![]()
Data Analytics refers to the techniques used to analyze data to enhance productivity and business gain. Data is extracted from numerous sources and is cleansed and classified to investigate numerous behavioural patterns.
This blog will cover some quick tips including FAQs on the topics that we covered in the Day 5 & 6 live sessions which will help you to clear Certification [MLS-C01] & get a better-paid job.
The previous week, In Day 3 & 4 sessions we got an overview of Python basics and Statistics & Probability. And in this week Day 5 & 6, we covered the concepts of Data Engineering in AWS and Data Analysis in AWS. We also performed some Hands-on Kinesis Data Stream and Kinesis Data Firehose, Running Data Analytics using Kinesis, Athena with Glue Integration, and Overview of Amazon Quicksight out of our 30+ extensive labs.
So, here are some of the FAQ’s that help you keep you in pace with us from the Live session from Module 4: Data Engineering in AWS
> Data Engineering in AWS
Before a model is constructed, before the data is cleansed and prepared for exploration, even before the role of a data scientist begins – this is where data engineers come into the picture. each data-driven business must have a framework in situ for the data science pipeline, otherwise, it’s a setup for failure
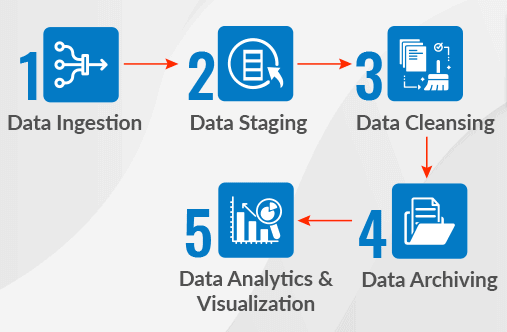
Basically, So the data Engineer is doing some designing and scaling a system that organizes data for analytics.
Q1: What is Amazon Kinesis Data Streams?
A: Amazon Kinesis Data Streams allows you to make custom applications that method or analyze streaming information for specialised wants. you’ll unendingly add numerous styles of data like clickstreams, application logs, and social media to an Amazon Kinesis data stream from many thousands of sources. inside seconds, the data are obtainable for your Amazon kinesis Applications to browse and method from the stream.
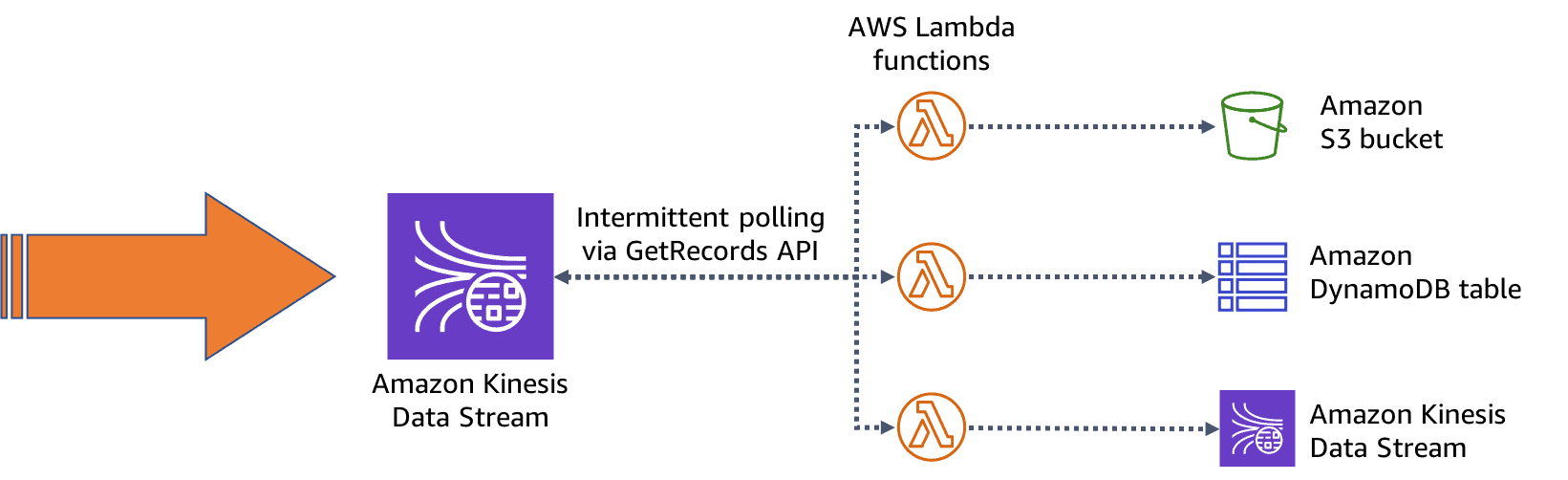 Source: AWS
Source: AWS
Q2: What is a shard?
A: Shard is that the base outturn unit of an Amazon Kinesis data stream. One shard provides a capability of 1MB/sec data input and 2MB/sec data output. One shard will support up to one thousand put records per second. you may specify the quantity of shards required once you produce a data stream.
