




![]()
Generative AI adoption is accelerating rapidly, but so are infrastructure expenses. In 2026, many organizations using Amazon Bedrock are discovering that inefficient AI workloads can increase operational costs dramatically if not optimized correctly. Businesses implementing effective aws generative ai cost optimization strategies are already reporting nearly 45–65% savings by improving prompt efficiency, selecting the right models, and controlling inference usage.
As AI applications scale, factors such as oversized prompts, excessive realtime inference, poor workload routing, and lack of monitoring can significantly increase aws bedrock cost. Without proper optimization, even successful AI products can become difficult to scale profitably.
In this guide, you’ll learn practical techniques to reduce ai costs on AWS, including model tiering, prompt optimization, batching strategies, caching approaches, and governance best practices. These actionable strategies can help organizations improve AI efficiency while maintaining performance, scalability, and user experience in 2026.
Why GenAI Cost Optimization Matters in 2026?
As enterprises rapidly scale AI copilots, RAG applications, automation systems, and LLM-powered analytics platforms, generative ai costs are increasing significantly across cloud environments. Many organizations are now prioritizing ai cost optimization because inference-heavy AI workloads can become one of the largest contributors to overall cloud spending.

Unlike traditional cloud services, enterprise AI spending depends on multiple dynamic factors including:
- Input and output tokens
- Model selection
- Context window size
- Frequency of API requests
- Realtime inference workloads
- Multimodal processing requirements
Without a proper optimization strategy, AI infrastructure costs can grow unpredictably as adoption scales.
| Cost Factor | Impact on AI Spending |
|---|---|
| Large Context Windows | Higher token processing cost |
| Premium LLM Usage | Increased inference pricing |
| Frequent API Calls | Higher monthly consumption |
| Realtime AI Workloads | Increased GPU utilization |
| Poor Prompt Design | Unnecessary token waste |
Industry observations show that enterprises implementing structured ai cost optimization strategies can reduce operational AI expenses by nearly 45–65% through:
- Prompt optimization
- Model tiering
- Caching strategies
- Smaller model deployment
- Usage monitoring and governance
Enterprise AI Spending Comparison
| AI Deployment Approach | Cost Efficiency | Scalability |
|---|---|---|
| Unoptimized GenAI Workloads | Low | Expensive at scale |
| Optimized AWS Bedrock Usage | High | Better long-term scalability |
| Smaller Distilled Models | Very High | Lower inference cost |
Practical Optimization Tips
- Use smaller models for repetitive tasks
- Reduce unnecessary prompt length
- Implement caching for repeated workflows
- Monitor token usage continuously
- Route simple tasks to lower-cost models
Related Readings: AWS Cost Optimization: Maximize efficiency
Strategy 1: Model Tiering & Intelligent Routing
One of the most effective ways to reduce AWS Generative AI expenses is implementing model tiering and intelligent model routing. Many organizations using Amazon Bedrock unnecessarily send every request to premium models, even for simple tasks like summarization, tagging, or FAQ generation. This significantly increases inference costs at scale.
A smarter bedrock model selection strategy routes workloads based on complexity, response quality requirements, and latency needs.
| Model Tier | Common Bedrock Models | Best Use Cases | Relative Cost |
|---|---|---|---|
| Lightweight Models | Amazon Titan Lite, Claude Haiku | Tagging, summaries, classification | Low |
| Mid-Tier Models | Claude Sonnet, Titan Express | Business Q&A, copilots | Medium |
| Premium Models | Claude Opus | Deep reasoning, analytics | High |
How Intelligent Model Routing Works
With intelligent model routing, applications automatically select the most cost-efficient model for each request type.
Examples:
- Simple FAQ → Lightweight model
- Document summarization → Mid-tier model
- Financial analysis or complex reasoning → Premium model
This prevents overuse of expensive LLMs for low-complexity workloads.
Why Model Tiering Matters
Industry implementations show that structured model tiering can reduce inference costs by nearly 25–40% without significantly affecting user experience.
