![]()
Oracle Data Sync is one of the important topics from [1Z0-931] Oracle Autonomous Database Cloud Specialist certification covered in our training.
In this blog, we will discuss an overview of Data Sync and its various concepts such as connections, jobs, projects, drivers and will also talk about the steps for data loading into and extracting from, the Autonomous Data Warehouse Database Cloud (ADWC).
Here is a sample question that has been asked in the [1Z0-931] Oracle Autonomous Database certification exam.
Q. Which two statements are true with regards to Oracle Data Sync? (Choose two.)
A. Data Sync can connect to any JDBC compatible source like MongoDB, RedShift, and Sybase.
B. Data Sync can use a normal OCI (thick) client connection to connect to an Oracle database.
C. Data Sync can load your data in parallel in order to speed up the loading process.
D. Data Sync has default drivers available that support loading data from DB2, Microsoft SQL Server, MySQL, and Teradata.
By the end of this blog, you will be able to answer this question and understand Oracle Data Sync.
- Oracle Data Sync
- Data Sync Supported Databases
- Download & Install Data Sync Tool
- Data Sync Advantages
- Overview of Oracle JDBC Drivers
- Concepts of Data Sync: Connections, Project, Jobs
- Data target & Data Sources
- Steps For Loading Data into ADW
If you want to know more about Autonomous Databases, read our previous blog on Oracle Cloud Database Deployment Options (VMDB, BMDB, ExaCC, ExaCS & Autonomous (ADW, ATP)
Oracle Data Sync Overview
Moving to the cloud in some ways makes things more complicated for analytics since the bulk of your data is still On-Premise or in different formats. Oracle Data Sync is a tool that provides the ability to extract from both on-premise, and cloud data sources and from the relational databases as well as flat files (CSV, Excel), and to load that data to an Oracle Cloud database (Database Cloud Service or Autonomous Databases) or to a data set in Oracle BI Cloud Service or salesforce.
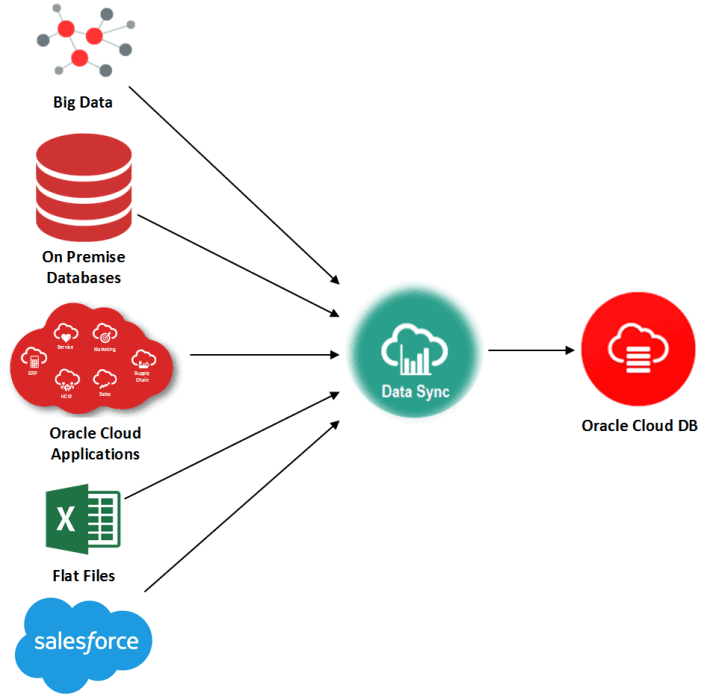
Data Sync Supported Databases
Data Sync utility allows designing jobs that support both full & incremental loads, besides other capabilities like scheduling, notification, and automation aspects. Data Sync is used to load data from these databases: Oracle, DB2, Microsoft SQL Server, MySQL, Teradata, and TimesTen.
