![]()
In this blog, we are going to cover Structured Streaming with Azure Databricks, Streaming concepts, Event Hubs, and Spark Structured Streaming and Perform stream processing using structured streaming.
Topics we’ll Cover:
- Azure Databricks Structured Streaming
- Streaming Concepts
- Event Hubs and Spark Structured Streaming
- Perform stream processing using structured streaming.
To break down the continuous flow of incoming data and stream it to Azure Data Lake storage. For example the details of aircraft, the justification behind postponements, and takeoff time. So here we are utilizing Azure Event Hubs to process the data. To achieve this we are using the concept of streaming data with azure data bricks.
Azure Databricks Structured Streaming
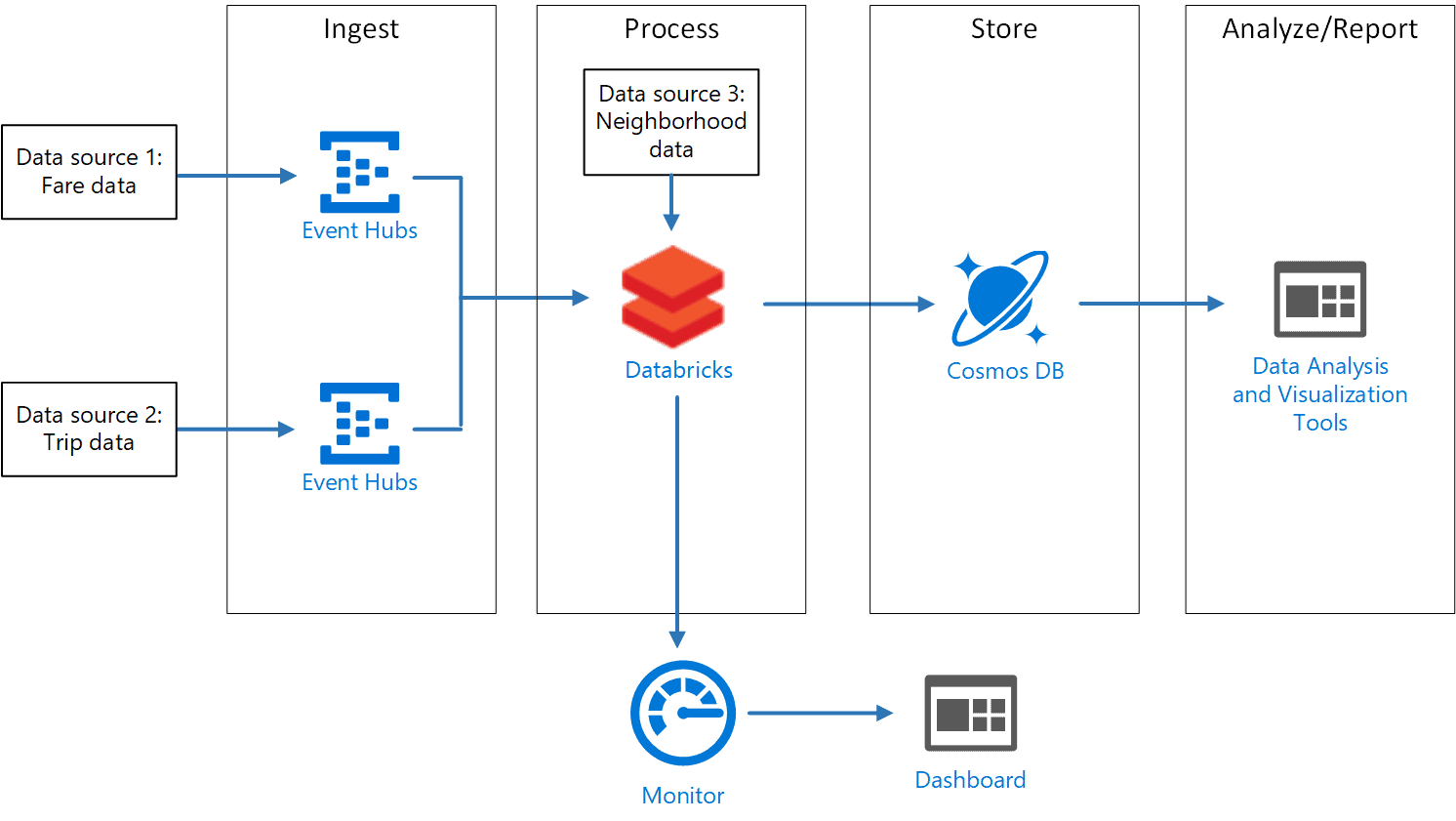
Apache Spark Structured Streaming is a quick, versatile, and fault-tolerant stream handling API. You can utilize it to perform analytics on your streaming information in real-time.
