![]()
Databricks Machine Learning is an integrated end-to-end machine learning environment incorporating managed services for experiment tracking, model training, feature development and management, and feature and model serving. The diagram shows how the capabilities of Databricks map to the steps of the model development and deployment process.
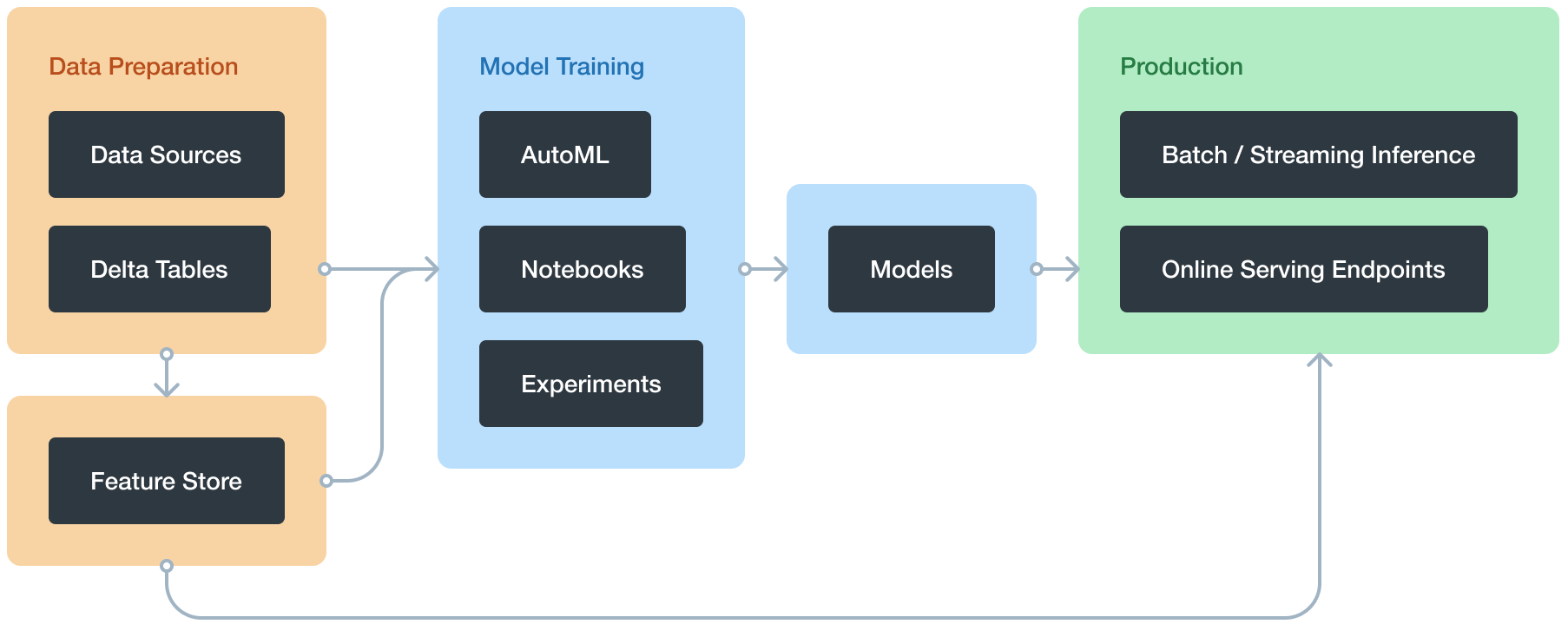
Databricks Machine Learning overview
With Databricks Machine Learning, you can:
- Train models either manually or with AutoML
- Track training parameters and models using experiments with MLflow tracking
- Create feature tables and access them for model training and inference
- Share, manage, and serve models using Model Registry
You also have access to all of the capabilities of the Databricks workspace, such as notebooks, clusters, jobs, data, Delta tables, security and admin controls, and so on.
Train Model Manually
This section covers how to train machine learning and deep learning models on Databricks, and includes examples using many popular libraries. You can also use Databricks AutoML, which automatically prepares a dataset for model training, performs a set of trials using open-source libraries such as scikit-learn and XGBoost, and creates a Python notebook with the source code for each trial run so you can review, reproduce, and modify the code.
- Machine learning
- scikit-learn
- MLlib
- XGBoost
- Deep learning
- Best practices for deep learning on Databricks
- Get started with TensorFlow Keras in Databricks
- TensorFlow
- PyTorch
- Distributed training
- Deep Learning Pipelines
- Hyperparameter tuning
- Hyperparameter tuning with Hyperopt
- Automated MLflow tracking
Databricks AutoML
Databricks AutoML helps you automatically apply machine learning to a dataset. It prepares the dataset for model training and then performs and records a set of trials, creating, tuning, and evaluating multiple models. It displays the results and provides a Python notebook with the source code for each trial run so you can review, reproduce, and modify the code. AutoML also calculates summary statistics on your dataset and saves this information in a notebook that you can review later.
AutoML automatically distributes hyperparameter tuning trials across the worker nodes of a cluster.