Major benefits include:
- Lower token processing cost
- Faster response times for simple tasks
- Better scalability for enterprise AI workloads
- Reduced Bedrock operational expenses
Practical Optimization Tips
- Route repetitive workflows to smaller models
- Reserve premium models only for high-value tasks
- Monitor token usage by workload type
- Continuously evaluate response quality vs cost
For large-scale AI deployments in 2026, intelligent bedrock model selection is becoming one of the most impactful strategies for balancing AI performance and operational efficiency.
Related Readings: Enable foundation models in AWS Bedrock: Step By Step Guide
Strategy 2: Token Discipline & Prompt Optimization
In Amazon Bedrock, every input and output token contributes directly to infrastructure cost. Poor prompt design, oversized context windows, and unnecessary response generation can dramatically increase enterprise AI spending. This is why prompt optimization and strong token optimization practices are critical for scalable Generative AI systems.
Even reducing 500–1,000 tokens per request can save organizations thousands of dollars monthly in high-volume production environments.
Common Token Cost Leaks
| Cost Issue | Impact |
|---|---|
| Repeating long system prompts | Higher input token usage |
| Sending full documents | Unnecessary context processing |
| Unlimited output generation | Increased output token cost |
| Full conversation replay | Excessive memory overhead |
Best Practices to Reduce Token Usage
- Set maximum output token limits
- Use sliding window memory for conversations
- Send only relevant document chunks
- Reuse static prompts where possible
- Prefer structured JSON responses over verbose text
Practical Prompt Optimization Example
| Poor Prompt | Optimized Prompt |
|---|---|
| “Analyze this entire 20-page report and summarize everything.” | “Summarize the key financial risks from section 4 only.” |
Why Token Optimization Matters
Strong token optimization improves:
- AI response speed
- Bedrock cost efficiency
- Scalability for enterprise workloads
- Latency for realtime AI systems
Organizations implementing disciplined prompt optimization strategies often achieve substantial cost reductions while maintaining similar response quality and user experience.
Strategy 3: Prompt Caching & Context Reuse
prompt cachingaws is one of the highest-impact cost optimization techniques for repetitive Generative AI workloads. Instead of repeatedly processing identical prompt prefixes, systems can reuse previously computed context through cached prompts, reducing both inference latency and Bedrock processing cost.
This approach is especially useful for enterprise AI systems where the same instructions, policies, or workflows are reused thousands of times daily.
Common Use Cases for Bedrock Prompt Caching
| Use Case | Why Caching Helps |
|---|---|
| Customer Support Bots | Reuses common system instructions |
| Policy Q&A Systems | Avoids repeated context processing |
| RAG Applications | Reuses knowledge base prompts |
| AI Assistants | Speeds up repetitive workflows |
Best Practices for Prompt Caching AWS
- Keep prompt prefixes consistent
- Use reusable prompt templates
- Separate static and dynamic content
- Minimize unnecessary context changes
Example of Cached Prompt Structure
| Static Prompt | Dynamic Variable |
|---|---|
| “You are an enterprise finance assistant.” | User-specific query |
This structure improves bedrock prompt caching efficiency because only the dynamic section changes between requests.
Why Prompt Caching Matters
Organizations implementing strong cached prompts strategies often achieve:
- 50–80% reduction in repetitive inference costs
- Faster AI response times
- Lower token processing overhead
- Better scalability for enterprise AI systems
Prompt caching is especially valuable for large-scale copilots, RAG assistants, and internal enterprise AI platforms where repeated workflows dominate overall AI usage.
Strategy 4: Moving Non-Critical Workloads to Batch Processing
One of the smartest ways to optimize Generative AI infrastructure is separating real-time AI tasks from non-critical ai workloads. Many organizations unnecessarily run all AI requests through expensive low-latency inference pipelines, even when immediate responses are not required.