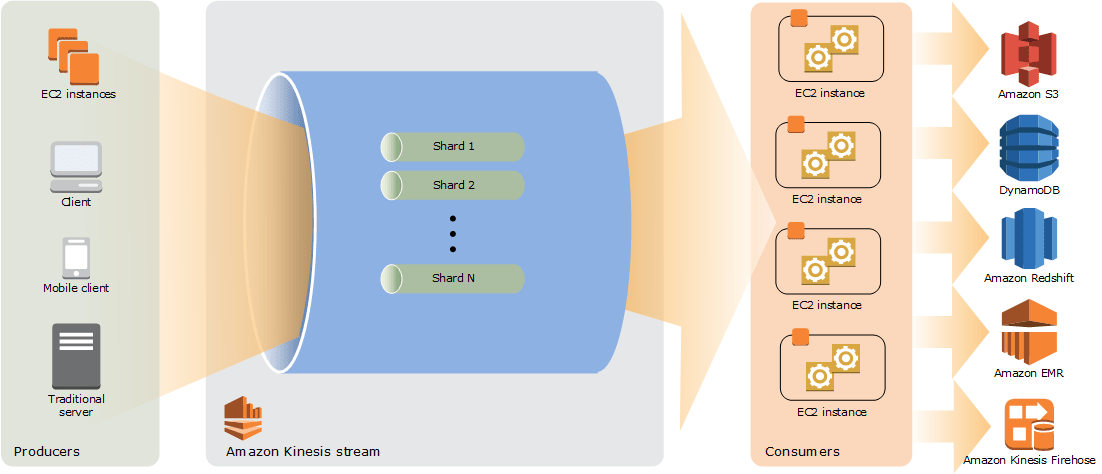 Source: AWS
Source: AWS
Q3: What is Amazon Kinesis Producer Library (KPL)?
A: Amazon Kinesis Producer Library (KPL) is a straightforward to use and extremely configurable library that helps data information into an Amazon Kinesis data stream. KPL presents a straightforward, asynchronous, and reliable interface that permits you to quickly attain high producer outturn with nominal client resources.
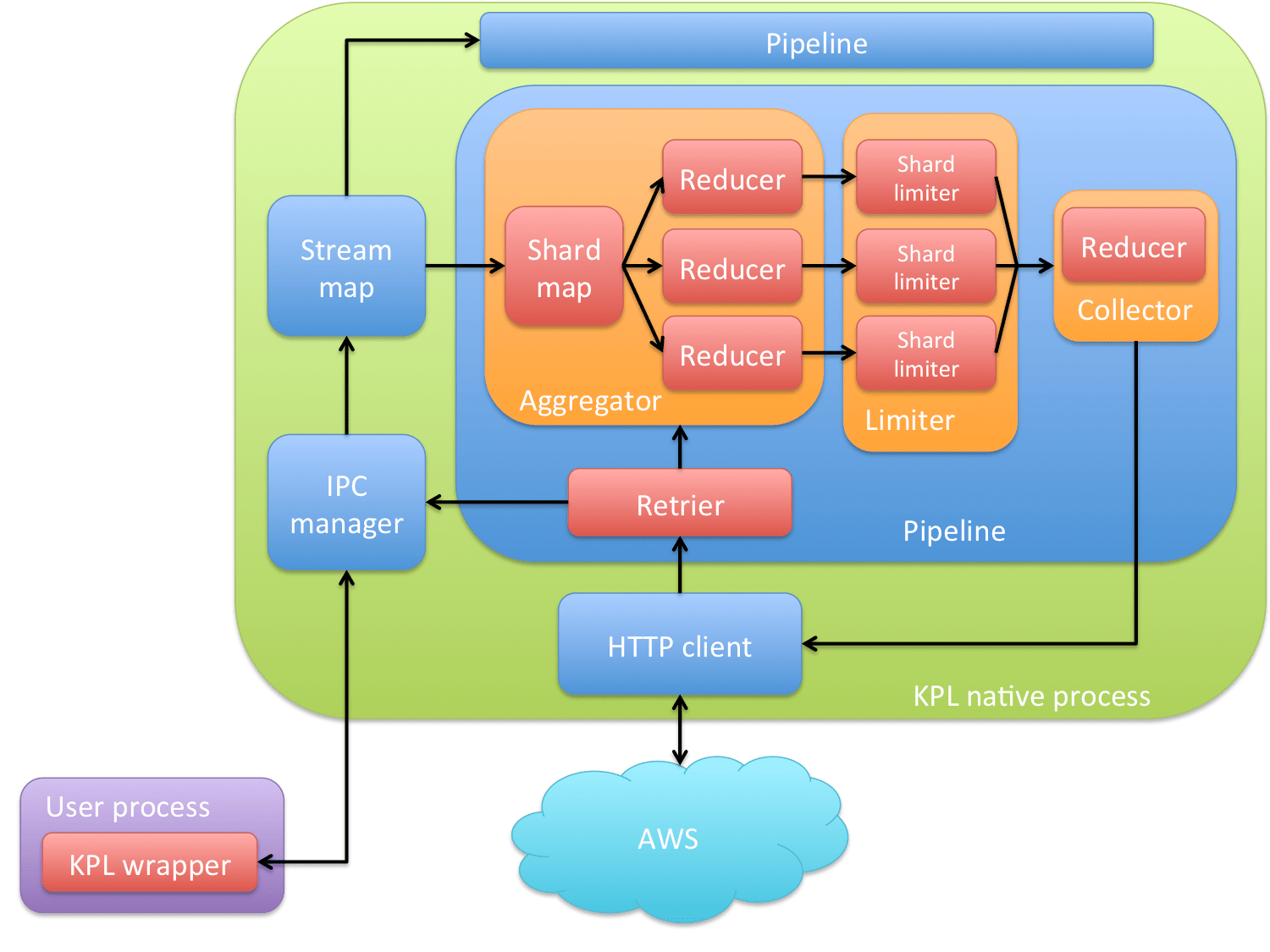 Source: AWS
Source: AWS
Q4: What is Amazon Kinesis Client Library (KCL)?
