![]()
Azure Synapse SQL offers both serverless and dedicated resource models, offering consumption and billing options to fit your needs. Every Azure Synapse Analytics workspace comes with a built-in serverless SQL pool that you can use to query data in the lake.
This blog post will go through some quick tips including Q/A and related blog posts on the topics that we covered in the Azure Data Engineer Day 4 Live Session which will help you gain a better understanding and make it easier for you to
The previous week, In Day 3 session we got an overview of concepts of Data Exploration and Transformation in Azure Databricks where we have covered topics like Azure Databricks, Read and write data in Azure Databricks, DataFrames in Azure Databricks.
We also covered hands-on, Explore, Transform, And Load Data Into The Data Warehouse Using Apache Spark out of our 27 extensive labs.
So, here are some FAQs asked during the Day 4 Live session from Module 4 Of DP203.
>Understand big data engineering with Apache Spark in Azure Synapse Analytics
Apache Spark is an equal handling structure that backings in-memory preparing to support the presentation of huge information examination applications. The Apache Spark core engine is an appropriated execution engine, of which its assets are overseen by the YARN (Yet Another Resource Negotiator) layer to guarantee legitimate utilization of the circulated engine to deal with the Spark inquiries and jobs. You can have various functionalities sit on top of the Apache Spark core engine that you add as your examination requires. Models incorporate adding Apache Spark SQL to perform intelligent inquiries for exploratory information examination, Spark MLib for AI, and GraphX for diagram calculations. The functionalities empower you to set up assorted jobs on a solitary stage.
Apache Spark in Azure Synapse Analytics is one of Microsoft’s executions of Apache Spark in the cloud. Azure Synapse Analytics makes it simple to make and design a serverless Apache Spark pool in Azure. Spark pools in Azure Synapse Analytics are viable with Azure Storage and Azure Data Lake Generation 2 Storage. Consequently, you can utilize Spark pools to handle your information put away in Azure.
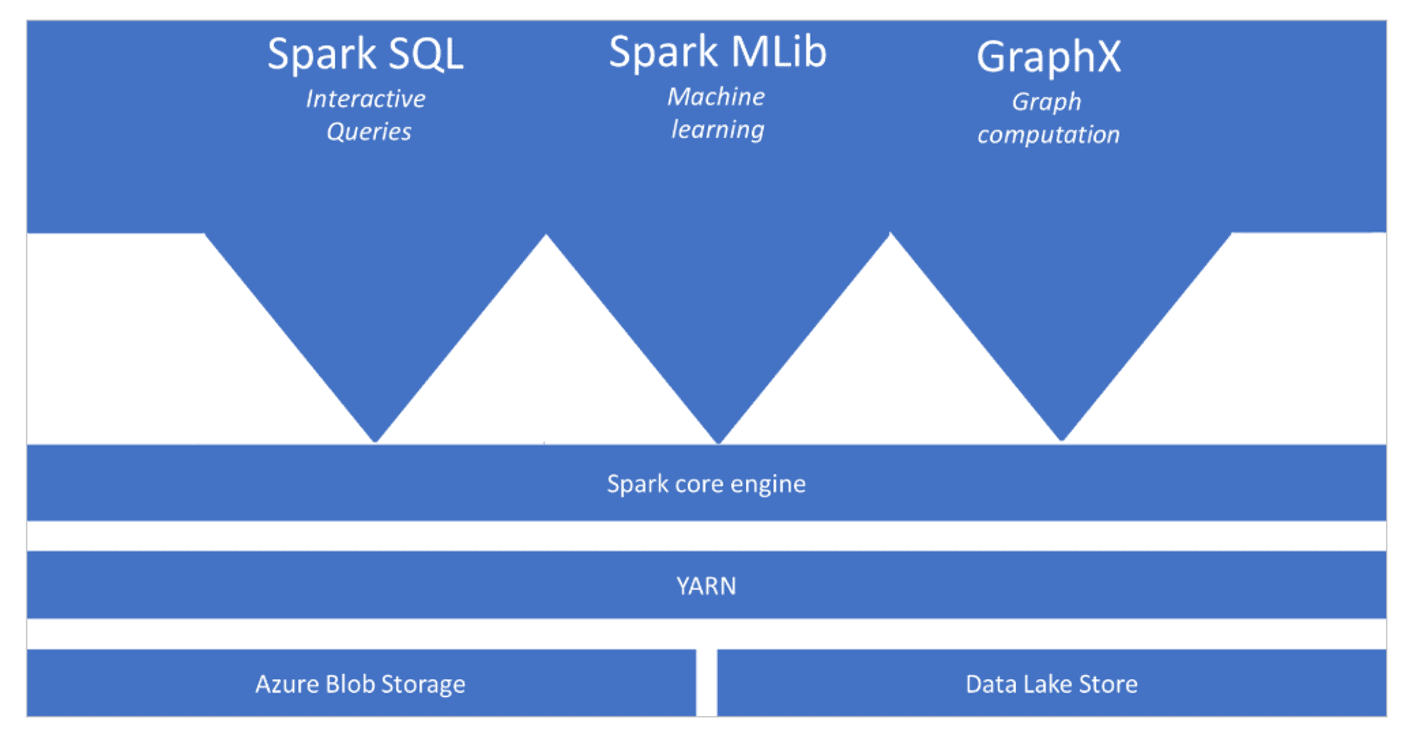 Source: Microsoft
Source: Microsoft
Ques 1: Do I need to know Apache Spark to be able to take the DP 203 exams?