Using batch processing ai strategies allows enterprises to process large workloads asynchronously at lower infrastructure cost.
| Realtime Workloads | Batch Workloads |
|---|---|
| AI Chatbots | Bulk content generation |
| Live Copilots | Sentiment analysis |
| Voice Assistants | Report generation |
| Interactive Search | Legal document processing |
Why Bedrock Batch Inference Matters
Bedrock batch inference is significantly more cost-efficient for workloads that do not require instant responses. Instead of processing requests individually in realtime, tasks are grouped and executed together, improving compute efficiency.
Organizations using batch-based AI workflows often reduce infrastructure expenses by nearly 20–35% for large-scale processing operations.
Best Use Cases for Batch Processing AI
- Marketing content generation
- Document summarization
- Large-scale data classification
- Enterprise reporting automation
- Historical analytics processing
Practical Optimization Tips
- Reserve realtime inference only for user-facing applications
- Move repetitive backend tasks to batch workflows
- Schedule non-urgent AI jobs during lower-demand periods
- Combine similar requests into grouped processing pipelines
For enterprises managing large AI workloads in 2026, balancing real-time systems with bedrock batch inference is becoming an important strategy for improving scalability while controlling operational costs.
Strategy 5: Governance & Monitoring
As enterprise AI adoption scales, strong ai cost monitoring and governance practices become essential for controlling long-term infrastructure expenses. Many organizations struggle with unpredictable AI spending because they lack visibility into token usage, model consumption, and workload-level costs.
An effective aws cost governance strategy helps teams track usage patterns, optimize resources, and prevent unnecessary AI expenditure.
| Governance Area | Purpose |
|---|---|
| AWS Cost Explorer | Monitor AI infrastructure spending |
| CloudWatch Metrics | Track model usage and latency |
| Budget Alerts | Prevent overspending |
| Cost Allocation Tags | Identify workload-level expenses |
Importance of Bedrock Cost Tagging
Using bedrock cost tagging allows organizations to track AI usage across:
- Departments
- Projects
- Environments (Dev/Test/Prod)
- AI features and applications
This provides better visibility into:
- Cost per API call
- Cost per feature
- Cost per user
- Average token consumption per request
Why AI Cost Monitoring Matters
Organizations implementing structured ai cost monitoring frameworks can:
- Detect abnormal AI spending early
- Optimize token usage more effectively
- Improve budgeting accuracy
- Align AI infrastructure with business goals
Practical Governance Best Practices
- Create monthly AI budget thresholds
- Monitor high-cost workloads continuously
- Use tagging for every Bedrock deployment
- Track token usage trends across teams
- Review model efficiency regularly
For enterprise AI platforms in 2026, governance is no longer only a finance concern — it has become a critical part of scalable and sustainable Generative AI architecture.
Real-World Example of AWS Generative AI Cost Optimization
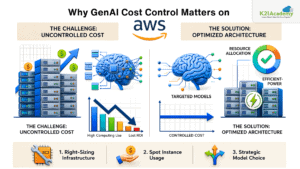
Here is an example of how cost optimization can impact your workload
Before optimization:
- Single premium model
- No caching
- Unlimited output tokens
- Real-time for all use cases
After implementing structured AWS Generative AI Cost Optimization:
- Model routing introduced
- Prompt caching enabled
- Sliding window memory applied
- Batch processing for analytics
- Strict token limits enforced
Result:
- 45–65% reduction in Bedrock expenses
- Improved latency
- Better cost predictability
Related Readings: Troubleshooting AWS Billing Issues: Beware Amazon Bedrock Users
Bedrock Pricing Table
Understanding amazon bedrock pricing is critical for organizations planning large-scale Generative AI deployments in 2026. Costs vary significantly depending on the model provider, token usage, latency requirements, and workload complexity. Choosing the wrong model for simple tasks can dramatically increase enterprise AI spending.