With Structured Streaming, you can utilize SQL queries to handle streaming information similar to how you would deal with static data. The API consistently augments and updates the final data.
Streaming Concepts
Stream handling is the place where you persistently fuse new data into Data Lake storage and process the results. The streaming data comes in quicker than it tends to be consumed while utilizing conventional traditional batch-related processing techniques. A stream of data is treated as a table to which data is continuously appended. Instances of such data incorporate bank card transactions, Internet of Things (IoT) gadgets data, and computer gameplay events.
A streaming system consists of the following:
- Stream processing using Structured Streaming, forEach sink, memory sinks, etc.
- Input sources such as Azure Event Hubs, Kafka, IoT Hub, files on a distributed system, or TCP-IP sockets.
Event Hubs and Spark Structured Streaming
Azure Event Hubs is a hyper-scale telemetry ingestion service that collects, transforms, and stores millions of events. As a distributed streaming platform, it gives you low latency and configurable time retention, which enables you to ingress massive amounts of telemetry into the cloud and read the data from multiple applications using publish-subscribe semantics.
Azure Event Hubs can be integrated with Spark Structured Streaming to perform the processing of messages in near real-time. You can query and analyze the processed data as it comes by using a Structured Streaming query and Spark SQL.
You can check out our related blog here: What is Azure Event Hubs & How It Works?
Perform Stream Processing Using Structured Streaming.
To Perform Perform stream processing using structured streaming you need to have access to an Azure Databricks workspace. And you also need an Azure Event Hubs instance in your Azure subscription.
Create an Event Hubs namespace
1) In the Azure portal, click on Create a resource. Enter event hubs into the Search the Marketplace box, select Event Hubs from the results, and then tap on Create.
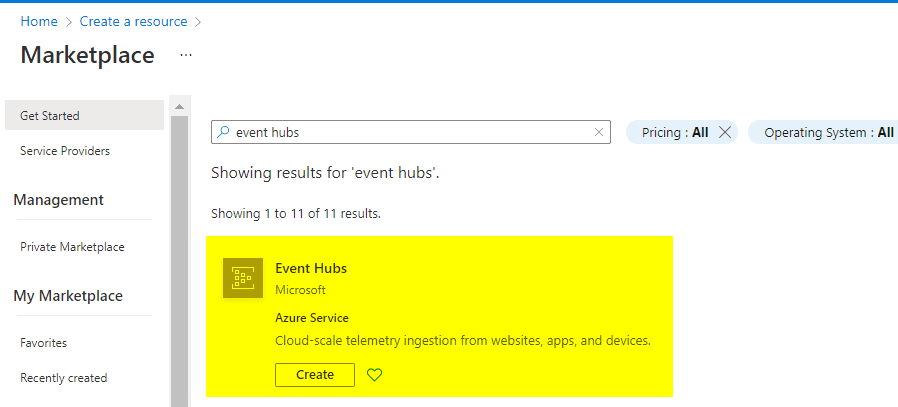
2) In the Create Namespace pane, enter the required information:
- Name: Enter a unique name, such as k21academy32111. (Uniqueness will be indicated by a green checkmark.)
- Pricing tier: Select Basic.
- Subscription: Select the active subscription
- Resource group: Choose your resource group. If you do not have any then create one.
- Location: Select the location in which region you want to deploy. And click Create.
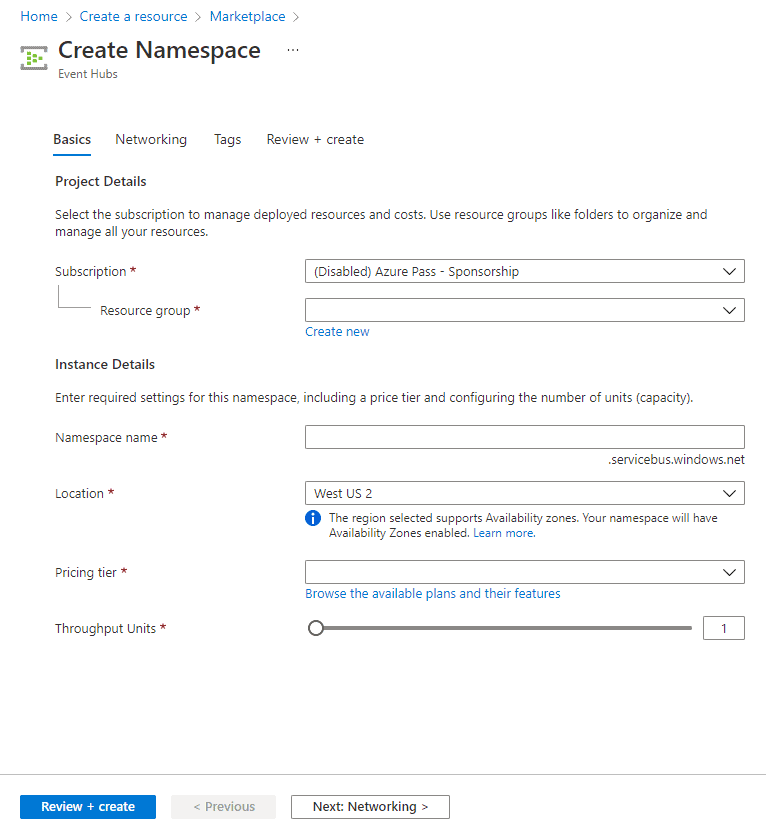
Create an Event Hub
1) After your Event Hubs namespace is provisioned, browse to it and add a new event hub by selecting the + Event Hub button on the toolbar.
