




![]()
AWS Data Pipeline is a web service that allows for consistent, reliable data processing and transportation between AWS computing, storage and on-premises data sources. AWS Data Pipeline allows you to easily transport processed data to AWS services such as Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR while retaining regular access to your data wherever it is stored.
In this blog, we will discuss Data Pipeline AWS:
Overview | Need for Data Pipeline AWS| Benefits | Components of AWS Data Pipeline | Pros and Cons | Alternatives of AWS Data Pipeline | Pricing | FAQ
Overview-
You can easily create fault-tolerant, repeatable, and highly available complex data processing workloads using AWS Data Pipelines. You don’t have to worry about resource availability, inter-task dependencies, retrying temporary failures or timeouts in individual tasks, or building a failure notification system.
A data pipeline is a mechanism that transfers raw data from multiple sources to a location where it may be stored and analyzed. It is made up of a series of interconnected data processing units, the outputs of which are inputs to one another.
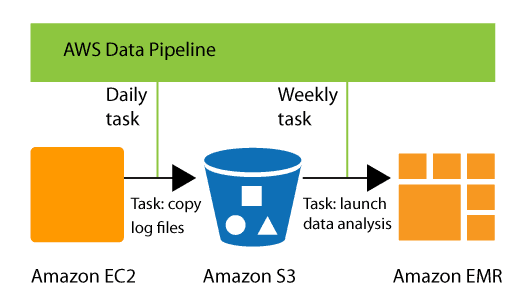
Need for AWS Data Pipeline
Data storage, management, migration, and processing are all becoming more difficult and time-consuming than they were. Due to the factors outlined below, handling the data is becoming more difficult:
- There is a large amount of created data that is unprocessed or in raw form.
- Different types of data—the data being produced is unstructured. Converting the data to appropriate formats is a time-consuming process.
- There are numerous data storage solutions. These include data warehouses and cloud storage solutions like Amazon S3 and Amazon Relational Database Service (RDS).
- There are numerous ways to store data. Businesses have their own data warehouse, EC2 instance-based database servers, and cloud-based storage like Amazon S3 and Amazon Relational Database Service (RDS).
- Managing the majority of data is time-consuming and expensive. It will be very expensive to change, store, and process data.

Benefits of AWS Data Pipeline
- Managing the majority of data is time-consuming and expensive. It will be very expensive to change, store, and process data.
- For the fault-tolerant operation of your operations, Data Pipeline AWS is built on a distributed, highly available architecture.
- The AWS pipeline is very scalable due to its flexibility. It makes processing a million files, in serial or parallel, as simple as processing one file.
- It provides a variety of features such as scheduling, dependency tracking, and error handling.
- It has cheap monthly fees and is inexpensive to use.
- Provides total control over the computing resources used to carry out your data pipeline logic.

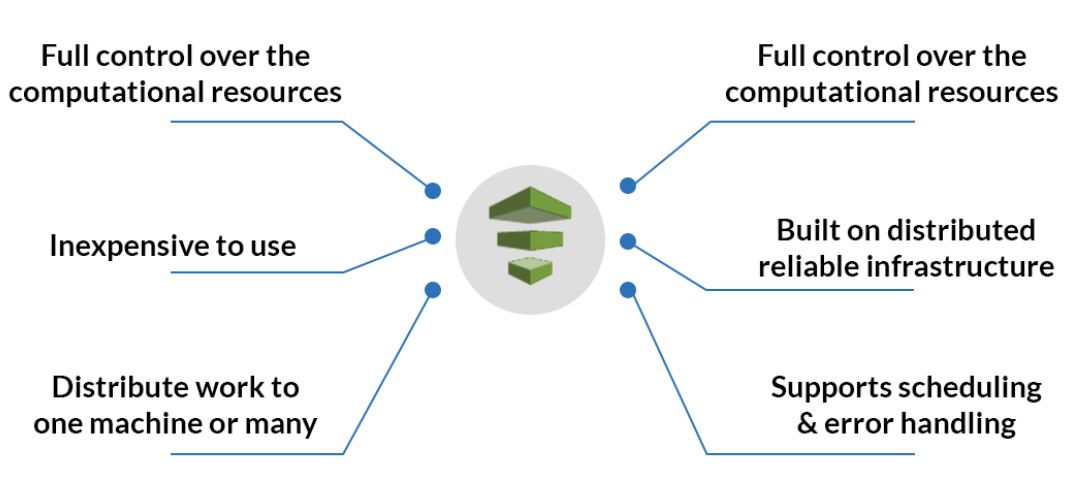
Components of Data Pipeline AWS
- Source: A location where a pipeline extracts information (from RDBMS, CRMs, ERPs, social media management tools, or IoT sensors).
- Destination: The moment at which the pipeline outputs all of the extracted data. A data lake or data warehouse are two possible destinations. Data can, for instance, be immediately loaded into data visualization tools.
- Data Flow: The word data flow refers to how data goes from one area to another while being modified. One of the most used data flow strategies is ETL, or extract, transform, and load.
- Workflow: Workflow entails the ordering of jobs and their interdependence in a pipeline. When it runs depends on dependencies and sequencing.
- Monitoring: Constant monitoring is essential for ensuring data accuracy, speed, data loss, and efficiency. These checks and monitoring become increasingly important as data size increases.
- Data nodes: A data node in AWS Pipeline specifies the location and type of data used as input or output by a pipeline activity. It supports the four data node types listed below:
-
- SqlDataNode: A SQL database and table query that serves as the data representation for a pipeline operation.
- DynamoDBDataNode: A table with data that EmrActivity or HiveActivity can use.
- RedshiftDataNode: A Redshift table containing information that RedshiftCopyActivity can use.
- S3DataNode: An Amazon S3 location with files for pipeline activities to use.
-
- Pipeline: It contains the below:
- Pipeline Components are the means by which data pipelines interact with AWS resources.
- When all components are compiled, an instance is produced to carry out a particular function.
- The data pipeline AWS has a feature called “attempts” that tries retrying an operation when it fails.
- Task runner: As its name implies, extracts tasks for execution from the data flow. When the task is finished, the status is updated. If the task is finished, the procedure finishes; if it fails, the task runner checks an attempt to retry the task and then repeats the process until all outstanding tasks have been completed.

