![]()
This blog will tell you everything you need to know to do data engineering with AWS machine learning successfully. By the end of this blog, you’ll understand completely how to perform Data Engineering with AWS Machine Learning.
This blog post cover:
- Important Characteristics to Consider in A ML Solution
- Data Storage Options for Machine Learning On AWS
- Database Options for Machine Learning On AWS
- Streaming Data Ingestion Solutions on AWS for Machine Learning
- AWS Data Pipeline
- Data Transformation Overview on AWS for Machine Learning
Important Characteristics To Consider In A ML Solution
1) Data Characteristics
Data is mainly divided into three categories i.e. structured, semi-structured and unstructured data. Data characteristics will help you choose which AWS service to use as a data repository.
Structured data have a pre-defined schema. There’re relationships between tables and it supports complex querying. Amazon Relational Database Service, or RDS, offers support for Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle, and SQL Server database engines that makes it easier to set up, operate, and scale a relational database in the AWS Cloud.
Semi-structured data holds partially structured data such as JSON and XML. Databases that support this type of data include key values AWS database is like DynamoDB and the document database is like MariaDB. Unstructured data has no schema at all. It consists of heterogeneous data types and it holds any type of object.
Note : Do Check Our Blog Post on Modeling With AWS Machine Learning.

2) Batch And Stream Processing Characteristics
Batch and stream processing characteristics help you define what AWS ingestion and processing services to use.
Batch processing has the following characteristics:
- The data scope is limited to querying or processing over all or most of the data in the dataset.
- Data size is in the form of large batches with data performance having latency in minutes to hours and the analyses are complex. Eg: OLTP Online transaction processing.
Do Check : Our Blog On Amazon Comprehend.
Stream processing has the following characteristics:
- Stream processing is a result of dealing with data, increased volume, and velocity.
- It produces the continuous transfer of data rolling in over a small time period at a steady high-speed rate.
- Queries are done on just the most recent data in the form of individual records or micro-batches consisting of a few records.
- Performance has latencies in the order of seconds to milliseconds and analyses are simple response functions, aggregates, and rolling metrics.
Also Read : What is aws database migration service.
3) Application Characteristics
Application characteristics help you define and refine which AWS storage service to use. Modern distributed cloud apps have new and differing requirements. Traditional apps have hundreds to thousands of users, while cloud apps have one million-plus users. Data volume for traditional apps is in the gigabyte to the terabyte range. where for cloud apps, the volume range is from terabytes to petabytes, to exabytes. The locality of traditional apps is usually in corporate headquarters, whereas for cloud apps, the locality is literally global. Traditional apps can only scale up, whereas cloud apps need to scale up and down and in and out. Traditional apps performance is typically measured in seconds, whereas for cloud apps, the performance is milliseconds two microseconds.
Do Check : Our Blog Post On Amazon SageMaker.
Data Storage Options For Machine Learning On AWS
In this section, you’ll learn how to choose from a variety of data stores and database is available on AWS to fit the characteristics of your goal to choose the right AWS service for different data ingestion scenarios and how to choose the right AWS service for transformation.
Do Read : Our Blog Post on Deep Learning On AWS , For More Information.
1) Amazon S3
Amazon S3 is value for machine learning is in S3 data Lakes. S3 Data Lakes is a single, centralized, secure, and durable platform combining storage data, governance analytics, and AI that allows you to ingest and store structured, semi-structured, and unstructured data and transform these raw data assets in a just in time manner. You simply query the data in S3 Amazon Machine Learning uses Amazon S3 as the primary repository for input files for training and evaluating models for input files to generate batch predictions, and when you generate batch predictions by using your ML models.
Also Read : Our Blog Post On Amazon Rekognition.
2) Amazon EFS
Amazon EFS provides the ease of use, scale, performance, and consistency needed for machine learning and big Data Analytics workloads. Amazon EFS is designed to provide massively parallel shared access to thousands of Amazon EC2 instances enabling your applications to achieve high levels of aggregate throughput and IOPS with consistent low Latencies.
Do Check : Our Blog Post On “AWS Certified Machine Learning Specialty“.
3) Amazon EBS
At Reinvent 2019, it was announced that if you’re running Linux on EC2, you can take advantage of the new multi attach capability for Amazon EBS. Each EBS volume of provisioned IOPS I01 can be attached to a max of 16 EC2 instances in a single availability zone, and each nitro-based EC2 instance can support the attachment of multiple multi attach EBS volumes.
Do Read : Our Blog On Amazon Lex.
