![]()
Big data architecture is constructed to handle the ingestion, processing, and analysis of data that is huge or complex for common database systems.
In this blog, we are going to cover everything about Big data, Big data architecture, lambda architecture, kappa architecture, and the Internet of Things (IoT).
What is Big Data?
- There are so many definitions of big data. The primary idea behind big data is that you want to analyze, but it’s really too big and unmanageable for you to do anything within its current format. You need to do some sort of processing with that data to get to a stage that’s useful for you to analyze.
- Mainly data depend on three V’s factors i.e. the volume, variety, and velocity. Any sort of combination of those three factors might make your data Big Data.
- There are a couple of examples of where we might want to use Big Data.
- Social media and sentiment analysis.
- Web server log reporting.
- Sensor Anomaly detection.
Check Out : Features of Azure Synapse
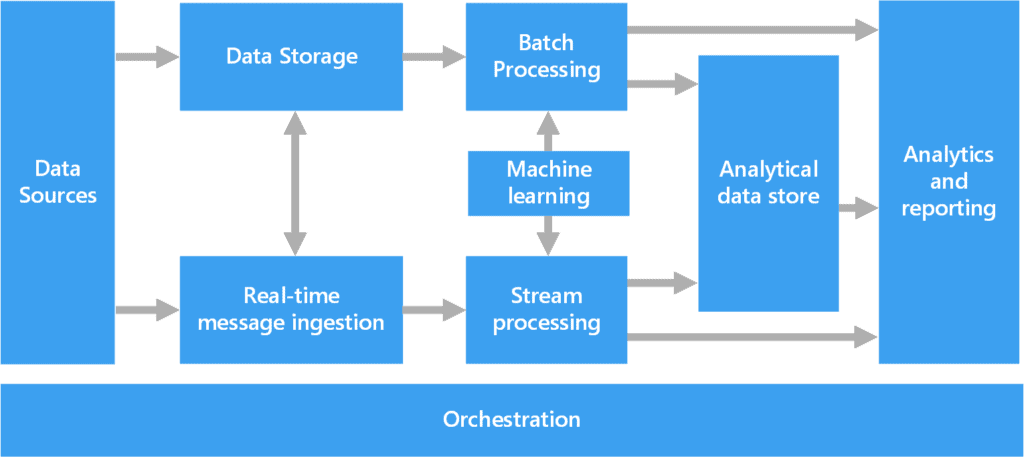
Big Data Architecture
Big data architecture is arranged to handle the ingestion, processing, and analysis of data that is huge or complicated for classical database systems.
1) Data sources
- Relational databases.
- Web server log files.
- IoT devices.
2) Data storage
- Azure Data Lake Store required for batch processing operations that can hold high volumes of large files in different formats.
3) Batch processing
- In Batch processing source data is loaded into data storage, either by an orchestration workflow or by the source application itself.
- Then data is processed in-place by a parallelized job, initiated by the orchestration workflow.
- These jobs involve reading source files, processing them, and writing the output to new files.
4) Real-time message ingestion
- If the solution ingests real-time data, the architecture must consist of a way to capture and store real-time data for stream processing.
- This part of a streaming architecture is generally referred to as stream buffering. Options include Azure IoT Hub, Azure Event Hubs, and Kafka.
Also Read : What is the difference between batch processing vs stream processing check here
5) Stream processing
- After grabbing real-time data, the solution must process them by aggregating, filtering, and otherwise preparing the data for useful analysis. The processed data is then written to an output sink.
6) Analytical datastore
- In this part the processed data in a structured format that can be queried using analytical tools.
- It is used to serve these queries can be a Kimball-style relational data warehouse. HDInsight provides the supports of Interactive HBase, Hive, and Spark SQL, which can also be used to serve data for analysis.
7) Analysis and reporting
- To analyze the data, the architecture contains a data modelling layer such as a tabular data model in Azure Analysis Services.
- It supports self-service BI, Microsoft Power BI, or Microsoft Excel for data visualization.
8) Orchestration
- To automate repeated data processing operations, we use an orchestration technology such as Apache Oozie or Azure Data Factory and Sqoop.
Also read: Azure SQL Database is evergreen, meaning it does not need to be patched or upgraded, and it has a solid track record of innovation and reliability for mission-critical workloads.
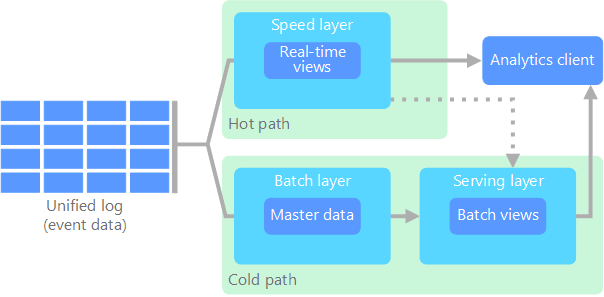
Lambda Architecture
- To run the sort of queries on large data sets takes a long time. These queries require algorithms such as MapReduce that operate in parallel across the entire data set in real-time.