Data Sync can also be used to load data from generic JDBC compatible sources, for example:
- Greenplum
- Hive
- Impala
- Informix
- MongoDB
- NetSuite
- PostgreSQL
- Redshift
- Salesforce
- Sybase
Download & Install Data Sync Tool
You need to first download the latest version of the Data Sync Tool available on OTN through this link and install it on your machine. The Autonomous Data Warehouse requires data sync 2.4 or later.
Data Sync requires JDK8 or higher. You can download that through this link. The latest version contains important security updates and bug patches, hence it is always recommended by Oracle.
Data Sync Advantages
Data Sync does have various advantages:
- It is simple to install, configure and helps run data mappings
- It is written in Java, can be run on any platform that has a JVM (Java Virtual Machine)
- It allows connecting to any database that has a JDBC driver
- There is built-in support for connection to most commonly used databases
Overview of Oracle JDBC Drivers
JDBC is used to connect the Data Sync tool to source databases. JDBC drivers used in the Data Sync tool can be of two types: Thin and Oracle Call Interface (OCI).
If the source database is different – then make sure the JDBC drivers are the correct versions for the source on-premise database, you need to first download the correct JDBC drivers for that version of the database, and then replace it, overwriting the existing version.
This table shows the driver files required for each database vendor that needs to be downloaded and copied.

Concepts for the Data Sync
The Data Sync tool has 3 main concepts/sections:
Connections
Data Sync allows you to define two types of connections: source and target connections. Data Sync has the Sources/Targets dialog in the Connections view to specify connection details for your target database and source databases.
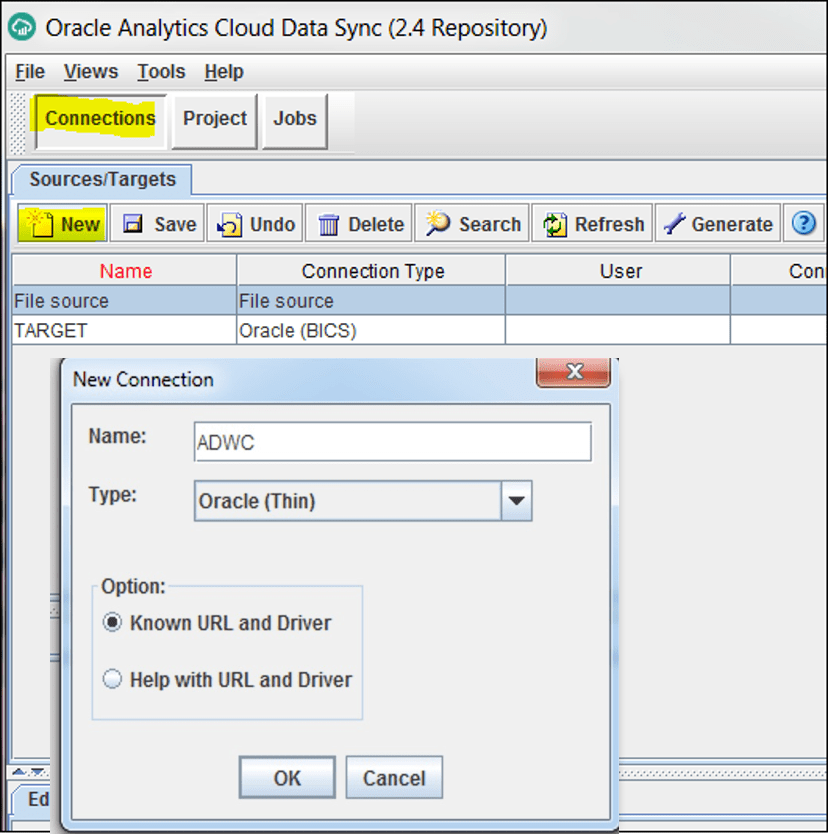
Project
A Project is a workspace where the source files and targets are defined, as well as their attribute and it is also where the load strategy for each table is also defined. There are multiple load strategies in Data Sync Tool that can be used.
Once the source and target connections have been set up, the next step is to define the actual tables, sql, or files to be used as the sources, and the table(s) that will be loaded.