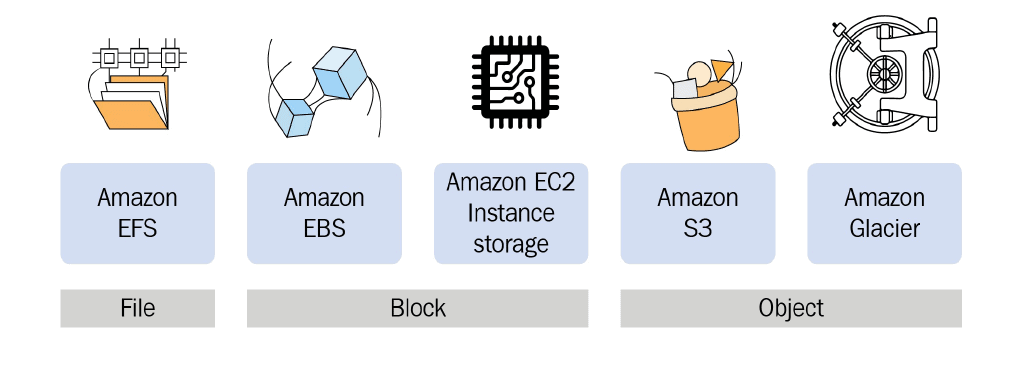
To know more about Amazon S3 Bucket and Storage Classes click here.
Database Options For Machine Learning On AWS
In this section, you’ll learn how to choose from a variety of AWS databases is in a machine learning scenario.
1) Amazon Relational Database Service (RDS) For AWS ML
Amazon RDS offers a fully managed, scalable relational database with support for six database engines, including Amazon Aurora, PostgreSQL, My SQL, Maria DB, Oracle, and SQL Server. It’s a relational database for OLTP processing, where data is stored in rows and you must provision the servers before use.
2) Amazon Aurora For AWS ML
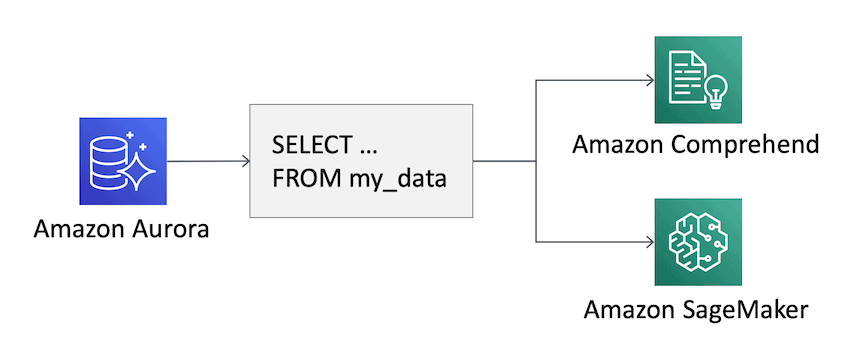
Amazon Aurora is a MySQL and PostgreSQL compatible relational database built for the cloud. Amazon Aurora has the performance and availability of commercial-grade database is at 1/10 the cost.
Amazon Aurora is natively integrated with two AWS Machine Learning services, Amazon Sage Maker, the service that provides the ability to build, train and deploy custom machine learning models quickly and Amazon Comprehend a natural language processing service that uses machine learning to find insights into the text.
Also Read : What is AWS Fargate?
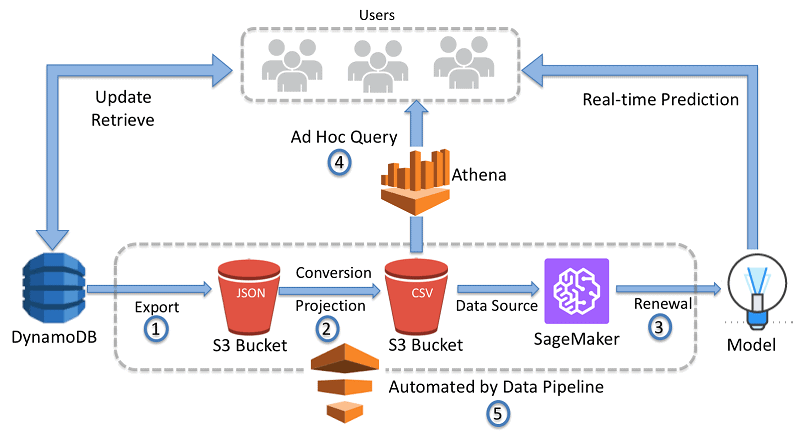
3) Amazon DynamoDB For AWS ML
Amazon DynamoDB is a serverless non-relational key-value database that delivers single-digit millisecond performance at any scale. It’s also a wide column and document database. It can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second.
To know more about AWS Database Services, click here.
Streaming Data Ingestion Solutions On AWS For Machine Learning
In this part, you’ll learn about the Amazon kinesis family of services that provide streaming data ingestion and processing on AWS. So, you can get timely insights and react quickly to new information. Kinesis is an AWS-managed alternative to Apache Kafka.
1) Amazon Kinesis Data Streams
Streams are divided into shards, which is the base input unit. They must be provisioned in advance. Thus, you need to implement capacity planning. Each shard is just data up to one mega second and processes data up to 1000 terabytes per second. Data retention is 24 hours by default but can go up to seven days. You can reprocess or replay the data during this time. Multiple applications can consume the same stream at their own speed because of data retention. This is the real beauty of Kinesis data streams, fast records Small size. Once data is inserted into Kinesis data streams. It can’t be deleted.