A: Amazon Kinesis Client Library (KCL) for Java, Python, Ruby, Node.js, .NET is a pre-built library that helps you easily build Amazon Kinesis Applications for reading and processing data from an Amazon Kinesis data stream.
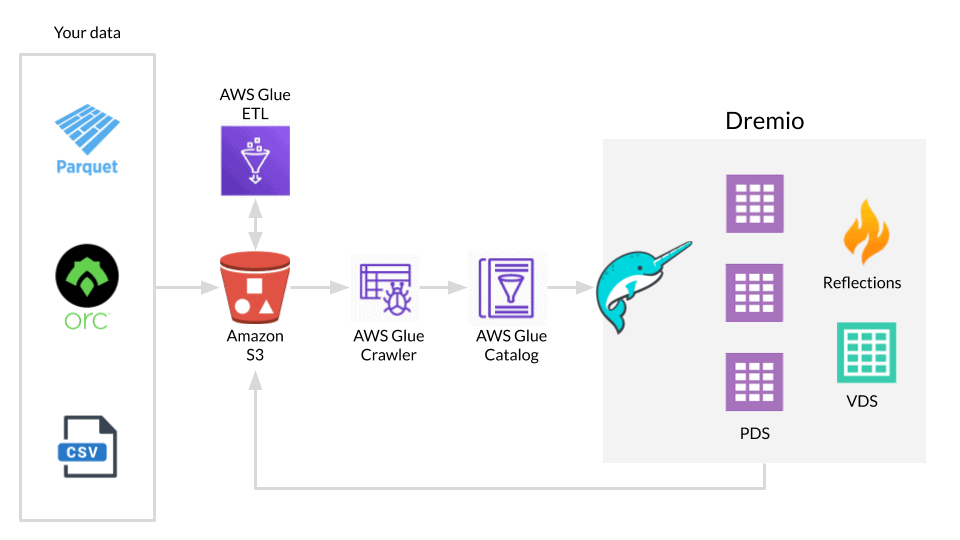
Q5: What is AWS Glue?
A: AWS Glue could be a serverless data integration service that creates it straightforward to find, prepare, and mix data for analytics, machine learning, and application development. AWS Glue provides all of the capabilities required for data integration, thus you’ll be able to begin analyzing your data and putting it to use in minutes rather than months.
 Source: AWS
Source: AWS
Q6: What are AWS Glue crawlers?
A: An AWS Glue crawler connects to a data store, progresses through a prioritized list of classifiers to extract the schema of your data and alternative statistics, and so populates the Glue Data Catalog with this information. Crawlers will run sporadically to find the provision of the latest data likewise as changes to existing data, as well as table definition changes. Crawlers automatically add new tables, new partitions to an existing table, and new versions of table definitions. you’ll be able to customise Glue crawlers to classify your own file varieties.
 Source: AWS
Source: AWS
Q7: Does AWS Glue have a no-code interface for visual ETL?
A: Yes. AWS Glue Studio offers a graphical interface for authoring Glue jobs to process your data. when you outline the flow of your data sources, transformations and targets within the visual interface, AWS Glue studio can generate Apache Spark code on your behalf.
Q8: Can I use my own code?
A: Yes. You can write your own code using AWS Glue’s ETL library, or write your own Scala or Python code and upload it to a Glue ETL job.
Q9: When should I use AWS Glue vs. Amazon EMR?
A: AWS Glue works on high of the Apache Spark environment to produce a scale-out execution environment for your data transformation jobs. AWS Glue infers, evolves, and monitors your ETL jobs to greatly change the method of making and maintaining jobs. Amazon EMR provides you with direct access to your Hadoop environment, affording you lower-level access and larger flexibility in victimization tools on the far side Spark.
 Source: AWS
Source: AWS
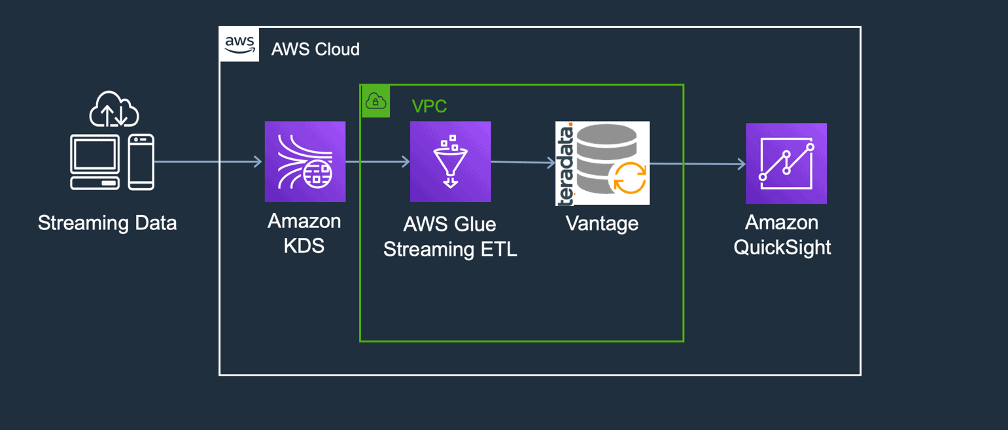
Q10: When should I use AWS Glue Streaming and when should I use Amazon Kinesis Data Analytics?
A: Each AWS Glue and Amazon kinesis data Analytics may be wont to process streaming data. AWS Glue has suggested after your use cases are primarily ETL and once you wish to run jobs on a serverless Apache Spark-based platform. Amazon kinesis data Analytics is suggested after your use cases are primarily analytics and once you wish to run jobs on a serverless Apache Flink-based platform
 Source: AWS
Source: AWS
Q11: What is Amazon Athena?