Ans: Yes, from an exam point of view you require a general overview of Apache Spark. Even if you are new to it, you need not worry as we cover this in our training program whenever it is required so you can learn then also. Also, check the previous well done once for a better understanding. Also, you have 1 year of FREE unlimited retake for the live sessions.
Ques 2: What is a Spark pool?
Ans: A Spark pool is formed within the Azure portal. it’s the definition of a Spark pool that, once instantiated, creates a Spark instance that processes data. once a Spark pool is formed, it exists solely as metadata; no resources are consumed, running, or charged for. A Spark pool encompasses a series of properties that management the characteristics of a Spark instance; these characteristics embody however don’t seem to be restricted to name, size, scaling behavior, time to measure.
Ques 3: When to use Azure Synapse serverless SQL pools?
Ans: Synapse SQL serverless resource model is great if you need to know the exact cost for each query executed to monitor and attribute costs.
Check Out: Azure Data Factory Interview Questions and Answers.
> Apache Spark for Azure Synapse
Apache Spark is an open-source, memory-upgraded framework for overseeing enormous information responsibilities, which is utilized when you need a Spark engine for huge information preparation or data science, and you wouldn’t fret that there is no help level understanding gave to keep the administrations running. For the most part, it is of interest to open-source experts and the justification for Apache Spark is to defeat the limits of what was known as SMP frameworks for huge data responsibilities.
>How do Apache Spark pools work in Azure Synapse Analytics
Inside Azure Synapse Analytics, Apache Spark applications run as free arrangements of cycles on a pool, composed by the SparkContext object in your principle program (called the driver program). The SparkContext can associate with the bunch director, which designates assets across applications. The group administrator is Apache Hadoop YARN. Once associated, Spark gains agents on nodes in the pool, which are measures that run calculations and store information for your application. At last, SparkContext sends assignments to the executors to run.
The SparkContext runs the client’s fundamental capacity and executes the different equal procedures on the nodes. Then, at that point, SparkContext gathers the consequences of the tasks. The nodes peruse and compose information from and to the record framework. The nodes likewise store changed information in-memory as Resilient Distributed Datasets (RDDs).
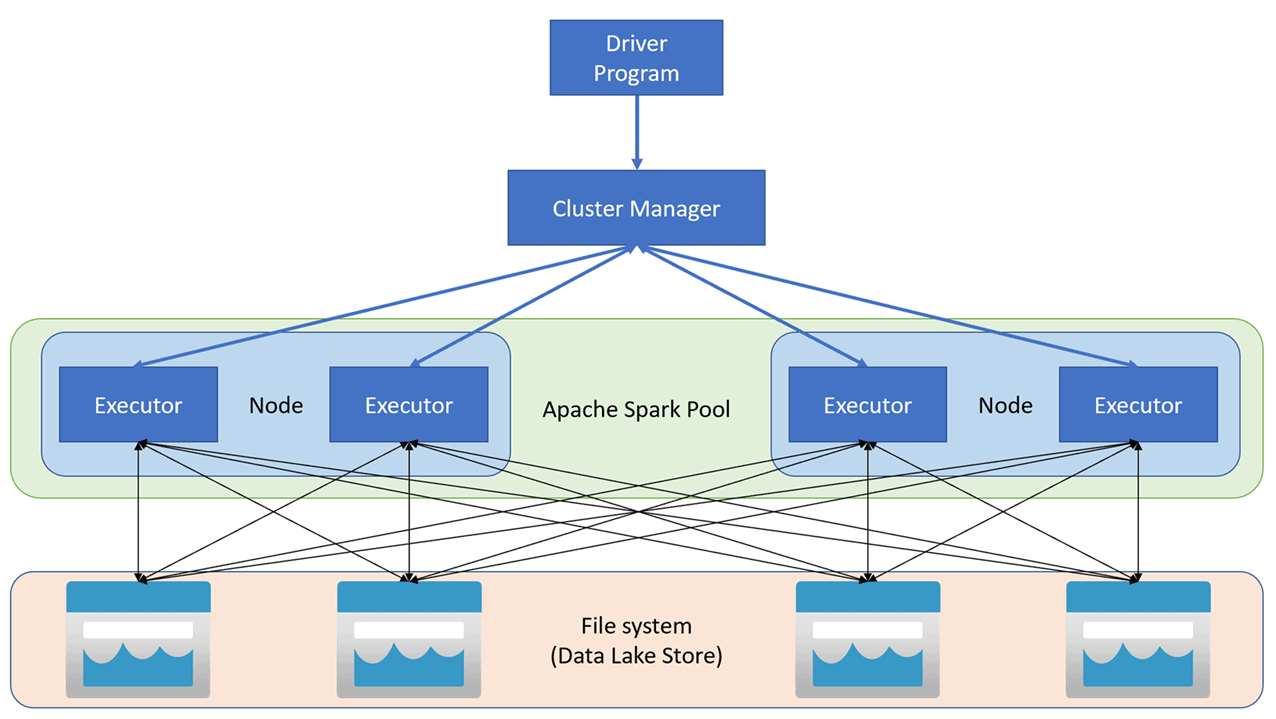 Source: Microsoft
Source: Microsoft
> Lab: Explore, Transform, And Load Data Into The Data Warehouse Using Apache Spark
In the lab, we take the opportunity to explore data stored in a data lake, transform the data, and load data into a relational data store. You can explore Parquet and JSON files and use techniques to question and remodel JSON files with class-conscious structures. Then you can use Apache Spark to load data into the data warehouse and be part of Parquet data within the data lake with data within the dedicated SQL pool.