2) On the Create Event Hub pane, enter:
- Name: Enter k21academy23121
- Partition Count: Enter 2. And click Create
Copy the connection string primary key for the shared access policy
1) On the left-hand menu in your Event Hubs namespace, select Shared access policies under Settings, then select the RootManageSharedAccessKey policy.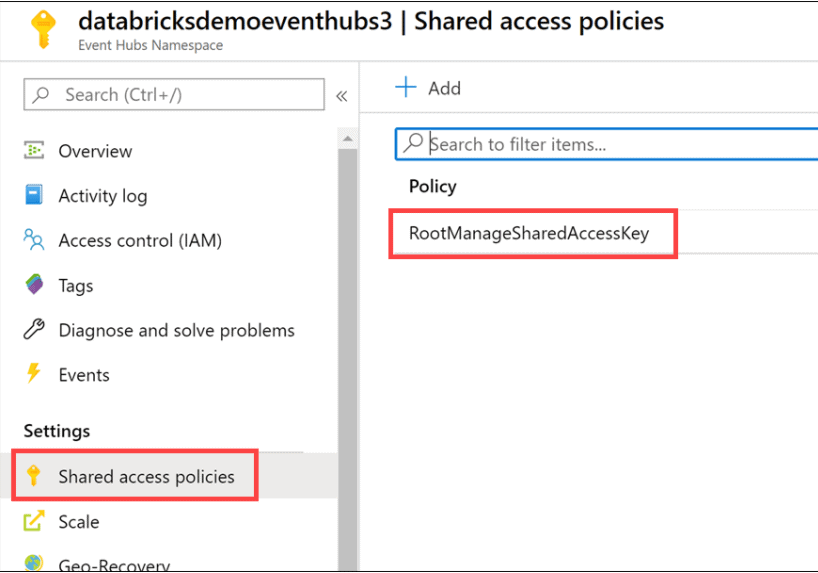
2) Copy the connection string for the primary key by selecting the copy button.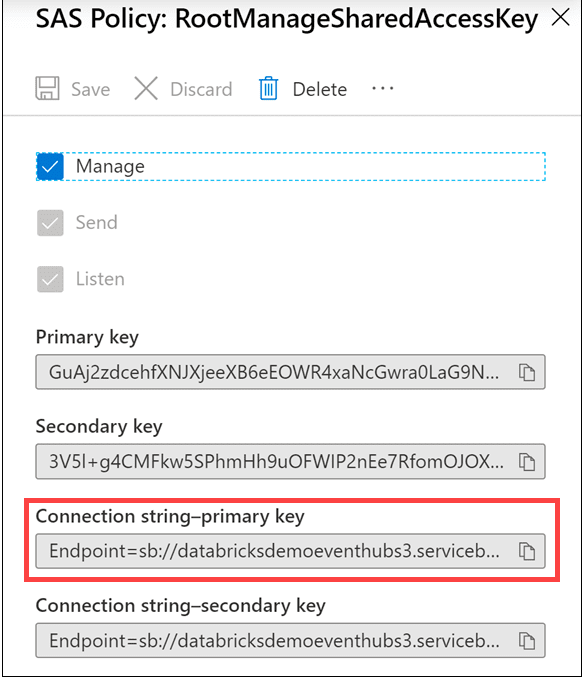
3) Save the copied primary key to Notepad.exe or another text editor for later reference.
Create a cluster
1) When your Azure Databricks workspace creation is complete, select the link to go to the resource.
2) Select Launch Workspace to open your Databricks workspace in a new tab.
3) In the left-hand menu of your Databricks workspace, select Clusters.