A: Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to setup or manage, and you can start analyzing data immediately. You don’t even need to load your data into Athena, it works directly with data stored in S3.
 Source: AWS
Source: AWS
Also Read: Our blog post on Amazon Rekognition. Click here
>Data Analysis in AWS
Data Analytics refers to the techniques used to analyze data to enhance productivity and business gain. Data is extracted from numerous sources and is cleansed and classified to investigate numerous behavioural patterns.

The techniques and therefore the tools used vary consistent with the organization or individual
Q12: What is Amazon QuickSight?
A: Amazon QuickSight could be rapid, easy-to-use, cloud-powered business analytics service that creates it simple for all staff among a corporation to create visualizations, performs ad-hoc analysis, and quickly get business insights from their data, anytime, on any device. QuickSight allows organizations to scale their business analytics capabilities to many thousands of users and delivers quick and responsive question performance by employing a strong in-memory engine (SPICE).
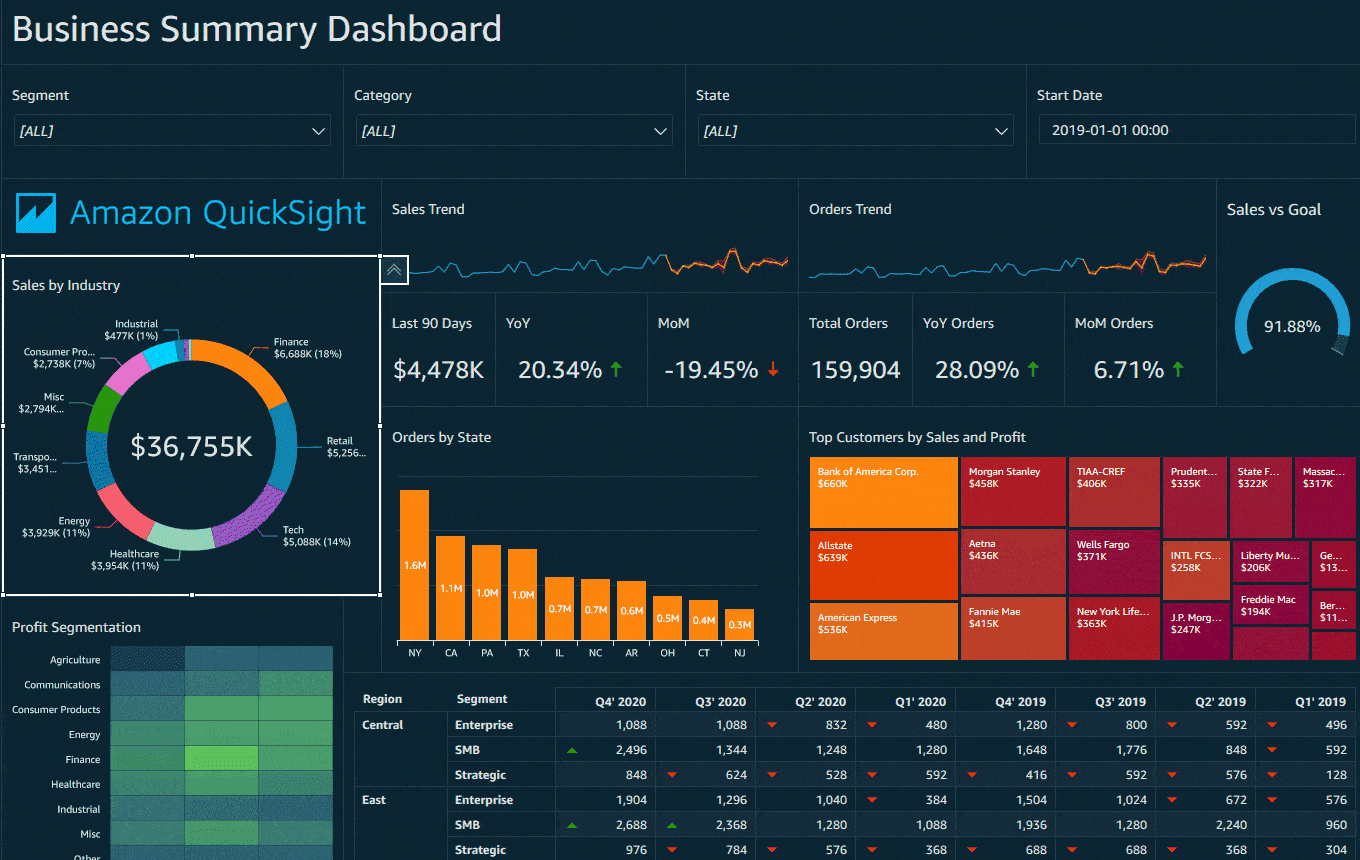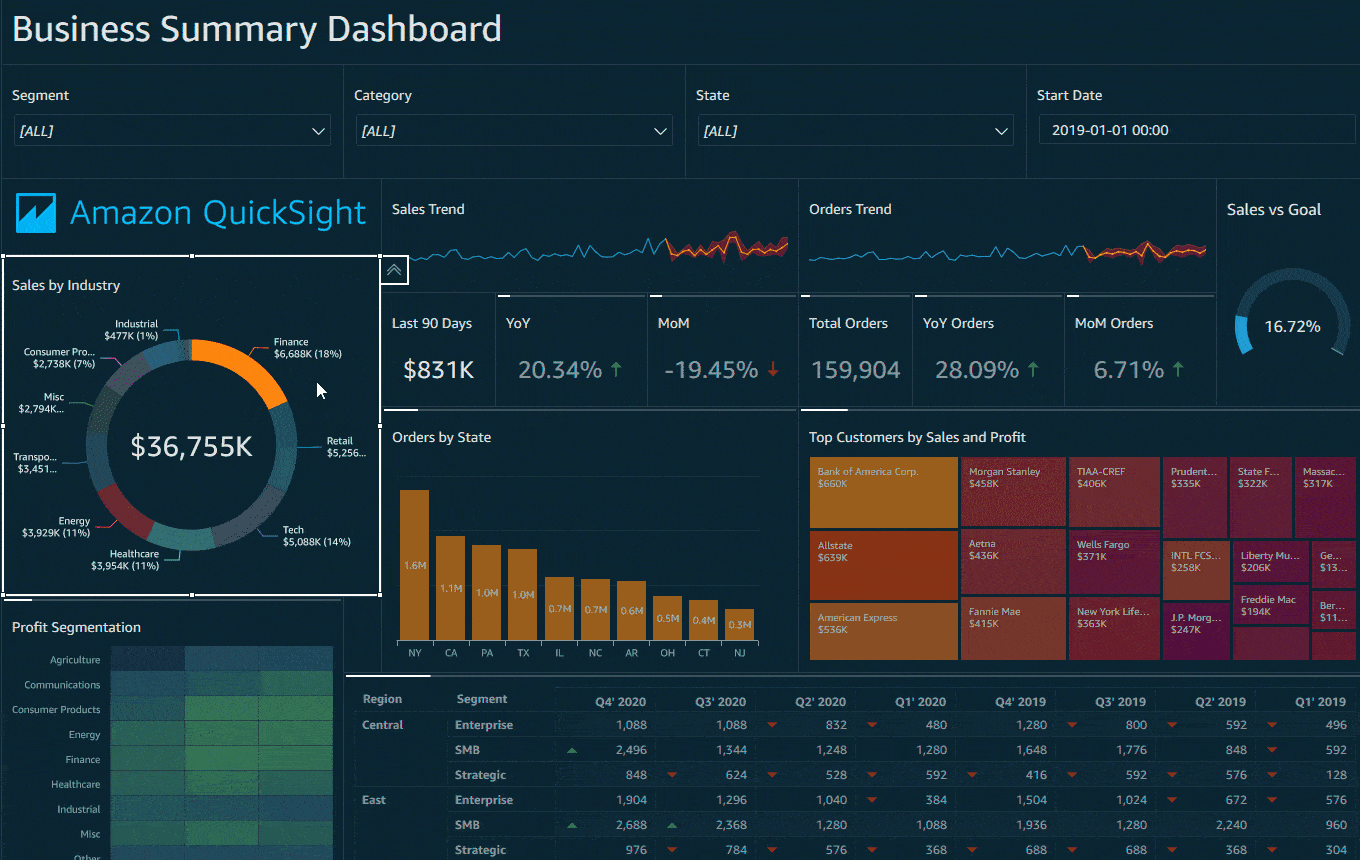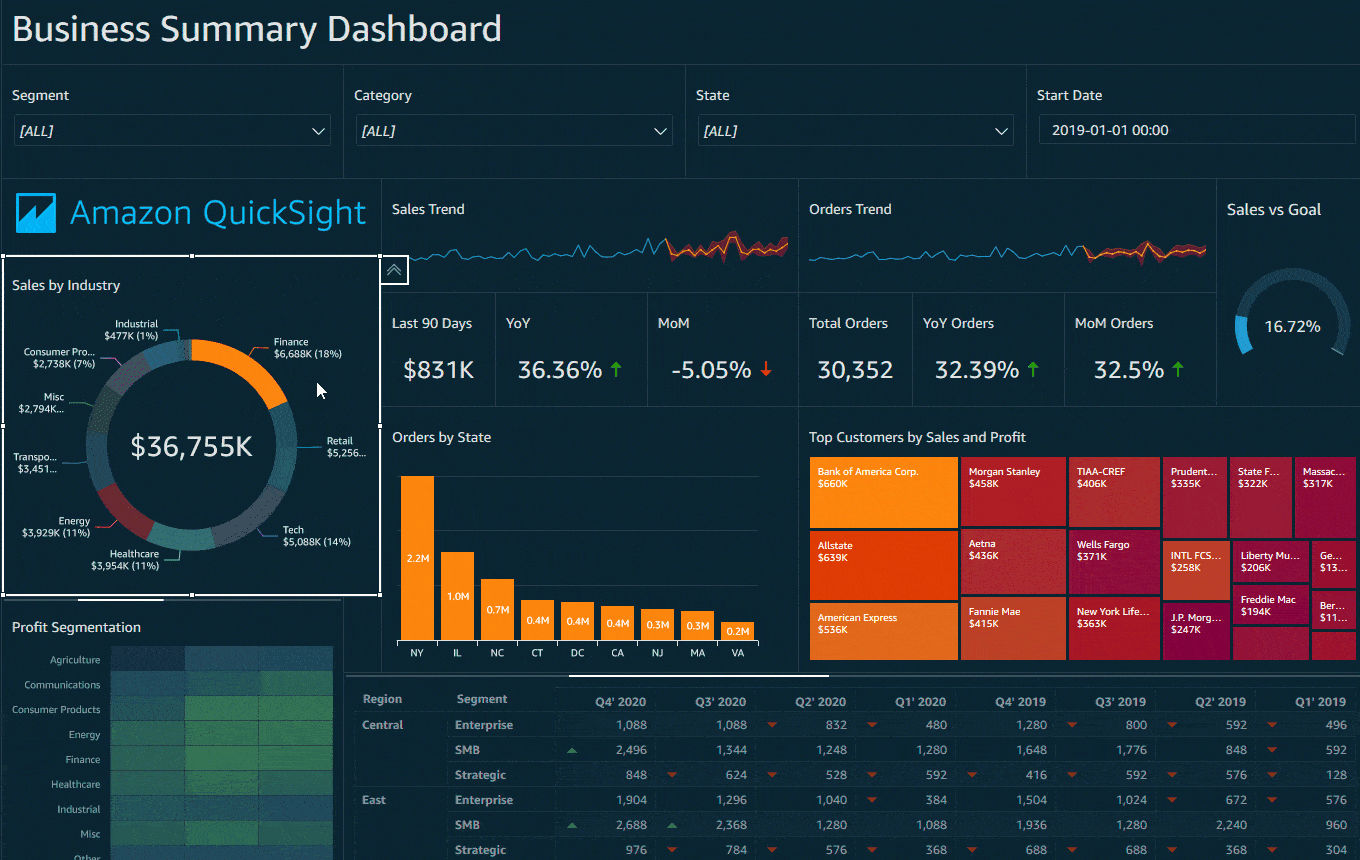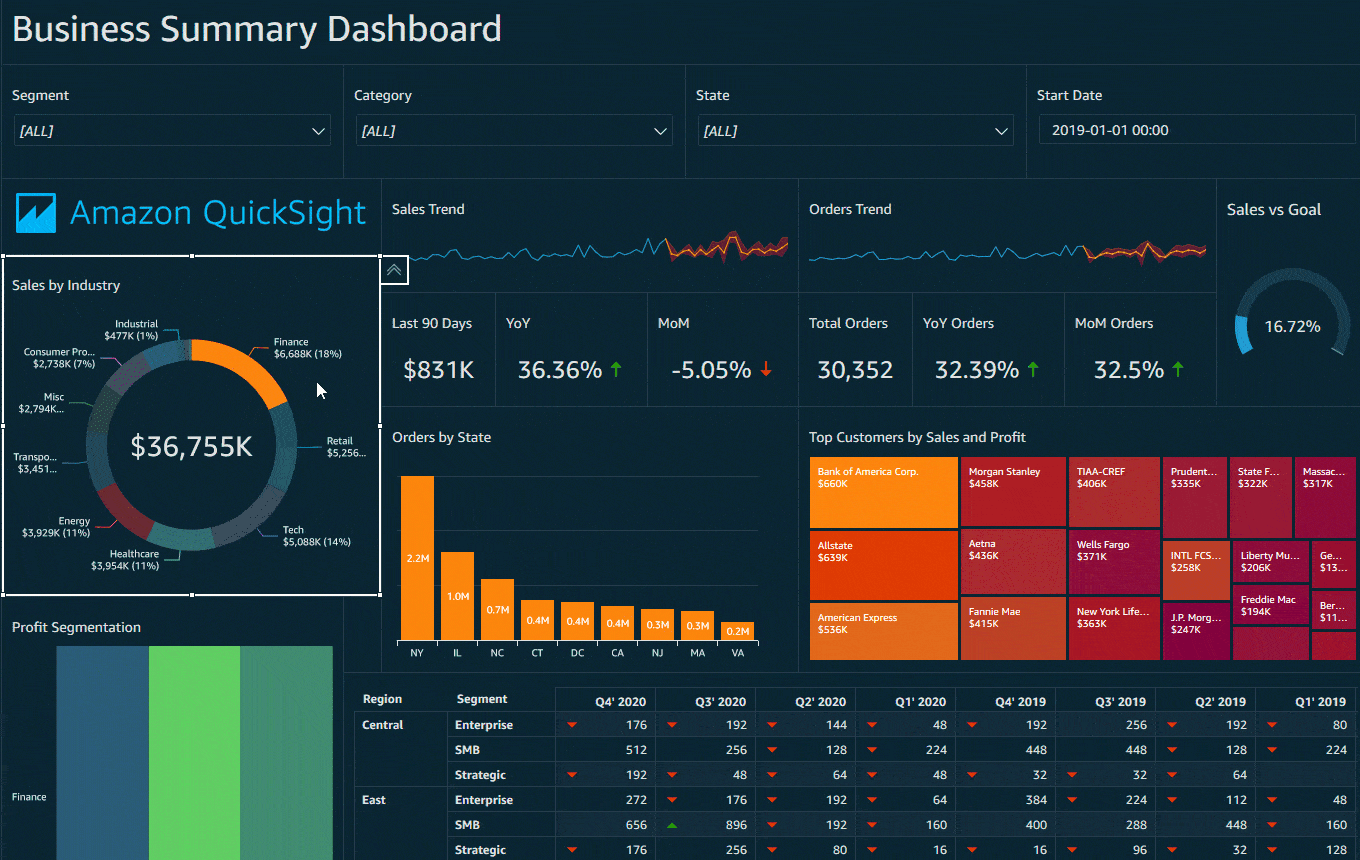 Source: AWS
Source: AWS
Q13: What is SPICE?