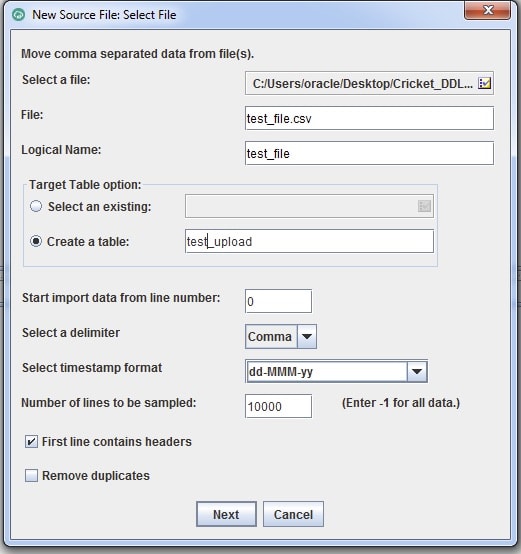
Jobs
A Job is a unit of work that can be used to upload the data from one or more sources defined in the project. A project can have one or more jobs. You can find and analyze the data load status from here.
Parallelism:
- Data Sync defaults to 10 maximum jobs for connections to Database Cloud Service (DBCS) or on-premises databases, but you can specify and run more than 10 tasks in parallel.
Data Target & Data Sources
Data Sync has the Sources/Targets dialog in the Connections view to specify connection details for your target database and source databases. Data is loaded from these sources to the target location using Data Sync.
- If you’re loading data to a target database, then edit the connection named TARGET and specify the details of your target Cloud database.
- If you’re loading data from a source database, then specify the connection details for your source database.
- If you’re loading data only from flat files, such as XLSX or CSV format, then you don’t need a connection in Data Sync.
Steps For Loading Data into ADW
Here are the steps required to set up a connection and load data into ADW database:
- Download The Latest Version of Data Sync Tool
- Download the Java Cryptography Extension
- Download the ADWC Credentials
- Setup ADWC Connection in Data Sync
- Create a New Job to Load into ADWC
The steps to extract data from ADWC are the same. Make sure you select the ADWC connection as the source when defining the source objects.
For the more detailed and step-by-step tutorial to set up the connection to ADWC, and create a simple mapping to load data into ADWC, read the A-Team article Data Sync and the Autonomous Data Warehouse Cloud (ADWC)
Conclusion
In this article, we discussed Oracle Data Sync and all the related concepts such as Connections, Projects, and Jobs. We also briefly covered JDBC drivers required to connect to source databases and provided the steps required to create connections in Oracle Data Sync to the Autonomous Data Warehouse Cloud.
It’s time to revisit the question with which we started this blog. I hope that by now you would agree with me that the correct answer to this question is A and C.
Q. Which two statements are true with regards to Oracle Data Sync? (Choose two.)
A. Data Sync can connect to any JDBC compatible source like MongoDB, RedShift, and Sybase.
B. Data Sync can use a normal OCI (thick) client connection to connect to an Oracle database.
C. Data Sync can load your data in parallel in order to speed up the loading process.
D. Data Sync has default drivers available that support loading data from DB2, Microsoft SQL Server, MySQL, and Teradata.
Correct Answer: A, C
Related/References
- Overview to Getting Your Data to the Cloud using Data Sync
- Configuring and Connecting the Data Sync Tool to different sources
- Oracle Cloud Data Sync Readme
- Connecting Oracle Data Sync to the Autonomous Data Warehouse Cloud
- NOSQL Cloud Database Service in Oracle Cloud
- MySQL Database as a Service in Oracle Cloud
- Introduction to Oracle Database 21c New Update Now Available On Oracle Cloud
Next Task For You
If you want to upgrade your career from an Oracle DBA to Oracle Cloud DBA, and wants to clear Oracle Cloud Database Service Specialist[1Z0-1093-21] & Oracle Cloud Autonomous Database Certification[1Z0-931-21] with 18 Hands-On labs, then register for a FREE class, and don’t miss an opportunity to gain a plethora of insights on becoming a certified Oracle Cloud DBA.


Leave a Reply