is especially helpful for fast analysis and ad hoc querying of S3 data.
- You only pay for the queries you run with its pay-per-query pricing approach, and the amount of data scanned by each query determines how much you are paid.
- It leverages Amazon S3 as its underlying data store and compute resources to run queries across various availability zones, Amazon Athena is also highly available and durable.
How Much Does Athena Cost?
Amazon Athena offers a pay-per-query pricing model, which means you only pay for the queries you run, without any upfront costs or ongoing commitments. Here’s a breakdown of the key factors affecting Athena’s pricing:
Pay-Per-Query Billing:
- Cost Starts at $5 for scanning each terabyte (TB) of data.
- You pay based on how much data your queries scan, with a minimum charge of 10 megabytes (MB) per query.
- No extra fees for scanning data.
SQL Queries with Provisioned Capacity:
- Cost Begins at $0.30 per hour for each Data Processing Unit (DPU), calculated per minute.
- DPUs decide the resources needed for queries, offering 4 virtual CPUs and 16 GB of memory.
- You’re charged based on the capacity and time you use, with an 8-hour minimum.
- Scalable: Start with 24 DPUs and adjust in 4 DPU increments.
- No charge for data scanning.
Additional Charges:
- Standard Amazon S3 fees apply for data reading, storing, and transferring.
- Extra charges may occur for querying non-S3 data sources.
- If you use Amazon Glue, standard pricing for the Glue Data Catalog applies.
Optimizing AWS Athena Costs:
- Scan Less: Write efficient queries to scan only the necessary data.
- Partitioning: Organize data in S3 by partitions for faster and cheaper queries.
- File Formats: Use Parquet or other optimized file formats to save money on scanning.
- Compression: Compress data in S3 to minimize scanning costs.
- Data Cleaning: Clean and filter data before querying to reduce unnecessary scans.
- Scheduled Queries: Schedule queries during off-peak hours for lower costs.
- Monitor Usage: Use AWS Cost Explorer to monitor usage and find areas that could use optimization.
AWS Services Comparisons
- Amazon S3 Select vs. Amazon Athena:
S3 Select: Limited to basic SQL SELECT queries on individual objects in structured formats like JSON, CSV, or Parquet.
Athena: supports joins and aggregations on larger, more intricate SQL queries on S3-stored datasets. No restrictions on the kinds of queries.
- Amazon Redshift vs. Amazon Athena:
Redshift: Data warehouse service for complex SQL queries and BI tools. Suitable for combining data from different sources into a unified format.
Athena: Designed for ad-hoc querying of data in S3 using standard SQL. Better for quick, on-demand queries without the need for data warehousing infrastructure.
- Amazon EMR vs. Amazon Athena:
EMR: Runs distributed data processing frameworks like Hadoop and Spark, ideal for custom code, specific cluster setups, and large datasets.
Athena: Serverless querying service for structured data in S3 using SQL. Good for quick analysis without managing clusters or writing custom code.


How to differentiate between Amazon Athena and Amazon Redshift?
| S.No. | Features |
Amazon Athena |
Amazon Redshift |
|---|---|---|---|
| 1. | Service type | Serverless querying service | Data warehousing service |
| 2. | Querying | SQL queries on data stored in Amazon S3 | Complex SQL queries on structured data |
| 3. | Infrastructure | No infrastructure setup or management required | Requires setup and management of data warehouse |
| 4. | Scalability | Automatically scales with query complexity | Can handle large datasets and complex queries |
| 5. | Cost model | Pay-per-query pricing model | Provisioned capacity or pay-as-you-go pricing |
| 6. | use case | Ad-hoc querying, analyzing S3 data | Business intelligence, complex data analysis |
| 7. | Integration | Seamless integration with S3 and other AWS services | Integrates with various AWS Services for analytics |
Conclusion
- Amazon Athena is a powerful and cost-effective tool for analyzing data stored in Amazon S3 using standard SQL queries.
- Its serverless architecture and pay-per-query pricing model make it ideal for organizations seeking insights without managing complex infrastructure.
- By understanding its features, benefits, and pricing, users can efficiently explore large datasets, optimize costs, and drive informed decision-making.
- With options for manual table creation or using AWS Glue Crawler, and comparisons with other AWS services, Athena offers flexibility to meet diverse needs.
- It empowers users to unlock the potential of their data for analysis, data warehousing, and integration with BI tools.
Related Links/References
- AWS Free Tier: Create an Account
- AWS Free Tier Limits
- AWS Shield | DDoS Attacks | AWS Shield Pricing: Overview
- AWS Virtual Private Network (AWS VPN): Everything You Need to Know
- AWS Certified Solutions Architect Associate SAA-C03 Exam details
- Amazon Simple Storage Service Bucket
- Amazon RDS: Introduction & Tutorial
Frequently Asked Questions
How can you Optimizing Pattern Matching in Amazon Athena Queries
To optimize pattern matching in Amazon Athena queries, start by using the LIKE operator for simple patterns, such as prefix searches (e.g., A%). While effective for basic needs, its performance may decline with more complex datasets. For enhanced efficiency and flexibility, leverage regular expressions (REGEX), which allow advanced pattern matching and handle intricate criteria in a single query. REGEX not only improves query speed but also ensures precise results, making it a superior choice for large datasets and complex search patterns.
Why you should use selected Columns in Amazon Athena Queries?
Specifying columns in Amazon Athena queries improves performance and cost efficiency by retrieving only the needed data. This speeds up query execution, reduces network traffic, and minimizes the data scanned, lowering costs. It also simplifies data management by streamlining outputs, enhancing readability, and making analysis more focused and efficient.
How can you Streamline JOIN Conditions in Amazon Athena Queries
To streamline JOIN conditions in Amazon Athena, place larger tables on the left and smaller ones on the right for efficient processing. Choose the appropriate JOIN type (e.g., INNER, LEFT) to minimize unnecessary data. Simplify the ON clause, use partitioning or bucketing for large datasets, and aggregate data early to reduce the volume processed. Regularly analyze and optimize queries for better performance and resource utilization.
What are the important considerations for working with AWS Athena
To effectively use AWS Athena, ensure you have an active AWS account and configure cost and usage data export to an S3 bucket. Prepare S3 buckets for efficient querying and utilize manifest files for organized data management. Choose an optimal region like US-West-2 for better performance and download user credentials to manage secure database access. These steps ensure smooth setup and efficient data analysis.
Next Task For You
Begin your journey toward becoming an AWS Data Engineering Program Bootcamp by clicking on the image below and joining the waitlist.







![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