A: Amazon QuickSight is built with “SPICE” – a Super-fast, Parallel, In-memory Calculation Engine. BuiBuilt from the bottom up for the cloud, SPICE uses a mixture of columnar storage, in-memory technologies enabled through the most recent hardware innovations and machine code generation to run interactive queries on massive datasets and obtain rapid responses
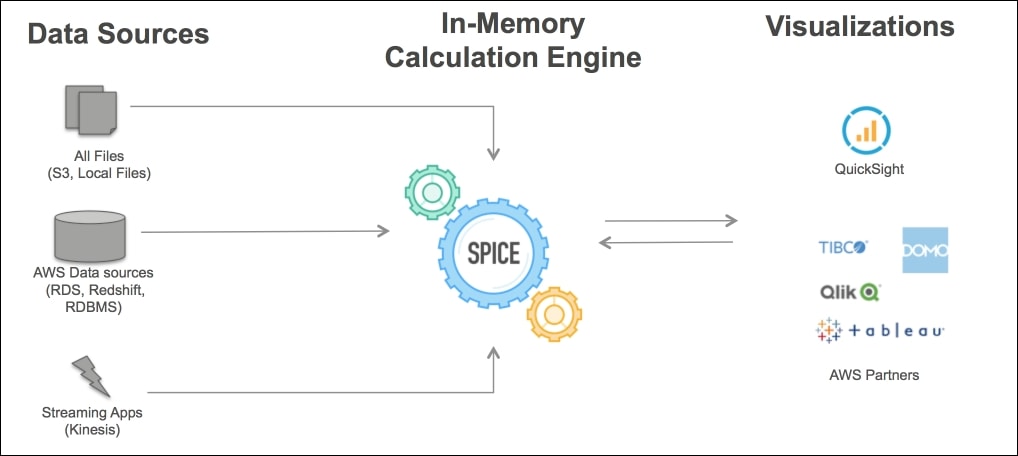 Amazon: AWS
Amazon: AWS
Q14: What types of visualizations are supported in Amazon QuickSight?
A: Amazon QuickSight supports assorted visualizations that facilitate different analytical approaches:
| Comparison and distribution |
|
| Changes over time |
|
| Aggregation |
|
| Correlation |
|
| Tabular |
|
Q15: What is Amazon EMR?
A: Amazon EMR could be an internet service that allows businesses, researchers, data analysts, and developers to simply and cost-effectively huge amounts of data. It utilizes a hosted Hadoop framework running on the web-scale infrastructure of Amazon Elastic compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3)
 Amazon: AWS
Amazon: AWS
Q16: What is Amazon CloudSearch?
A: Amazon CloudSearch is a fully managed service in the AWS Cloud that makes it easy to set up, manage, and scale a search solution for your website or application

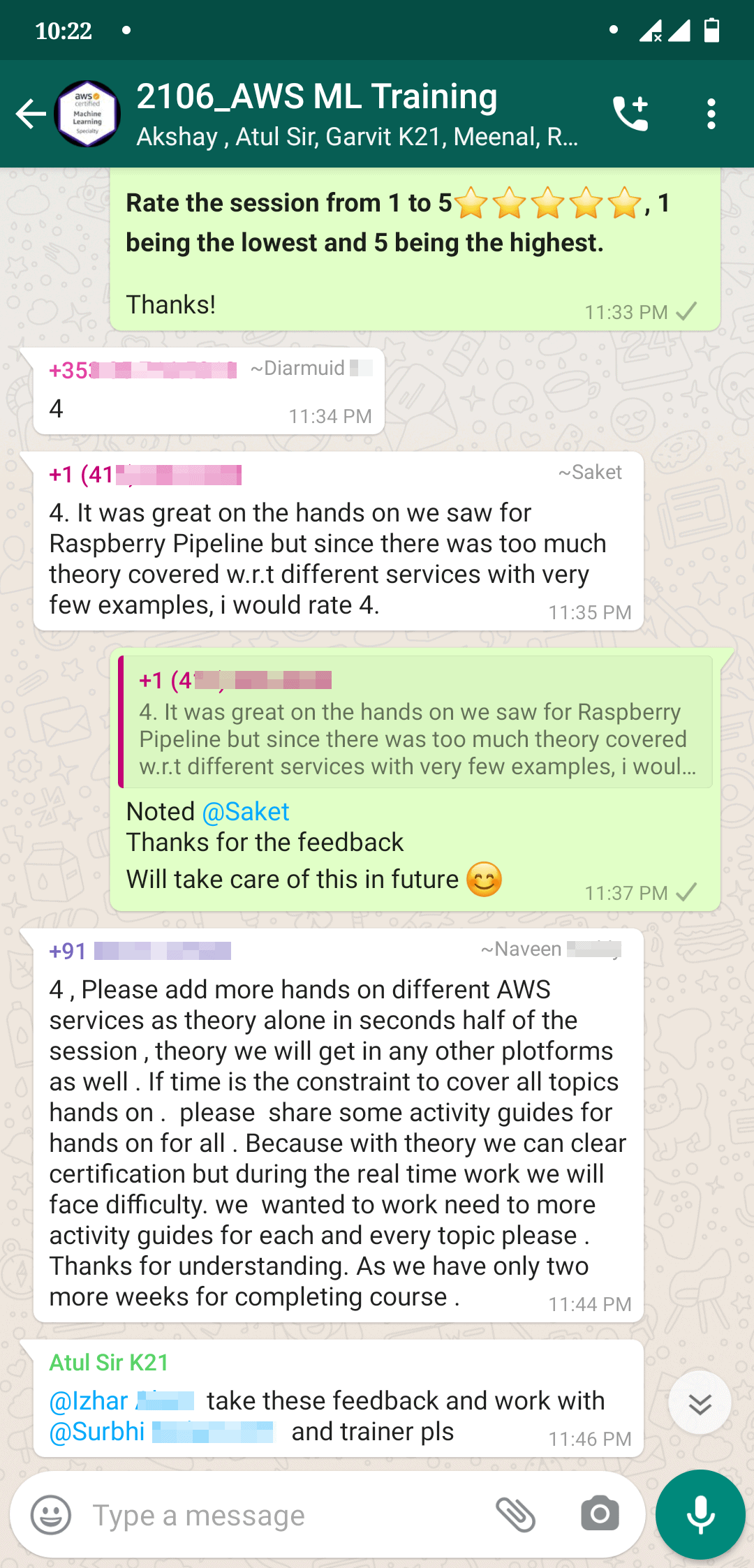
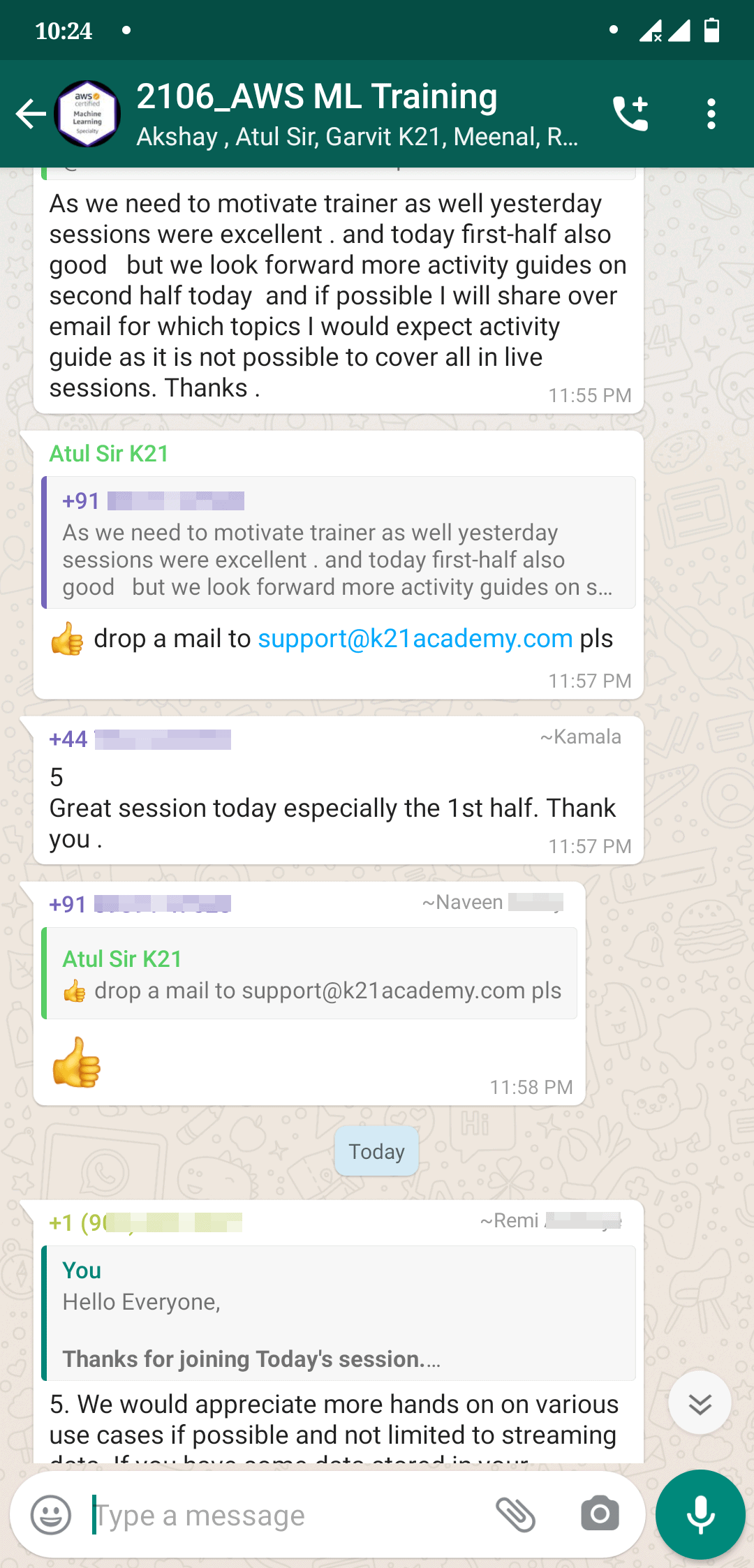
Feedback Received…
From our AWS-ML Day 5 & day 6 session, we received some good feedback from our trainees who had attended the session, so here is a sneak peek of it.