Requirements
- Databricks Runtime 8.3 ML or above. For the general availability (GA) version, Databricks Runtime 10.4 LTS ML or above.
- For time series forecasting, Databricks Runtime 10.0 ML or above.
- No additional libraries other than those provided with the Databricks Runtime ML runtime can be installed on the cluster.
- On a high concurrency cluster, AutoML is not compatible with table access control or credential passthrough.
- To use Unity Catalog with AutoML, the cluster security mode must be Single User, and you must be the designated single user of the cluster.
AutoML algorithms
Databricks AutoML creates and evaluates models based on these algorithms:
- Classification models
- scikit-learn models
- Decision trees
- Random forests
- Logistic regression
- XGBoost
- LightGBM
- scikit-learn models
- Regression models
- Forecasting
- Prophet
- Auto-ARIMA (Available in Databricks Runtime 10.3 ML and above.)
Track machine learning training runs
The MLflow tracking component lets you log source properties, parameters, metrics, tags, and artifacts related to training a machine learning model
MLflow tracking is based on two concepts, experiments and runs:
- An MLflow experiment is the primary unit of organization and access control for MLflow runs; all MLflow runs belong to an experiment. Experiments let you visualize, search for, and compare runs, as well as download run artifacts and metadata for analysis in other tools.
- An MLflow run corresponds to a single execution of model code. Each run records the following information:
- Source: Name of the notebook that launched the run or the project name and entry point for the run.
- Version: Notebook revision if run from a notebook or Git commit hash if run from an MLflow Project.
- Start & end time: Start and end time of the run.
- Parameters: Model parameters saved as key-value pairs. Both keys and values are strings.
- Metrics: Model evaluation metrics saved as key-value pairs. The value is numeric. Each metric can be updated throughout the course of the run (for example, to track how your model’s loss function is converging), and MLflow records and lets you visualize the metric’s history.
- Tags: Run metadata saved as key-value pairs. You can update tags during and after a run completes. Both keys and values are strings.
- Artifacts: Output files in any format. For example, you can record images, models (for example, a pickled scikit-learn model), and data files (for example, a Parquet file) as an artifact.
The MLflow Tracking API logs parameters, metrics, tags, and artifacts from a model run. The Tracking API communicates with an MLflow tracking server. When you use Databricks, a Databricks-hosted tracking server logs the data. The hosted MLflow tracking server has Python, Java, and R APIs.
Databricks Feature Store
Databricks Feature Store is a centralized repository of features. It enables feature sharing and discovery across your organization and also ensures that the same feature computation code is used for model training and inference.
The Databricks Feature Store library is available only on Databricks Runtime for Machine Learning and is accessible through notebooks and jobs.
Requirements
Databricks Runtime 8.3 ML or above.
MLflow Model Registry on Databricks
MLflow Model Registry is a centralized model repository and a UI and set of APIs that enable you to manage the full lifecycle of MLflow Models. Model Registry provides:
- Chronological model lineage (which MLflow experiment and run produced the model at a given time).
- Model serving.
- Model versioning.
- Stage transitions (for example, from staging to production or archived).
- Webhooks so you can automatically trigger actions based on registry events.
- Email notifications of model events.
You can also create and view model descriptions and leave comments.
You can work with the model registry using either the Model Registry UI or the Model Registry API.
Model Registry concepts
- Model: An MLflow Model logged from an experiment or run that is logged with one of the model flavor’s
mlflow.<model-flavor>.log_modelmethods. Once logged, you can register the model with the Model Registry. - Registered model: An MLflow Model that has been registered with the Model Registry. The registered model has a unique name, versions, model lineage, and other metadata.
- Model version: A version of a registered model. When a new model is added to the Model Registry, it is added as Version 1. Each model registered to the same model name increments the version number.
- Model stage: A model version can be assigned one or more stages. MLflow provides predefined stages for the common use-cases None, Staging, Production, and Archived. With the appropriate permission, you can transition a model version between stages or you can request a model stage transition.
- Description: You can annotate a model’s intent, including description and any relevant information useful for the team such as algorithm description, dataset employed, or methodology.
- Activities: Each registered model’s activities—such as a request for stage transition—is recorded. The trace of activities provides lineage and auditability of the model’s evolution, from experimentation to staged versions to production.
Also Read: Download Our blog post on DP 100 Exam questions and Answers. Click here
Related/References:
- [DP-100] Microsoft Certified Azure Data Scientist Associate: Everything you must know
- [AI-900] Microsoft Certified Azure AI Fundamentals Course: Everything you must know
- Microsoft Certified Azure Data Scientist Associate | DP 100 | Step By Step Activity Guides (Hands-On Labs)
- Azure Machine Learning Studio
- Datastores And Datasets In Azure
- Prepare Data for Machine Learning with Azure Databricks
- Microsoft Azure Data Scientist DP-100 FAQ
Next Task For You
Begin your journey toward Mastering Azure Cloud and landing high-paying jobs. Just click on the register now button on the below image to register for a Free Class on Mastering Azure Cloud: How to Build In-Demand Skills and Land High-Paying Jobs. This class will help you understand better, so you can choose the right career path and get a higher paying job.


Leave a Reply