2) Amazon Kinesis Data Firehose
Amazon Kinesis Data Firehose is an ingestion system and is the easiest way to load streaming data into Redshift, S3, Elasticsearch service, and Splunk. It’s fully managed, and it automatically scales up and down to handle gigabytes per second or more of input data and maintains a data latency at levels you specify for the stream. It’s considered near real-time because you can’t have a buffer interval of fewer than 60 seconds.
3) Amazon Kinesis Data Analytics
Kinesis Data Analytics has built-in SQL functions to filter, aggregate, and transform streaming data with sub-second latencies, enabling you to analyze and respond to incoming data and streaming events in real-time. You can then send the process data to a variety of analytics tools so you can respond to streaming data in real-time and get real-time insights.
4) Amazon Kinesis Video Streams
Amazon Kinesis video streams provide SDK that makes it easy for devices to securely stream media to AWS for playback, storage, analytics, machine learning, and other processing. It automatically provisions and elastically scales all the infrastructure needed in just streaming video data from millions of devices such as security cameras, body-worn cameras, AWS DeepLens, and more. There’s one producer for each video stream. It durably stores in crips and indexes video data in your streams. 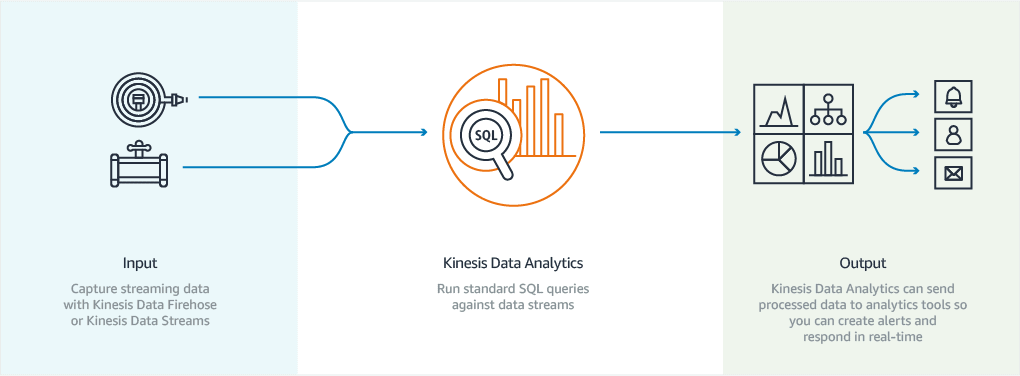
To know more about Amazon Kinesis Services, click here.
AWS Data Pipeline
The AWS data pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services as well as on-premises. Data sources at specified intervals. Compute sources include EC2 and EMR. You can access your data where it’s stored, transform and process it at scale and efficiently transfer the results to AWS services such as Amazon S3, Amazon RDS, Amazon Dynamodb, and Amazon EMR. Transformation is done on EC2 instances.
AWS data pipeline offers an on-demand scheduled type, which gives the option for a pipeline to be run on pipeline activation. The pipeline is run one time in response to an activation request. It also allows you to schedule recurring pipelines.
Data Transformation
1) Using Apache Spark On Amazon EMR
Apache Spark is a distributed unified analytics engine for large-scale processing and complex data wrangling. EMR Features a performance-optimized runtime environment for Apache Spark that’s over three times faster than a standard spark. Computation is performed over potentially thousands of compute nodes. Spark uses a directed acyclic graph or DAG execution engine to create efficient query plans for ETL. It stores input-output and intermediate data in memory as resilient data frames boosting the performance of iterative or interactive workloads.
2) Using Serverless AWS Glue And Serverless Amazon Athena
AWS glue solves the business problems that come with the need for analyzing heterogeneous data types, which in the past was laborious and very time-consuming and takes up a good 80% or more of a data engineer’s time. Glue provides one centralized location for literally all your company data, no matter where in the world. The data physically resides thereby solving the common business problem of globally scattered data silos, glue crawlers, can see can data in all kinds of repositories. Classify it, extract schema information from it and store the metadata automatically in the glue data catalog. From there, it can be used to guide ETL operations and be used in many AWS, ML, and analytic services.
The AWS Glue job system provides the managed infrastructure to orchestrate your ETL workflow. You can create jobs in the glue that automate the scripts you use to extract, transform and transfer data to different locations.
Athena is serverless. There’s no infrastructure to manage whatsoever. Athena scales automatically giving fast results even with large data sets and complex queries, Athena executes queries in parallel, so results are returned in seconds. Athena can do query encrypted data in S3 and right encrypted data back to another S3 bucket. Athena is integrated with the AWS Glue data catalog to optimize query performance and reduce costs.
Related References
- AWS Certified Machine Learning Specialty: All You Need To Know
- Introduction To Amazon SageMaker Built-in Algorithms
- Amazon Rekognition | Computer Vision On AWS
- AWS Database Services – Amazon RDS, Aurora, DynamoDB, ElastiCache
- Amazon Kinesis Overview, Features And Benefits
Next Task For You
If you are also interested and want to more about the AWS certified Machine Learning Specialist then join the Waitlist.


Leave a Reply