To know more about AWS-ML certification and whether it is the right certification for you, read our blog on AWS Certified Machine Learning – Specialty[MLS-C01]: Everything you must know
Quiz Time (Sample Exam Questions)!
With our AWS Certified Machine Learning – Specialty training program, we cover 150+ sample exam questions to help you prepare for the certification [MLS-C01].
Check out one of the questions and see if you can crack this…
Ques: A video streaming company is looking to create a personalized experience for its customer on its platform. The company wants to provide recommended videos to stream based on what other similar users watched previously. To the end, it is collecting its platform’s clickstream data using an ETL pipeline and storing the logs and syslogs in Amazon S3.
What kind of algorithm should the company use to create the simplest solution in this situation?
A) Reinforcement learning
B) Classification
C) Recommender system
D) Regression
Comment with your answer & we will tell you if you are correct or not!!
Related/References
- AWS Certified Machine Learning Specialty: All You Need To Know
- AWS Certified Machine Learning – Specialty: Step-by-Step Hands-On
- Exploratory Data Analysis With AWS Machine Learning
- Data Engineering With AWS Machine Learning
- [MLS-C01] AWS Certified Machine Learning – Specialty QnA Day 1 & 2 Live Session Review
Next Task For You
If you are also interested and want to more about the AWS certified Machine Learning Specialist then join the Waitlist.

Leave a Reply