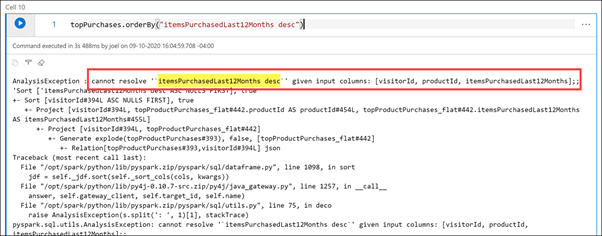
Ques 4: What does that hash accomplish? Does it create a Unique identifier for the customer dim?
Ans: Yes, it creates a unique identifier for the columns that were used to create that hash
Ques 5: Where was the hash for the OLAP Customer table created?
Ans: They were created in mapping data flow derived column activity (createCustomerHash) during runtime.
Ques 6: What happens if the hash keys are matched?
Ans: If hash keys match it shows the columns have the same values (so no change occurred) for a particular record in our source (OLTP) and sink (Datawarehouse/Synapse)
Ques 7: What is the difference between Upsert & Update?
Ans: The UPDATE option keeps track of the records being updated in the database table. The UPSERT option is the combination of ‘Update’ and ‘Insert’ which means that it will check for the records that are inserted or updated.
Ques 8: What is the ‘Inline dataset’ under ‘Source Type’?
Ans: Inline datasets are recommended when you use flexible schemas, one-off source instances, or parameterized sources. If your source is heavily parameterized, inline datasets allow you to not create a “dummy” object. Inline datasets are based on Spark, and their properties are native to the data flow.
Ques 9: Please explain Integration runtime?
Ans: An Integration Runtime (IR) is the compute infrastructure used by Azure Data Factory to provide data integration capabilities such as Data Flows and Data Movement. It has access to resources in either public networks or hybrid scenarios (public and private networks).
Integration Runtimes are specified in each Linked Service, under Connections.
There are 3 types to choose from
1. Azure Integration Runtime
2. Self-hosted Integration Runtimes
3. Azure-SSIS Integration Runtimes
Ques 10: How many Integrations run times do we need to create to connect more than one DB on the same server?
Ans: A single self-hosted integration runtime can be used for multiple on-premises data sources. A single self-hosted integration runtime can be shared with another data factory within the same Azure Active Directory tenant. if it’s on a public source your azure auto-resolve integration runtime will be able to connect to it.
Ques 11: What is a Shared access signature (SAS)?
Ans: With SAS, you can grant clients access to resources in a storage account, without sharing account keys.
Ques 12: What is ACL here?
Ans: You can associate a security principle with an access level for files and directories. These associations are captured in an access control list.
There are two kinds of access control lists:
• Access ACLs: Controls access to an object. Files and directories both have access to ACLs.
• Default ACLs: Are templates of ACLs associated with a directory that determine the access ACLs for any child items that are created under that directory. Files do not have default ACLs
Feedback Received…
Here is some positive feedback from our trainees who attended the session:
Quiz Time (Sample Exam Questions)!
Ques: Your company has an Azure Cosmos DB account that makes use of the SQL API. You have to ensure that all stale data is deleted from the database automatically.
Which of the following features would you use for this requirement?
A. Soft delete
B. Schema Read
C. Time to Live
D. CORS
Comment with your answer & we will tell you if you are correct or not!
References
- Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Azure Data Lake For Beginners: All you Need To Know
- Azure Databricks For Beginners
- Azure Data Engineer [DP-203] Q/A | Day 1 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 2 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 3 Live Session Review
- Azure Data Engineer,Data Science & Data Analyst Certifications: DP-900 vs DP-100 vs DP-203 vs DA-100A
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.


Leave a Reply