Pros & Cons
Pros:
- Supports the majority of AWS databases with, an easy-to-use control interface with predefined templates.
- To only create resources and clusters when necessary.
- The ability to schedule jobs just during certain times.
- Protection for data both at rest and while in motion. AWS’s access control mechanism allows fine-grained control over who can use what.
- Users are relieved of all tasks relating to system stability and recovery thanks to fault-tolerant architecture.
Cons:
- It is built for AWS services, or the AWS world, and hence works well with all of the AWS parts. If you require data from many outside services, Pipeline Data aws is not the best choice.
- When managing numerous installations and configurations on the compute resources while working with data pipelines, might become daunting.
- To a beginner, the data pipeline’s way of representing preconditions and branching logic may appear complex, and to be honest, there are other tools available that help to accomplish complex chains more easily. A framework like Airflow is an example.
AWS Data Pipeline Alternatives
1) Hevo- To a beginner, the data pipeline’s way of representing preconditions and branching logic may appear complex, and to be honest, there are other tools available that help to accomplish complex chains more easily.

2) AWS Glue- AWS Glue is a fully managed, and Load (ETL) service that makes categorizing your data, cleaning, enriching, and moving it between reliably disparate data stores and data streams simple and cost-effective.
![]()
3) Apache Airflow- Apache Airflow is a workflow engine that simplifies the planning and execution of complex data pipelines. This ensures that each job in the data pipeline is executed in the correct order and receives the resources it requires.

4) Apache NiFi- Apache Nifi is open-source software that automates and manages data flow between source and destination. Creates, monitors, and manages data flow through a web interface.
![]()
Pricing of AWS Data Pipelines
- The pricing is based on the frequency with which activities and preconditions are configured in the console. In the case of actions that are executed up to once per day, AWS classifies the frequency of executions as low.
- High-frequency activities are those that are performed more than once per day. The low-frequency one on AWS costs $.6 per month, while the one on on-premise systems costs $1.5 per month. For on-premise systems, high-frequency activities start at $1 per month and go up to $2.5 per month.
- All resources used in pipeline activity, such as EC2 instances, EMR clusters, Redshift databases, and so on, are charged at standard rates, which are in addition to the pipeline pricing. The charges mentioned above are only for pipeline features.
Frequently Asked Questions:
How is Data Pipeline AWS different from Amazon Simple Workflow Service?
It is specifically created to facilitate the exact stages that are common across the bulk of data-driven workflows, even though both services include execution tracking, resolving retries and exceptions, and performing arbitrary actions. Examples include scheduling chained transforms, quickly copying data across multiple data stores, and starting actions only when their incoming data satisfies certain readiness criteria.
Does Data Pipeline supply any standard Activities?
Yes, Data Pipeline Aws provides built-in support for the following activities: CopyActivity: This activity can conduct a SQL query and copy the results into Amazon S3 or copy data between Amazon S3 and JDBC data sources. HiveActivity: With the help of this activity, running Hive queries are simple. EMRActivity: With this activity, you can execute any Amazon EMR operation. You may run any Linux shell command or program using the ShellCommandActivity.
Can you define multiple schedules for different activities in the same pipeline?
Yes, just create numerous schedule objects in your pipeline design file and use the schedule field to link the selected schedule to the appropriate activity. This enables you to create a pipeline where, for instance, hourly log data are saved in Amazon S3 and used to generate an aggregate report once every day.
How can I get started with Data Pipeline Aws?
To begin using Data Pipelines, go to the AWS Management Console and select the Data Pipeline tab. You can then use a simple graphical editor to create a pipeline.
How many pipelines can I create in Data Pipeline aws?
By default, your account can have 100 pipelines.
Is AWS data pipeline an ETL tool?
It is an ETL service that allows you to automate data movement and transformation. It starts an Amazon EMR cluster at each scheduled interval, submits jobs as steps to the cluster, and shuts down the cluster when tasks are completed.
Is AWS data pipeline serverless?
AWS Glue and AWS Step Functions provide serverless components to build, orchestrate, and run pipelines that can easily scale to process large data volumes.
What is AWS data pipeline vs. AWS glue?
With AWS Glue, you pay an hourly rate, billed by the second, for crawlers and ETL jobs. Data Pipeline Aws is billed based on how often your activities and preconditions are scheduled to run and where they run (AWS or on-premises). AWS Glue runs ETL jobs on its virtual resources in a serverless Apache Spark environment. Data Pipeline Aws isn't limited to Apache Spark. It enables you to use other engines like Hive or Pig. Thus, if your ETL jobs don't require the use of Apache Spark or multiple engines, AWS Data Pipelines might be preferable.
Related Links/References
- AWS Certified Solutions Architect Associate SAA-C03 Exam details
- AWS Free Tier: Create an Account
- AWS Free Tier Limits
- AWS Free Tier Account Details
- AWS Shield | DDoS Attacks | AWS Shield Pricing: Overview
- AWS Virtual Private Network (AWS VPN): Everything You need to Know
- AWS Free Tier Account Services
Next Task For You
Begin your journey towards an AWS Cloud by joining our FREE Informative Class on Amazon Cloud Free Class by clicking on the below image.







![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)