- The lambda architecture creating two paths for data flow. i.e. Cold path and Hot Path.
- Batch layer (cold path): This layer stores all of the incoming data in its raw form and performs batch processing on the data.
- Speed layer (hot path): This layer analyzes data in real-time & designed for low latency, at the expense of accuracy.
- Data that goes into the hot path is restricted by latency requirements imposed by the speed layer to processed as quickly as possible.
- Data that goes into the cold path is not subject to the low latency requirements. This layer allows for high accuracy computation.
- If your needs to display timely, but less accurate data in real-time, it will achieve its result from the hot path. Otherwise, the cold path to display less timely but more accurate data.
Read this: Azure Event Hubs streamline your data pipelines for you.
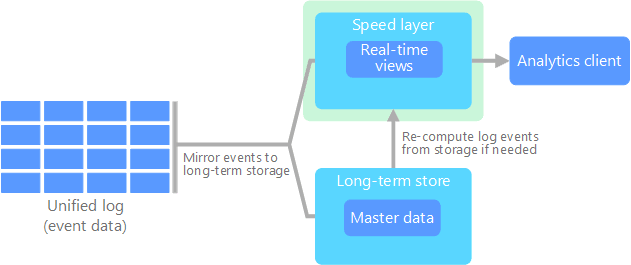
Kappa Architecture
- Lambda architecture is complex due to process logic in two different places. i.e. the cold and hot paths.
- The kappa architecture is an alternative to the lambda architecture.
- In kappa architecture all data flows through a single path only, using a stream processing system.
- If we need to recompute the entire data set, we simply replay the stream.
Also read: Azure Stream Analytics is the perfect solution when you require a fully managed service with no infrastructure setup hassle.
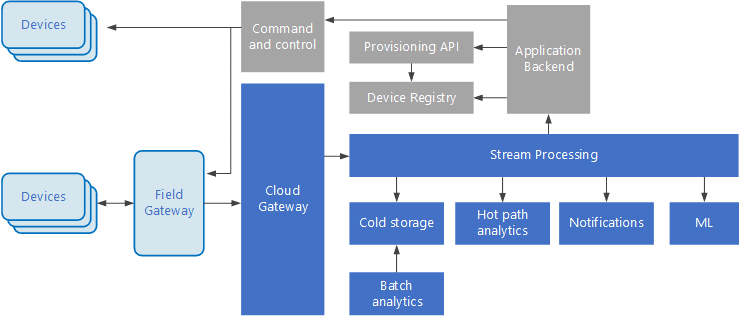
Internet of Things (IoT) Architecture
- Any device that is connected to the Internet is represented as the Internet of Things (IoT). Like your mobile phone, smart thermostat, PC, heart monitoring implants, etc.
- The amount of data generated every day from these devices is huge, to handle this data proper planning is required.
- Event-driven architectures are central to IoT solutions.
- Using a reliable and low latency messaging system the cloud gateway ingests device events at the cloud boundary.
- Events might be sent directly to the cloud gateway by the devices or through a field gateway.
- The field gateway is able to preprocess the raw device events, aggregation, filtering, or protocol transformation.
- After ingestion stream processors route the data to storage or other processing.
- Some common types of processing are.
- Hot path analytics, to detect anomalies or trigger alerts.
- Writing event data to cold storage, for batch analytics or archiving
- Machine learning.
- The device registry including the device IDs and usually device metadata. It is a database of the provisioned devices.
- The provisioning API is an external interface for registering and provisioning new devices.
Check out: Azure Data Lake is a unique solution to start with big data in the cloud.
Related/References
- Microsoft Azure Data Engineer Associate [DP-200 & DP-201]: Everything You Need To Know
- Implementing an Azure Data Solution | DP-200 | Step By Step Activity Guides [Hands-On Labs]
- Designing an Azure Data Solution | DP-201 | Step By Step Activity Guides [Hands-On Labs]
- Microsoft Azure Data Fundamentals [DP-900]: All You Need To Know
- Microsoft Azure Data Fundamentals [DP-900]: Step By Step Activity Guides (Hands-On Labs)
- 5 Pillars Of Azure Well-Architected Framework
- Azure Databricks For Beginners
- Azure Synapse Analytics (Azure SQL Data Warehouse)
- Microsoft Azure Data Engineer [DP-200 & DP-201] Hands-On Labs
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.


Leave a Reply