4) Select Create Cluster to add a new cluster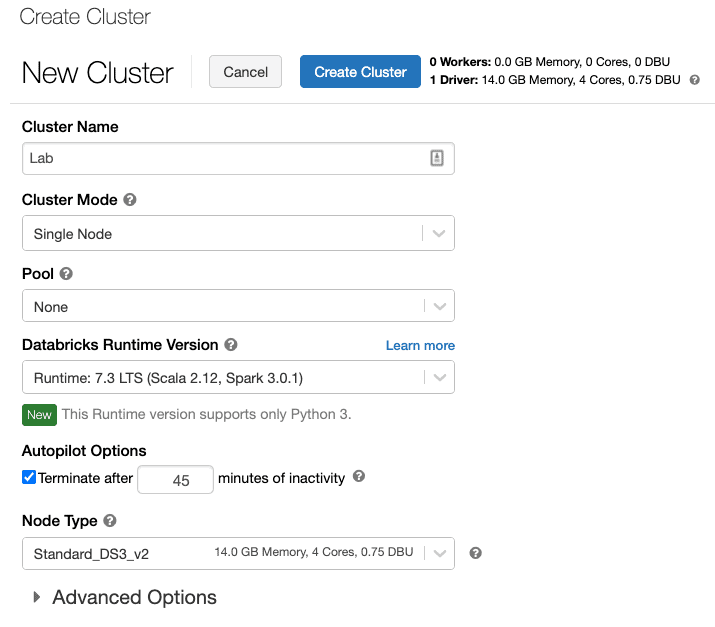
5) Enter a name for your cluster. Use your name or initials to easily differentiate your cluster from your coworkers.
6) Select the Cluster Mode: Single Node.
7) Select the Databricks RuntimeVersion: Runtime: 7.3 LTS (Scala 2.12, Spark 3.0.1).
8) Under Autopilot Options, leave the box checked, and in the text box enter 45
9) Select the Node Type: Standard_DS3_v2.
10) Select Create Cluster.
Clone the Databricks archive
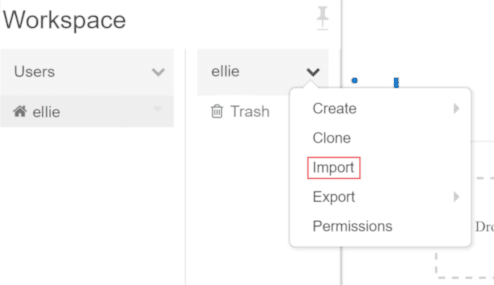
Clone the data bricks archive select Workspace > Users, select your username, and select Import and selecting the streaming folder.
https://github.com/MicrosoftDocs/mslearn_databricks/blob/main/streaming/1.1.0/Labs.dbc?raw=true
Complete The NoteBook
1) Structured-Streaming-Concepts notebook Make sure you attach your cluster to the notebook before following the instructions and running the cells within. Within the notebook, you will: Stream data from a file and write it out to a distributed file system, List active streams, Stop active streams.
2) Time-Windows notebook Make sure you attach your cluster to the notebook before following the instructions and running the cells within. Within the notebook, you will: Use sliding windows to aggregate over chunks of data rather than all data, Apply watermarking to throw away stale old data that you do not have space to keep, Plot live graphs using the display.
3) Streaming-With-Event-Hubs-Demo notebook Make sure you attach your cluster to the notebook before following the instructions and running the cells within. Within the notebook, you will: Connect to Event Hubs and write a stream to your event hub, Read a stream from your event hub, Define a schema for the JSON payload and parse the data to display it within a table.
Conclusion
Apache Spark Structured Streaming enables you to process streaming data and perform analytics in real-time. You can use Azure Event Hubs together with Structured Streaming to process and analyze messages in real-time.
Frequently Asked Questions
Q. When doing a write stream command, what does the output mode(“append”) option do?
The output mode “append” option informs the write stream to add only new records to the output sink. The “complete” option is to rewrite the full output – applicable to aggregations operations. Finally, the “update” option is for updating changed records in place.
Q. In Spark Structured Streaming, what method should be used to read streaming data into a DataFrame?
Use the spark.readStream method to start reading data from a streaming query into a DataFrame.
Q. What happens if the command option(“checkpointLocation”, pointer-to-checkpoint directory) is not specified?
Setting the checkpointLocation is required for many sinks used in Structured Streaming. For those sinks where this setting is optional, keep in mind that when you do not set this value, you risk losing your place in the stream.
Related/References
- Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Exam DP-203: Data Engineering on Microsoft Azure
- Microsoft Azure Data Engineer Associate [DP-203] Interview Questions
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.


Leave a Reply