AWS AI Pricing Comparison
| Bedrock Model | Best Use Case | Relative Pricing | Cost Efficiency |
|---|---|---|---|
| Claude Haiku | FAQs, summaries, classification | Low | High |
| Claude Sonnet | Business copilots, Q&A | Medium | Balanced |
| Claude Opus | Advanced reasoning & analytics | High | Premium quality |
| Amazon Titan Lite | Lightweight enterprise AI tasks | Low | Very High |
| Amazon Titan Express | General AI workloads | Medium | Good scalability |
Bedrock Model Pricing Factors
| Cost Factor | Impact on Pricing |
|---|---|
| Input Tokens | Higher prompt size increases cost |
| Output Tokens | Longer AI responses cost more |
| Realtime Inference | Low-latency workloads cost more |
| Context Window Size | Large memory usage increases pricing |
| Model Complexity | Premium models have higher inference rates |
Amazon Bedrock Pricing vs Alternative Approaches
| AI Deployment Option | Cost Level | Scalability | Maintenance |
|---|---|---|---|
| Amazon Bedrock | Moderate to High | High | Managed by AWS |
| Self-Hosted Open Source Models | Lower inference cost | Complex scaling | High maintenance |
| Traditional GPU Infrastructure | Very High upfront cost | Flexible | Operational overhead |
Practical Optimization Tips
- Use lightweight models for repetitive workflows
- Apply prompt optimization to reduce token usage
- Implement caching for repeated prompts
- Reserve premium models only for complex reasoning tasks
- Monitor usage with AWS Cost Explorer and tagging
Organizations implementing structured aws ai pricing comparison strategies often reduce operational AI expenses significantly by combining model tiering, token discipline, and workload optimization techniques.
Case Study: 45–65% Savings with AWS Bedrock Optimization
A mid-sized enterprise deploying AI copilots and document intelligence solutions on Amazon Bedrock faced rapidly increasing inference costs as user adoption scaled. The organization processed thousands of daily AI requests across customer support, internal search, and automated reporting systems.
Initially, the company used premium models for nearly all workloads, resulting in high token consumption and inefficient infrastructure utilization. After implementing a structured gen-ai cost reduction case study strategy, the organization achieved substantial bedrock cost savings within a few months.
Optimization Changes Implemented
| Optimization Strategy | Impact |
|---|---|
| Model Tiering | Reduced premium model usage |
| Prompt Optimization | Lowered token consumption |
| Prompt Caching | Reduced repeated inference |
| Batch Processing | Shifted non-urgent workloads |
| Cost Governance | Improved usage visibility |
Results Achieved
| Metric | Before Optimization | After Optimization |
|---|---|---|
| Monthly AI Cost | High & unpredictable | 45–65% lower |
| Average Tokens per Request | Large prompts | Optimized prompts |
| Realtime Inference Usage | Excessive | Controlled routing |
| Response Efficiency | Moderate | Improved latency |
Key Bedrock Cost Savings Insights
The biggest savings came from:
- Routing simple tasks to lightweight models
- Reducing unnecessary prompt length
- Reusing cached prompts for repetitive workflows
- Moving backend jobs to asynchronous batch pipelines
The company also implemented:
- AWS Cost Explorer monitoring
- Bedrock cost tagging
- Budget alerts and workload-level reporting
Why This Case Study Matters
This genai cost reduction case study highlights an important trend in 2026: successful enterprise AI deployment is no longer only about model capability — it is equally about infrastructure efficiency and operational scalability.
Organizations adopting structured optimization strategies are increasingly able to:
- Scale AI applications sustainably
- Improve ROI on AI investments
- Control unpredictable inference costs
- Maintain performance while reducing infrastructure overhead
For enterprises using Amazon Bedrock at scale, proactive optimization has become a major competitive advantage.
Conclusion
This aws genai optimization summary highlights an important reality for 2026: successful Generative AI adoption is no longer only about model performance — it is equally about infrastructure efficiency, scalability, and governance.
Organizations using Amazon Bedrock can significantly reduce operational AI expenses by combining:
- Model tiering and intelligent routing
- Prompt optimization and token discipline
- Prompt caching and context reuse
- Batch inference for non-critical workloads
- AI cost governance and monitoring
Industry implementations show that enterprises applying structured optimization strategies often achieve nearly 45–65% reduction in Generative AI infrastructure costs while maintaining strong application performance and user experience.
| Optimization Strategy | Primary Benefit |
|---|---|
| Model Tiering | Lower inference cost |
| Token Optimization | Reduced token usage |
| Prompt Caching | Faster and cheaper repeated requests |
| Batch Processing | Lower non-realtime workload cost |
| Governance & Monitoring | Better AI spending control |
As enterprise AI adoption continues growing, cost optimization is becoming a core architectural requirement rather than a post-deployment activity. Businesses that proactively optimize AI infrastructure will scale faster, improve ROI, and build more sustainable AI platforms in the long term.
FAQ
{“What is aws generative ai cost optimization?”:”AWS generative ai cost optimization refers to strategies used to reduce infrastructure and inference expenses for AI applications running on AWS services like Amazon Bedrock. It includes techniques such as prompt optimization, model tiering, caching, batch processing, and workload monitoring to improve scalability while controlling operational AI costs.”,”Why is aws generative ai cost optimization important?”:”AWS generative ai cost optimization is important because Generative AI workloads can become expensive at scale due to token usage, premium model inference, and realtime processing requirements. Without optimization, enterprise AI spending can increase rapidly, making it difficult to scale AI applications sustainably and profitably.”,”How does aws generative ai cost optimization work?”:”AWS generative ai cost optimization works by reducing unnecessary token consumption, routing requests to appropriate models, reusing cached prompts, and shifting non-critical workloads to batch inference. These strategies help lower aws bedrock cost while improving AI efficiency, latency, and infrastructure utilization across enterprise AI systems.”,”What are the benefits of aws generative ai cost optimization?”:”The main benefits of aws generative ai cost optimization include reduced infrastructure expenses, improved AI scalability, lower token usage, and faster inference efficiency. Organizations can also improve governance, monitor AI workloads more effectively, and maintain better long-term ROI while continuing to expand Generative AI adoption.”,”Who should learn about aws generative ai cost optimization?”:”Cloud architects, AI engineers, DevOps teams, CTOs, finance teams, and enterprise technology leaders should learn about aws generative ai cost optimization. It is especially valuable for organizations using Amazon Bedrock, AI copilots, RAG systems, or high-volume Generative AI applications requiring scalable cost management.”,”What are the prerequisites for aws generative ai cost optimization?”:”To implement aws generative ai cost optimization, learners should understand basic cloud computing, AWS services, token-based AI pricing, and Generative AI workflows. Familiarity with Amazon Bedrock, prompt engineering, AI inference patterns, and workload monitoring tools can also help optimize AI infrastructure more effectively.”,”How to get started with aws generative ai cost optimization?”:”To get started with aws generative ai cost optimization, organizations should first analyze AI usage patterns and identify major cost drivers. Implementing prompt optimization, model tiering, prompt caching, and AI cost monitoring tools like AWS Cost Explorer are effective first steps to reduce AI costs sustainably.”,”What is the future of aws generative ai cost optimization?”:”The future of aws generative ai cost optimization will focus heavily on automated workload routing, smaller AI models, intelligent caching, and realtime cost governance. As enterprise AI adoption grows in 2026, organizations will increasingly prioritize scalable AI architectures that balance performance, latency, and operational efficiency.”}
Next Task For You
Don’t miss our EXCLUSIVE Free Training on Generative AI on AWS Cloud! This session is perfect for those pursuing the AWS Certified AI Practitioner certification. Explore AI, ML, DL, & Generative AI in this interactive session.
Click the image below to secure your spot!




![AWS DevOps [DOP-C02] Professional Step By Step Activity Guides (Hands-On Labs)](https://k21academy.com/wp-content/uploads/2023/02/DOP-C02-1.png)




